Every Modality Brings Its Own Blind Spots
> **Working claim:** There is no general "multimodal" capability you can reason about in the abstract.

Working claim: There is no general "multimodal" capability you can reason about in the abstract. Each modality fails in a distinct, characteristic way, and a system that treats image, audio, video, and document inputs through one undifferentiated pipeline inherits the worst blind spot of each without ever naming it. Designing well means designing per modality, against its specific failure.
The temptation to generalize
After a team ships its first multimodal feature, a dangerous abstraction sets in. The model "handles images, " and images include photos, scans, screenshots, charts, diagrams, and handwriting, so the team starts to think of itself as having solved "vision." The same model "handles audio, " so the team has solved "listening." This generalization is the source of the second category of multimodal incidents, not the clean-demo trap of Chapter 1, but the subtler error of carrying a mental model from the modality you tested into the modality you didn't.
The truth the rest of this book elaborates is that the modalities are not variations of one capability. They have different physics, different loss profiles, different benchmarks, and different ways of being confidently wrong. A photo loses small detail to resolution; a scanned document loses structure even when every character is legible; audio loses a word to a cough at the wrong instant; video loses an event to a sampling gap; a chart loses an exact value to rendering. These are not the same failure with different inputs. They are different failures, and a system has to be designed against each one specifically.
The motif for this chapter, and the book, is the discipline that follows: every modality brings its own blind spots. Naming the blind spot for each modality you accept is not pessimism; it is the entire content of a multimodal design review.
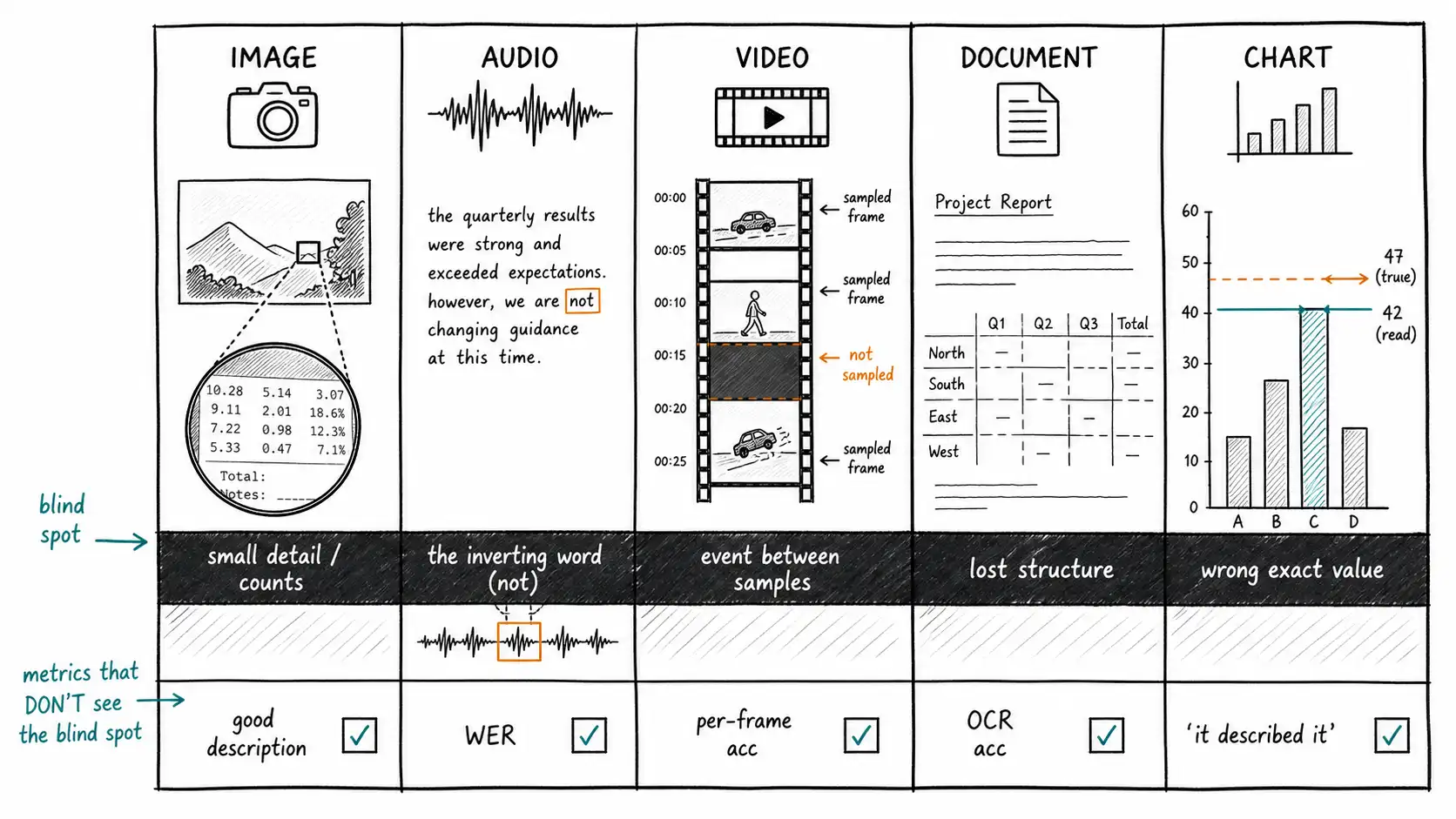
Images: the blind spot is small detail and spatial precision
A vision-language model is excellent at the gist of an image and unreliable at its fine structure. It will tell you there is a car, that it is damaged, that the damage is on the left, and then mis-count the number of bolts, mis-read a serial number, miss a hairline crack, and get the exact spatial relationship between two objects wrong. The GPT-4V system card documents this directly: weaknesses in counting, in precise localization, and in reading small or low-contrast text within an image.
