Audio Is Not Text After Transcription
This chapter turns audio is not text after transcription into a concrete operating problem for the multimodal book.

Working claim: Transcription turns audio into text, but the text is a lossy projection of a time-based signal that also carried speakers, timing, emotion, overlap, and non-speech events, and the transcription's errors cluster precisely on the decision-bearing words. A system that reasons only over the transcript has thrown away most of the audio and kept the part most likely to be quietly wrong.
The transcript that flipped a decision
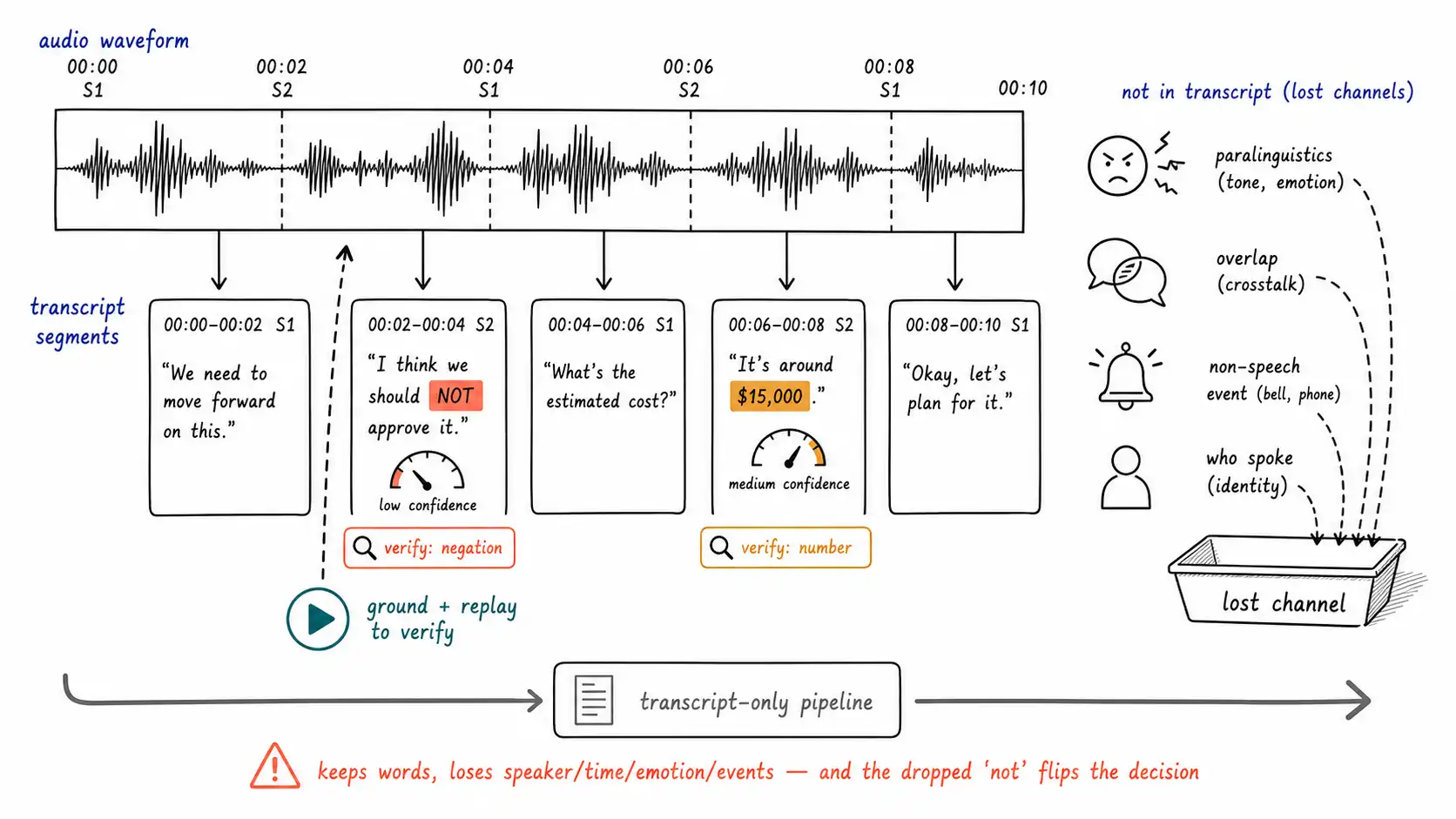
A meeting-intelligence product transcribed a product team's call and produced an action-items summary. One line read: "Engineering will ship the migration on Friday." The team had said the opposite. The actual sentence was "Engineering will not ship the migration on Friday, we need another week for the data backfill." The transcription dropped the "not." Everything downstream was correct: the summarizer faithfully summarized the transcript it was given, the action-item extractor correctly identified a commitment, the calendar integration correctly created a Friday milestone. The system worked perfectly on a transcript that had inverted the one fact the meeting produced. Nobody caught it until Friday came and the migration did not.
