Grounding, Bounding Boxes, and Visual Citations
> **Working claim:** An extracted value or visual claim that cannot be pointed back to a specific region of a source, a pixel box on a page, an audio offset, a video frame, is unverifiable and therefore unsafe to act on.

Working claim: An extracted value or visual claim that cannot be pointed back to a specific region of a source, a pixel box on a page, an audio offset, a video frame, is unverifiable and therefore unsafe to act on. Grounding is not a UI nicety for showing users where an answer came from; it is the mechanism that makes verification, human review, and audit possible at all.
The claim you cannot point at
A medical-records system extracted, from a scanned referral, "patient is allergic to penicillin, " and surfaced it as a structured allergy flag. A clinician, reviewing, asked the obvious question: where does it say that? The system could not answer. It had produced the claim from a whole-page image sent to a vision-language model, and the model's output was free text with no tie to any region of the page. The clinician had to read the entire two-page referral to find, or fail to find, the supporting statement. In this case the statement was there, in a crossed-out "no known allergies" line that had been amended by hand to add penicillin; the model had read the amendment correctly but could just as easily have hallucinated it, and *the system had no way to tell the difference. * A claim you cannot point at is a claim you cannot check, and a claim you cannot check is, for any serious purpose, not evidence: the exact rule from Chapter 3, now made concrete as a spatial requirement.
Grounding is the property that every claim carries a pointer to the region of the source it came from. For a document: the page number and a bounding box. For audio: a start and end offset in milliseconds. For video: a frame index or timestamp range, plus a bounding box within the frame. With grounding, the clinician's question takes one second to answer: the system highlights the amended line, and the clinician confirms or rejects it at a glance. Without grounding, every claim is an assertion that must be re-derived from scratch to be trusted, which defeats the entire point of automation. This chapter is about how grounding is produced, represented, verified, and used, and why a system without it has no real verification layer regardless of how good its model is.
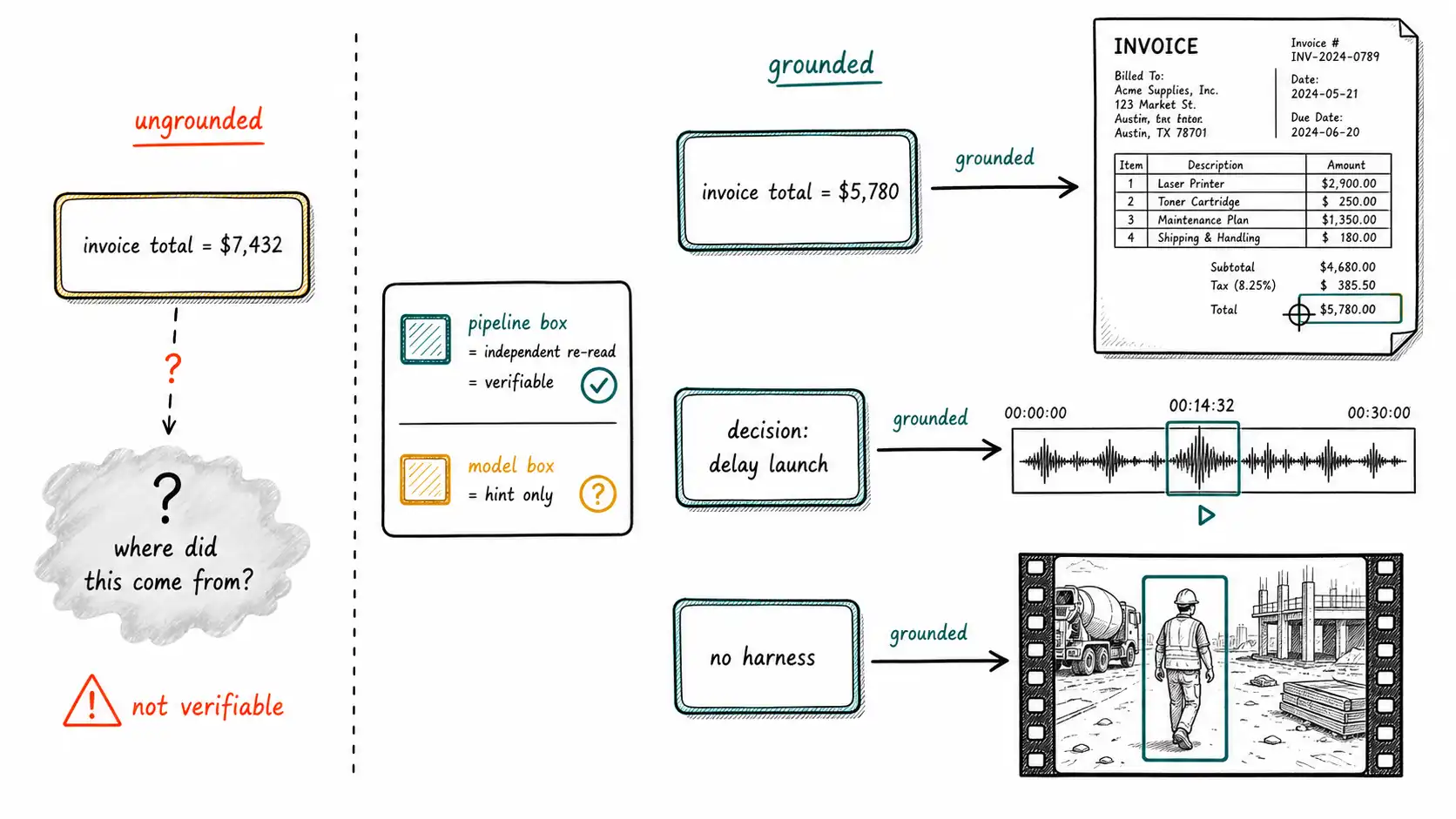
Two ways to get a bounding box, and why one is trustworthy
There are two fundamentally different ways a claim acquires a bounding box, and they have very different reliability.