The mechanism is the lossy projection from Chapter 1. An image is resized and split into a bounded number of patches; a 12-megapixel phone photo of a form might be reduced, for the purpose of the model's reasoning, to something far coarser. Detail smaller than the effective patch resolution is gone before reasoning begins. This produces a specific, testable rule: *if a human has to zoom in to read it, the model probably cannot read it from the full-frame image either. * The engineering response is not to hope the model gets better at small text but to crop. Detect the region of interest, crop and upscale it, and send the model the crop. A serial number that is illegible in a full-frame photo is often perfectly legible in a 300×80 crop. We will make this a core technique in the documents chapters; here, hold the principle: the image blind spot is detail and precise space, and the antidote is to control resolution at the region level rather than the frame level.
There is a second image blind spot worth naming early: spatial reasoning that requires counting or exact relations."How many people are wearing hard hats?" and "is the valve to the left or right of the gauge?" are exactly the questions where confident errors cluster. Integrated-capability benchmarks like MM-Vet score these dimensions separately precisely because they diverge: a model can be strong at recognition and description while weak at spatial and numeric precision. If your object of truth is a count or a precise relation, you are operating in the blind spot and must verify externally.
Audio: the blind spot is the single inverting word
Modern speech recognition is remarkable. Whisper, trained on a very large and diverse corpus of weakly-supervised audio, approaches human-level robustness on many benchmarks and handles accents, background noise, and multiple languages far better than earlier systems. This very competence is the trap: a transcript that is 95% word-accurate looks finished, and the 5% is not uniformly distributed across unimportant words.
The audio blind spot is that the errors cluster on exactly the tokens that carry decision-relevant meaning: negations, numbers, names, and domain terms."We will not ship Friday" and "we will ship Friday" differ by one short word whose loss inverts the only fact the meeting produced. A dosage of "fifteen" heard as "fifty, " a name "Bryan" heard as "Brian, " an account number off by a digit, these are low word-error-rate events with high decision impact. Word error rate (WER), the standard audio metric, treats every word equally and therefore systematically understates the risk that matters, because the words that matter are a tiny fraction of the total. A 4% WER can hide a 100% error rate on negations if your audio is noisy in the wrong way.