This is the audio blind spot from Chapter 2, made concrete: the transcription error rate was tiny, one short word out of several thousand, and the decision error rate was total. Word error rate (WER), the standard speech-recognition metric, would have rated this transcript as excellent, because WER averages over all words and the words that matter are a vanishing fraction of the total. The gap between "the transcript is 98% accurate" and "the transcript inverted the decision" is the audio version of the OCR-vs-understanding gap from Chapter 7, and it has the same shape: a component metric that looks great while the task metric fails, because the metric is blind to which words carry the meaning.
Transcription is genuinely good: which is the trap
It is important to be fair to the technology, because the trap is set by its competence, not its weakness. Whisper was trained on a very large, diverse corpus of weakly-supervised audio and demonstrated robustness that approaches human-level transcription on many benchmarks, handling accents, background noise, and dozens of languages far better than prior systems. The Whisper ICML 2023 paper emphasizes generalization across domains without fine-tuning. This is real and it is why transcription feels solved.
But "approaches human-level on average WER" is exactly the kind of average that hides the distribution. The errors that remain are not uniformly spread; they concentrate on:
- Negations ("not, " "don't, " "no longer"), short, unstressed, easy to drop, catastrophic to lose.
- Numbers: "fifteen"/"fifty, " "thirteen"/"thirty, " account and dosage digits, where a single phoneme changes the value.
- Named entities: people, products, companies, places, where there is no language-model prior to correct toward the right rare token.
- Domain terms: drug names, part numbers, legal terms, technical jargon outside the training distribution.
- Speech in overlap, accent, or noise: exactly the conditions of real calls, as opposed to clean read speech.
Every item on this list is decision-bearing and error-prone at once, which is the worst possible combination. And every item is invisible to WER, because WER counts a dropped "not" the same as a dropped "um." The engineering consequence is that you cannot trust the transcript's overall quality number; you have to measure error on the categories that carry decisions, and you have to verify decision-bearing words specifically. Multilingual content compounds this, M3Exam is a reminder that performance varies sharply across languages, so a transcription quality that is fine in English may be materially worse in another language your users actually speak.
Everything the transcript is not
Beyond the inverting word, a transcript discards entire channels of meaning that were present in the audio:
- Who spoke (diarization). "I approve the budget" means something different depending on whether the speaker was the CFO or an intern. A transcript without speaker labels loses authority and accountability.
- When they spoke (timestamps). Without time offsets, a claim cannot be grounded (Chapter 8), there is no way to jump back to the moment and verify it.
- How they spoke (paralinguistics). Tone, hesitation, stress, sarcasm, distress."Fine." spoken flatly and "Fine!" spoken angrily transcribe identically. A call-center QA system scoring only words cannot tell a calm resolution from a barely-contained escalation.
- Overlap and interruption. Who interrupted whom, whether a question was answered or talked over, structure that a flat transcript flattens.
- Non-speech events. A machine alarm in a maintenance call, a baby crying in a benefits call, a gunshot, a slammed door. These can be the single most important content and are simply absent from a words-only transcript.
A system that reasons over the transcript alone is reasoning over a projection that kept the words and discarded the speaker, the time, the emotion, and the events. For some tasks (a topic summary of a clean podcast) that projection is adequate. For many tasks (compliance, safety, QA, anything where who, when, how, or what-else-happened matters) it is not, and the system must preserve and reason over the richer structure.
A transcript schema that keeps the structure
The fix begins with refusing to represent audio as a flat string. The transcript is a sequence of segments, each with the structure the flat string discards, and each decision-bearing token flagged for verification.
from dataclasses import dataclass, field
@dataclass
class Token:
text: str
start_ms: int
end_ms: int
confidence: float # ASR token-level confidence, where available
category: str | None = None # "negation" | "number" | "entity" | None
@dataclass
class Segment:
segment_id: str
speaker: str # diarized speaker label
start_ms: int
end_ms: int
text: str
tokens: list[Token]
language: str
nonspeech_events: list[str] = field(default_factory=list) # "alarm","laughter"
@dataclass
class Transcript:
source_id: str
source_hash: str
segments: list[Segment]
diarization_confidence: float
DECISION_CATEGORIES = {"negation", "number", "entity"}
def flag_decision_risk(t: Transcript) -> list[Token]:
"""Surface low-confidence decision-bearing tokens for verification."""