Model-emitted boxes. Some vision-language models can be asked to return coordinates: "what is the total, and where is it?" The model emits a box. This is convenient and sometimes good, but it is the same model reasoning about the same compressed image, so the box is a claim of the same epistemic status as the value, it can be confidently wrong, pointing at empty space or at the subtotal. A model-emitted box is better than nothing (it gives a human somewhere to look) but it is not independent verification, for the same reason the model cannot be its own witness (Chapter 3).
Pipeline-derived boxes. The layout-aware OCR pipeline of Chapters 6-7 already knows the bounding box of every text span and table cell, because detecting those boxes is how OCR works. When extraction locates a field by its label and position, the box comes from the OCR geometry, independently of the model. This box is trustworthy in a way the model-emitted box is not: it is derived from an independent reader, so cross-checking the model's value against the OCR text inside the pipeline-derived box is genuine verification. The total the model claimed is checked against the characters the OCR engine read at the location the layout engine identified as the total field. Three independent processes agreeing is evidence; one model asserting both the value and its location is not. Flamingo's cross-attention grounding to visual features is the architectural precedent for why binding a claim to a source region is preferable to free-floating generation.
The design rule that follows: prefer pipeline-derived grounding for verification, and treat model-emitted grounding as a hint, not a proof. Where only model-emitted boxes are available (a pure-image input with no OCR structure), the box still buys you human-checkability, but the claim's disposition stays unverified until something independent confirms it.
The grounding record
Grounding has to be a typed, first-class part of every claim, not a comment or a side log. The record ties a claim to a source location precisely enough that both a human and a machine can re-inspect it.
from dataclasses import dataclass
@dataclass
class SourceRegion:
source_id: str # which file/recording (provenance root)
source_hash: str # exact bytes, so the region is reproducible
page: int | None = None # documents
bbox: tuple[float, float, float, float] | None = None # normalized x,y,w,h
audio_start_ms: int | None = None # audio/video
audio_end_ms: int | None = None
frame_index: int | None = None # video
box_origin: str = "pipeline" # "pipeline" (trustworthy) | "model" (hint)
@dataclass
class GroundedClaim:
field: str
value: str
region: SourceRegion
model_value: str | None = None # what the VLM said, if different
region_reread: str | None = None # independent re-read of the region
agrees: bool | None = None # do model_value and region_reread match?
def reverify(claim: GroundedClaim, doc) -> GroundedClaim:
"""Independent re-read of the grounded region, regardless of how we got here."""
if claim.region.bbox is not None and claim.region.page is not None:
page_img = doc.page_image(claim.region.page)
claim.region_reread = ocr_region(page_img, claim.region.bbox)
claim.agrees = normalize(claim.region_reread) == normalize(claim.value)
return claimThe box_origin field is the chapter's quiet insistence: the system records how it knows where the claim came from, because a pipeline box and a model box mean different things for trust. The reverify function is what makes the box useful for verification rather than just for display, it re-reads the exact region independently and records whether that re-read agrees with the claimed value. A GroundedClaim whose agrees is True, with a box_origin of pipeline, is about as close to evidence as a multimodal extraction gets; one whose agrees is None because there is no box is, by construction, unverified.
Visual citations: showing the work
Grounding pays off most visibly in the user experience, where it converts an opaque assertion into a checkable one. A visual citation is the rendering of a grounded claim back onto the source: the answer "invoice total is $5,780" displayed next to a thumbnail of the invoice with the total's bounding box highlighted; the meeting-assistant claim "the team decided to delay launch" with a play button that jumps audio to the 00:14:32 offset where it was said; the safety finding "worker not wearing a harness" with the specific frame and the bounding box around the worker.