There is a second audio blind spot: everything that is not the words. A transcript discards who spoke (diarization), when they spoke (timestamps), how they spoke (tone, hesitation, stress), and the non-speech events (a door slamming, a baby crying, a machine alarm) that can be the most important content in a call. A call-center QA system that scores only the transcript cannot tell the difference between a calm explanation and a shouted threat, because the words can be identical. We treat this in full in the audio chapter; here, name the two blind spots, the inverting word, and the lost paralinguistic and event channel, and note that neither is measured by WER.
Video: the blind spot is the frame you didn't sample
Video is where the "just frames" mental model does the most damage, because it is half true in a way that hides the other half. A video is a sequence of frames, and you will process it as frames. The blind spot is the sampling decision: real systems do not feed every frame to a model, that would be ruinously expensive, so they sample, typically a frame every N seconds or at detected shot boundaries. Every frame you do not sample is a frame whose content the system cannot see, and events shorter than your sampling interval are invisible. The claims team's two-second pan across the damaged door fell entirely between samples.
This is a temporal blind spot with no analog in still images: the information exists, was uploaded, is recoverable, and is nonetheless absent from what the model reasons over, purely because of a sampling cadence the team chose without measuring its cost. The Gemini 1.5 report demonstrated models ingesting very long video at fine sampling within enormous context windows, which raises the ceiling, but it does not abolish the blind spot, because cost and latency still force sampling decisions for most production systems most of the time. Video also carries a second blind spot beyond sampling: causality and order. "Did the worker put on the harness before or after climbing?" is a question about temporal order that a bag of sampled frames, reasoned over as an unordered set, can get exactly backward. Preserving and presenting frame order, and the audio track, which the claims team ignored, is the antidote, and the subject of its own chapter.
Documents: the blind spot is structure, not characters
The document blind spot is the most counterintuitive because it survives even perfect character recognition. Suppose OCR reads every character on a scanned invoice correctly. You still do not have the invoice. You have a bag of strings with no idea which number is the total and which is a line item, which date is the invoice date and which is the due date, that the "$" in column three belongs to the row two cells up because of a merged header, that the stamp in the corner says PAID, that page 2 is an addendum that supersedes page 1, and that the signature block at the bottom is what makes the document binding. ChartQA and the document-understanding literature exist precisely because reading the marks is the easy half and understanding their arrangement is the hard half.
The document blind spot is therefore layout, structure, and provenance, and it is destroyed by exactly the most common pipeline: "run OCR, concatenate the text, send it to the model." That pipeline turns a two-dimensional, structured object into a one-dimensional string and discards the spatial relationships that make it a document. Two of the book's strongest chapters are about rebuilding what that pipeline throws away. For now, the rule: a document is not its text, and a system that flattens it to text has chosen its blind spot without admitting it.
Charts: the blind spot is the exact value
A chart is a special, dangerous case because it sits at the intersection of image and data. The model reads it as an image, a rendered figure, and produces numbers, which feel like data. They are estimates. Asked the value of a bar, a model will confidently report 42 where the true value is 47, because it is eyeballing a rendered shape, not reading an underlying datum. ChartQA measures exactly this gap between describing a chart's trend (often correct) and extracting its precise values (often wrong), and it is the reason a "chart analyst" feature is one of the riskiest things you can build naively: the output is numeric, looks authoritative, and is frequently off by an amount that matters. The chart blind spot is the precise quantitative value, and the antidote, wherever the underlying data exists, is to extract from the data, not the picture, and to treat the picture-read value as a claim to verify, not a measurement.
The unified blind-spot table
| Modality | Strong at | Characteristic blind spot | What does NOT measure it | External antidote |
|---|---|---|---|---|
| Image | Gist, recognition, description | Small detail, counts, exact spatial relations | A good description | Region crops; count/spatial verification |
| Audio | High word-level accuracy | The single inverting word; paralinguistics; events | Word error rate | Term-level checks; keep audio, not just transcript |
| Video | Per-frame description | Events between samples; temporal order | Per-frame accuracy | Shot detection; dense sampling near interest; keep order + audio |
| Document | Reading characters | Layout, table structure, supersession | OCR character accuracy | Layout parsing; structured extraction; page provenance |
| Chart | Trend, shape, description | Exact quantitative values | "It described the chart" | Extract from source data; verify read values |
Read down the "what does NOT measure it" column. Each entry is a metric a team naturally reaches for that is blind to the blind spot, a good description does not reveal a missed detail, WER does not reveal an inverted negation, per-frame accuracy does not reveal a missed event, OCR accuracy does not reveal lost structure, and "it described the chart" does not reveal a wrong value. This column is the chapter's sharpest single artifact: it lists the comfortable metrics that will lie to you, modality by modality.
