Evaluation: Seeing Is Not Verifying
> **Working claim:** A single accuracy number on a multimodal system is almost always a lie of omission.

Working claim: A single accuracy number on a multimodal system is almost always a lie of omission. Perception and reasoning fail for different reasons and must be measured separately; an average over a benchmark hides the slice, one lighting condition, one accent, one document template, one camera angle, where the system quietly fails; and an LLM-as-judge inherits the same perceptual blind spots as the system it grades. Evaluation is where demos go to be disproven.
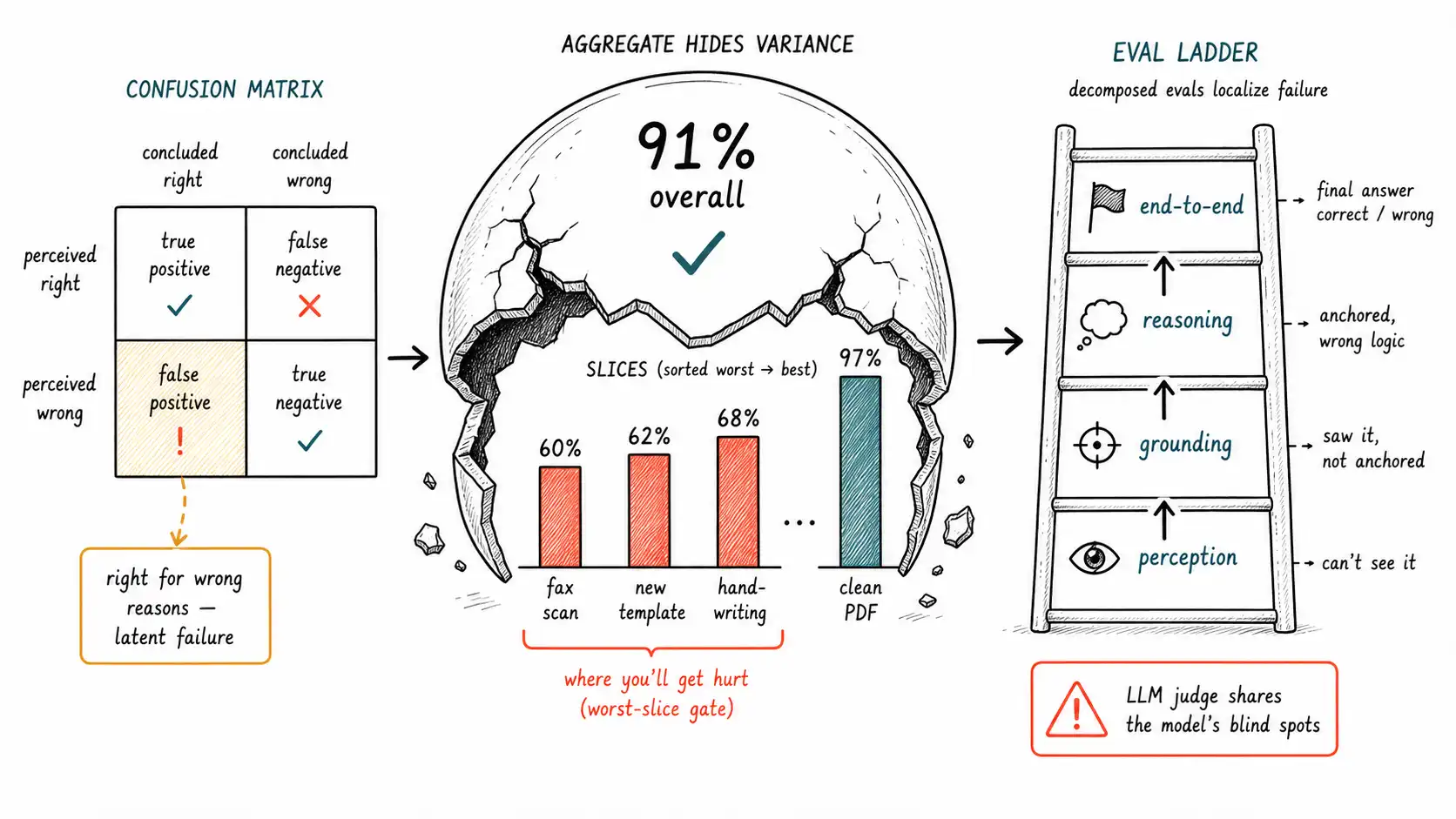
The 91% that meant nothing
A document-extraction team reported 91% accuracy on their internal eval set and got the green light to expand from one customer to ten. Within a month, two of the new customers were furious: the system was wrong far more than 9% of the time on their documents. Nothing had regressed. The 91% was a real number, measured honestly, on an eval set drawn almost entirely from the first customer's document templates. The new customers used different templates: different layouts, different table styles, one with handwriting, one with low-quality fax scans. On those slices the accuracy was closer to 60%. The average was 91% because the eval set's distribution did not match the production distribution, and the average had no way to tell anyone that the system was strong on templates it had seen and weak on templates it had not.