Visual citations are not decoration. They change the economics and the safety of the whole system in three ways. They make human review fast: a reviewer confirms a highlighted box in a second instead of reading a page, which is what makes a human-in-the-loop design affordable at volume. They make user trust calibrated: a user shown the source can catch the system's error, turning users into a verification layer rather than passive recipients of confident claims. And they make the system auditable: when a wrong decision is investigated weeks later, the citation reconstructs exactly what region the system based its claim on, which is the difference between a debuggable incident and a mystery. The benchmarks gesture at this, DocVQA tasks are answerable by pointing at a page region, and MM-Vet's integrated tasks reward grounded reasoning, but the production value is operational: grounding is what makes a multimodal system reviewable by a human who is not the model.
Grounding across modalities, not just documents
Grounding generalizes cleanly, and the generalization is one of the book's unifying ideas. Every modality has a coordinate system that locates a claim in its source:
- Documents: page + bounding box. (Re-verifiable by re-OCRing the box.)
- Images: bounding box (+ image hash). (Re-verifiable by cropping and re-reading, or by an object detector.)
- Audio: start/end offset in milliseconds. (Re-verifiable by replaying the segment, or re-transcribing just that window.)
- Video: frame index/timestamp + bounding box within the frame. (Re-verifiable by re-sampling near that time.)
- Charts: the chart's region on the page + ideally the specific bar/point. (Re-verifiable against source data if available; ChartQA tasks require exactly this kind of region-level reasoning to score correctly.)
The unifying contract is the SourceRegion above, with the modality-appropriate fields populated. This is why the MODAL framework's A, Alignment question is a single question across modalities even though the coordinates differ: for every claim, what is its source region, and can that region be independently re-inspected? A meeting-assistant claim grounded to an audio offset is verified the same way an invoice total grounded to a bbox is, by an independent re-read of the located region, even though one re-read is a re-transcription and the other a re-OCR. The audio and video chapters that follow lean on exactly this: a transcript line carries its time offset so a claim can be replayed; a video finding carries its frame so it can be re-sampled. Grounding is the spine that runs through every modality, and the absence of it is the single clearest sign that a multimodal system has a perception layer but not a verification layer.
When grounding is hard: synthesis and aggregation
Honesty requires naming where grounding strains. Some claims are not located at a single region because they are syntheses over many: "the contract is favorable to the buyer, " "the meeting was tense, " "revenue trended down over the year." These do not have one bounding box; they have many supporting regions, or they are judgments not directly stated anywhere. The right response is not to fake a single box but to ground to the set of supporting regions, list the clauses, the audio segments, the data points that the synthesis rests on, so a reviewer can audit the basis even if no single region states the conclusion. And for genuine judgments with no textual support, the honest disposition is unverified (Chapter 3): the claim is presented as the system's assessment, with its supporting regions cited, not as an extracted fact. The GPT-4V system card's warnings about confident interpretation apply most to exactly these synthetic claims, which is why grounding-to-a-set, rather than pretending to grounding-to-a-point, is the disciplined way to keep even synthesis auditable.
The rule, stated as an invariant
The chapter reduces to an invariant you can enforce in code and in review: no claim leaves the system without a source region, and no claim is marked verified without an independent re-read of that region agreeing with it. A claim with no region is unverified by construction and cannot be auto-actioned. A claim with a model-emitted region is unverified until something independent confirms it. A claim with a pipeline-derived region whose independent re-read agrees is verified and may be auto-actioned within its stakes. This invariant is what turns the abstract motto, a vision answer is not evidence until it is verified, into a property a system either has or does not have, checkable by inspecting whether GroundedClaim. region is populated and whether agrees is True. The medical-records system that could not answer "where does it say that" failed this invariant; the fix was not a better model but the discipline of never emitting a claim without its region and never trusting a region without re-reading it. This chapter builds on OCR Is Not Document Understanding and the verification contract from earlier chapters.
Chapter summary
A claim that cannot be pointed back to a specific region of its source is unverifiable and unsafe to act on, which is why grounding, attaching a source region (page + bbox, audio offset, video frame) to every claim, is the mechanism that makes verification, human review, and audit possible rather than a UI nicety. Bounding boxes come two ways with very different trust: model-emitted boxes share the model's epistemic status and are hints only, while pipeline-derived boxes come from the independent OCR/layout geometry and enable genuine verification by re-reading the located region. Encode grounding as a first-class typed record (SourceRegion with box_origin, modality-appropriate coordinates, and a re-read field) and make reverify an independent re-read that records whether the region's content agrees with the claimed value. Visual citations, rendering a grounded claim back onto its source with a highlighted box, an audio play offset, or a film frame, change the economics and safety of the whole system by making human review fast, user trust calibrated, and incidents auditable. Grounding generalizes across modalities through one contract: every modality has coordinates that locate a claim, and the MODAL "Alignment" question is the same everywhere, what is the source region, and can it be independently re-inspected? Synthesis claims that span many regions should be grounded to the set of supporting regions rather than faking a single box, and genuine judgments stay unverified. The invariant: no claim leaves without a source region, and none is verified without an independent re-read agreeing, which is the abstract motto made into a checkable property. The next movement applies this grounding discipline to time-based media: Audio Is Not Text After Transcription.