Mixed media: the blind spots compound
Real inputs are rarely one clean modality. A support ticket arrives with a screenshot (document + chart + UI text) and a voice note (audio) describing it. A safety report is a video (frames + audio + temporal order) of a walk-through. A medical record is a scanned PDF (document) containing a photograph of a lesion (image) and a handwritten note (image + document). When modalities combine, their blind spots do not average, they compound. The screenshot's lost UI text plus the voice note's inverting word produce a system that confidently resolves a ticket about the wrong feature. The safety video's missed frame plus its reversed causality produce a system that reports the harness was worn.
The design response is not a single "multimodal model call" that swallows everything. It is to *decompose the input into its constituent modalities, route each to a pipeline designed against its blind spot, and only then fuse. * The screenshot goes to the document pipeline (layout-aware, with crops for UI text); the voice note goes to the audio pipeline (with term-level checks on the feature name); the fused answer carries provenance back to both. This decompose-route-fuse pattern is the structural answer to compounding blind spots, and it is why "just send it all to one model" is a strategy that works in the demo and fails in the field.
How to run a blind-spot design review
Make this concrete as a recurring practice. Before building any multimodal feature, for each modality the feature will accept, fill in five lines:
- Modality (honestly named). Not "image" but "phone photo of a metal part, often in poor warehouse lighting."
- Object of truth. Not "describe it" but "the part number stamped on the housing."
- Blind spot. "Small low-contrast stamped text under glare", the image blind spot, specifically located.
- What would hide it. "A fluent description that names the part type but invents or misreads the number, with no signal that it was a guess."
- External antidote + measurement. "Crop the stamped region and upscale; verify the read number against the parts database; slice accuracy by lighting; require human review when the number is not found in the database."
Five lines per modality. A feature accepting photos and voice notes is ten lines. Those ten lines are the difference between a team that named its blind spots and a team that will discover them, one incident at a time, in production. The rest of this book is mostly the elaboration of line five, the external antidotes and their measurement, for each modality in turn, beginning with the principle that makes all of them necessary: a model's answer about a signal is a claim about that signal, and the next chapter makes the case that the claim is not evidence until something independent verifies it.
Chapter summary
There is no abstract "multimodal" capability; there are distinct modalities with distinct, characteristic blind spots, and the central error of intermediate teams is carrying the mental model from the modality they tested into the modality they didn't. Images are strong at gist and weak at small detail, counts, and exact spatial relations, because detail below the effective patch resolution vanishes before reasoning, the antidote is region-level crops, not hope. Audio achieves high word accuracy yet hides the single inverting word (a negation, a number, a name) and discards speaker, timing, tone, and non-speech events; word error rate is blind to exactly the words that matter. Video's blind spot is the sampling decision, events shorter than the sampling interval are invisible, plus temporal order, neither caught by per-frame accuracy. Documents lose layout, table structure, and page supersession even when every character is read correctly, so OCR accuracy is no guarantee. Charts yield confident numeric values that are estimates from a rendered figure, off by amounts that matter, undetected by "it described the chart." The unified table's most useful column lists the comfortable metric that is blind to each blind spot. Mixed-media inputs compound rather than average their blind spots, which is why the right pattern is decompose-route-fuse, not one all-swallowing model call. Run a five-line blind-spot design review per modality before building; line five, external antidote plus sliced measurement, is what the rest of the book builds out. This chapter follows directly from The Demo Is Not the System; the next chapter turns the blind-spot principle into an architectural requirement: A Vision Answer Is Not Evidence.