This is the central evaluation failure of multimodal systems, and it is worse than in text systems because multimodal inputs have more axes of variation that matter: lighting, resolution, device, angle, language, accent, noise, template, handwriting-vs-print. Each axis is a potential slice where performance diverges, and an aggregate number averages across all of them, presenting a confident summary that is true on average and dangerously false on the slices a new customer happens to occupy. The benchmark literature learned this lesson publicly: MMMU-Pro hardened MMMU specifically to remove the shortcuts that inflated averages, and scores dropped. Your internal 91% has the same fragility unless your eval set is built to expose it.
Perception and reasoning are different failures, measured differently
The first discipline is to stop measuring "accuracy" as one thing and measure perception and reasoning separately, because they fail for different reasons and a single number cannot tell you which is broken. Recall the three-layer decomposition from Chapter 1. A wrong answer can come from perception (the detail did not survive ingestion), from reasoning (the model perceived correctly but concluded wrongly), or from action/grounding (right conclusion, wrong attribution). These need different tests:
| Eval type | Question | Method | Catches |
|---|---|---|---|
| Perception eval | Did the system read/see the right thing? | Compare extracted value/transcript to ground truth at the source | OCR errors, missed details, transcription errors |
| Grounding eval | Is the claim tied to the correct region? | Compare predicted bbox/offset to ground-truth region (e. g. IoU) | Misattribution, wrong-region answers |
| Reasoning eval | Given correct perception, is the conclusion right? | Provide gold-perceived inputs, test the reasoning step | Arithmetic, aggregation, causality errors |
| End-to-end eval | Does the whole pipeline produce the right action? | Full pipeline on realistic inputs | Everything, but doesn't localize the failure |
The decoupling is the key move. If you only run end-to-end evals, a failure tells you the system is wrong but not why, so you cannot tell whether to fix ingestion, the model, or the grounding. By running a perception eval (does the OCR/transcript match ground truth?) and a reasoning eval (given perfect perception, does the model conclude correctly?) separately, you localize the failure to a layer with an owner and a fix. A system whose reasoning eval is 95% but whose end-to-end is 70% has a perception problem; a system whose perception eval is 98% but whose reasoning eval is 75% has a reasoning problem. The aggregate number hides this; the decomposed numbers reveal it.
The confusion matrix for perception vs reasoning
A compact way to see the decoupling is a 2×2: was perception correct, and was the conclusion correct?
| Conclusion correct | Conclusion wrong | |
|---|---|---|
| Perceived correctly | True success | Reasoning failure (fix: prompt, decomposition, tools) |
| Perceived wrongly | "Right for wrong reasons" (dangerous!) | Perception failure (fix: ingestion, crops, resolution) |
The bottom-left cell is the quiet killer: the system perceived the input wrongly but happened to produce the right answer anyway (e. g. read the chart bar as 42 instead of 47 but the question only asked "is it above 40"). These inflate end-to-end accuracy while masking a perception failure that will produce a wrong answer the moment the question gets harder. A system evaluated only end-to-end counts these as wins; a system evaluated with the matrix flags them as latent failures. This is why "seeing is not verifying" is the chapter title: a system can pass an end-to-end eval while perceiving wrongly, and only separate perception measurement reveals it.
Slice evaluation: the average is the enemy
The second discipline is to never report an average without its slices. Build the eval set to over-represent the conditions that vary in production, and report accuracy per slice, with the worst slice as a first-class metric.
-- Per-slice accuracy from a logged eval run. The MIN over slices is the
-- number that should gate a launch, not the overall AVG.
SELECT
slice_dimension,
slice_value,
COUNT(*) AS n,
AVG(CASE WHEN correct THEN 1.0 ELSE 0 END) AS accuracy
FROM eval_results
WHERE eval_run_id =:run
GROUP BY slice_dimension, slice_value
ORDER BY accuracy ASC; -- worst slices first: this is where you'll get hurt
-- The launch gate: worst meaningful slice, not the headline average.
SELECT MIN(accuracy) AS worst_slice_accuracy
FROM (
SELECT slice_value, AVG(CASE WHEN correct THEN 1.0 ELSE 0 END) AS accuracy
FROM eval_results WHERE eval_run_id =:run
GROUP BY slice_dimension, slice_value
HAVING COUNT(*) >= 30 -- only slices with enough samples to trust
) s;The slices to track depend on modality. For documents: template, language, scan quality, print-vs-handwriting. For images: lighting, device, angle, resolution. For audio: accent, noise level, language, number of speakers. For video: sampling-stressing short events, on-screen-text density. The document-extraction team's incident was a slice failure: had they reported per-template accuracy, the new customers' template slices (which they could have simulated) would have shown 60% before launch, not after. The discipline is cheap and the payoff is the difference between a launch decision and a launch incident. DocVQA and ChartQA report on diverse, messy inputs precisely to resist the single-number summary; your internal eval should do the same.