risky = []
for seg in t.segments:
for tok in seg.tokens:
if tok.category in DECISION_CATEGORIES and tok.confidence < 0.85:
risky.append(tok) # e.g. a low-confidence "not" or "$15,000"
return riskyThe schema keeps speaker, time, language, and non-speech events, which is what makes grounding and authority-aware reasoning possible. flag_decision_risk is the chapter's sharpest artifact: it does not try to fix the transcript, it surfaces the specific tokens whose error would flip a decision and whose confidence is low, so that a verification step or a human looks at exactly those. The dropped "not" in the meeting case would have been a low-confidence negation token, flagged, and either re-checked (replay the segment, re-transcribe that window with a different model) or routed to review before the summary was trusted. The point is not perfect transcription, that is unattainable, but knowing which words to distrust and verifying those.
Grounding audio: the transcript points back at the sound
Chapter 8's grounding applies directly: every segment carries start_ms/end_ms, so every claim derived from the transcript can be tied to an audio offset and replayed. This is the audio verification path. When the meeting assistant claims "the team decided to delay launch, " the claim is grounded to the segment at 00:14:32, and the verification is a human (or a second ASR pass) listening to that exact two-second window. A claim grounded to an audio offset is checkable in seconds; an ungrounded claim from a flat transcript is an assertion that requires re-listening to the whole call. The richer schema is what makes audio claims auditable, exactly as the bounding box made document claims auditable.
Long audio and the temptation of one giant context
A newer option changes the architecture: models like those in the Gemini 1.5 report can ingest very long audio (and video) directly into enormous context windows, reasoning over hours of recording without an explicit transcription step. This is genuinely powerful and dissolves some of the transcript-as-bottleneck problem, the model can attend to tone and pacing the flat transcript discarded. But it does not dissolve the chapter's lesson; it relocates it. The model still produces claims about the audio, those claims are still unverified until grounded and checked (Chapter 3), and the long-context model's confidence about a decision-bearing word it heard in a noisy passage is no better calibrated than a transcriber's. If anything, the direct-audio path makes grounding harder, because there is no token-level transcript with offsets unless you generate one, so a disciplined long-audio system still produces a timestamped transcript as a derived artifact for grounding and verification, even when the reasoning happens over the raw audio. MM-Vet's lesson that integrated capabilities are harder than component ones applies: hearing-plus-reasoning over hours of audio is exactly the integrated task where confident errors live, and the verification discipline is more necessary, not less.
A short field rule for audio systems
The chapter's practical rule, applied to any audio feature, is three steps. First, never report or trust WER alone as the quality signal for a decision-making system; measure error on decision-bearing categories (negations, numbers, entities, domain terms) and, ideally, downstream task accuracy. Second, preserve the structure the transcript discards, speaker, time, language, paralinguistic cues where the task needs them, and non-speech events, because for compliance, safety, and QA tasks that structure is the content. Third, ground every audio claim to an offset and verify decision-bearing words, so that a flagged low-confidence "not" or a flagged dosage gets re-checked before anything acts on it. The meeting-intelligence team adopted exactly these: their summarizer now flags low-confidence negations and numbers, grounds every action item to the audio offset where it was committed, and routes flagged items to a quick human confirm. The dropped "not" became a flagged token a reviewer cleared in five seconds, instead of a Friday that came and went.
Chapter summary
Transcription projects a time-based signal carrying speakers, timing, emotion, overlap, and non-speech events down to a flat string, and its errors cluster on exactly the decision-bearing words, negations, numbers, named entities, domain terms, so a tiny word error rate can coexist with a total decision error, as when a dropped "not" inverted a meeting's only commitment. Whisper's near-human average WER is precisely the trap, because the average hides a distribution whose remaining errors are decision-bearing and error-prone at once and invisible to WER, with multilingual content (M3Exam) widening the gap. A transcript also discards whole channels, who spoke, when, how (tone/stress), overlap, and non-speech events, that are the content for compliance, safety, and QA tasks. The fix is to represent audio as structured segments with speaker, time, language, token-level confidence, and non-speech events, and to surface decision-bearing low-confidence tokens for verification rather than chase perfect transcription. Grounding applies directly: every segment's offset lets a claim be replayed and checked in seconds, making audio claims auditable. Long-context direct-audio models (Gemini 1.5) relocate rather than remove the lesson, they still produce unverified claims and still need a timestamped transcript as a derived artifact for grounding. The field rule: never trust WER alone, preserve the discarded structure, and ground-and-verify decision-bearing words. This chapter follows the grounding discipline established in Grounding, Bounding Boxes, and Visual Citations; the next chapter applies the same temporal-grounding thinking to: Video Is Not Just Frames.