A golden dataset format that supports all of this
The eval set's structure determines what you can measure. A golden record for multimodal eval carries the input, the ground-truth answer, the ground-truth source region (for grounding eval), and the slice labels (for slice eval).
{
"case_id": "inv-2287",
"source_uri": "s3://eval/invoices/inv-2287.pdf",
"source_hash": "sha256:9f2c...",
"modality": "document",
"question": "What is the invoice total?",
"gold_answer": "5780.00",
"gold_region": { "page": 1, "bbox": [0.71, 0.83, 0.18, 0.04] },
"gold_perception": "5,780.00",
"slices": {
"template": "supplier_acme_v2",
"scan_quality": "fax_low",
"language": "en",
"handwriting": false
},
"stakes": "high"
}gold_region enables the grounding eval (does the predicted box overlap the truth?). gold_perception separate from gold_answer enables the perception-vs-reasoning split (for a chart, gold_perception might be the read values and gold_answer the computed total). slices enables the SQL above. stakes lets you weight failures by impact, a wrong high-stakes total matters more than a wrong low-stakes caption. Building the golden set this richly is more work than collecting input-answer pairs, and it is the work that turns "91% overall" into "98% reasoning, 90% perception, worst-template 60%, worst high-stakes slice 71%, " which is a sentence a launch decision can actually rest on.
LLM-as-judge inherits the blind spot
A tempting shortcut for scaling multimodal eval is to use a strong vision-language model as the judge, show it the input, the answer, and ask "is this correct?" This works for some things and fails for exactly the things that matter, and the failure mode is specific: *the judge has the same perceptual blind spots as the system under test. * If the answer is wrong because a chart value was misread as 42 instead of 47, a VLM judge looking at the same low-resolution chart may also read it as 42 and rate the wrong answer correct. The judge cannot catch a perception error it would also make. This is the eval-layer version of Chapter 3's "the model cannot be its own witness, " and it disqualifies VLM-as-judge for perception evals specifically.
The disciplined uses of LLM-as-judge are: grading reasoning given gold-perceived inputs (where the judge is not asked to perceive, only to assess logic against provided ground truth); grading format and helpfulness (subjective qualities with no perceptual ground truth); and triage (flagging likely-wrong answers for human review, where false positives are cheap). For perception ground truth, the judge must be something independent of the model's perception, a structured extraction, an exact-match against gold, a human, or a cross-check against source data. MM-Vet itself uses an LLM-based evaluation for open-ended outputs but is built around carefully constructed ground truth; the lesson is that LLM judging is a tool for assessing against ground truth you trust, not a substitute for having ground truth at all.
Safety and high-stakes interpretation
The chapter closes on the slice that is not about accuracy but about harm. Some multimodal inputs are high-stakes in a way that changes the eval requirement: medical images, safety inspections, content that may be unsafe (violence, CSAM, self-harm), images of identifiable people. For these, two additional eval dimensions apply. Calibrated abstention: does the system correctly refuse or escalate when it is uncertain or when the input is out of its safe envelope, rather than producing a confident reading? An eval set must include cases the system should decline, and measure whether it does. Harm-weighted error: a false negative on a safety inspection (missing a hazard) is not symmetric with a false positive (flagging a non-hazard), and the eval must weight them by their real consequences rather than counting both as "one error." The GPT-4V system card documents extensive safety evaluation precisely because high-stakes image interpretation is where confident errors do the most damage, and where "it described the image" is the least adequate measure of whether the system should be trusted. Evaluation is not only about whether the system is right; for high-stakes modalities it is about whether the system knows when to stop, which the next two chapters operationalize.
Chapter summary
A single accuracy number on a multimodal system is a lie of omission: the document team's honest 91% was measured on one customer's templates and collapsed to 60% on new ones, because multimodal inputs vary along more axes that matter (lighting, device, angle, language, accent, noise, template, handwriting) and an average hides every slice. MMMU-Pro demonstrated the same fragility publicly by hardening MMMU and watching scores drop. Measure perception and reasoning separately, perception evals compare reads to source ground truth, grounding evals compare predicted to true regions, reasoning evals test conclusions given gold perception, and end-to-end catches everything but localizes nothing, and use the perception-vs-conclusion confusion matrix to surface the dangerous "right for wrong reasons" cell that inflates end-to-end accuracy while masking a perception failure. Never report an average without its slices; gate launches on the worst meaningful slice, not the headline, using a golden dataset rich enough (source region, separate gold-perception, slice labels, stakes) to compute all of it. LLM-as-judge inherits the model's perceptual blind spots and cannot catch a perception error it would also make, so reserve it for reasoning-given-gold-perception, format/helpfulness, and triage, never for perception ground truth, which must come from a structured extraction, exact match, human, or source data. For high-stakes modalities, evaluate calibrated abstention and harm-weighted error, because there the question is not only whether the system is right but whether it knows when to stop - which Production Architecture for Multimodal Systems and the cost chapter operationalize, building on the retrieval layer established in Multimodal RAG and Cross-Modal Search.