Introduction: The Photo of the Bumper
A team I will call the claims team, the details are composited from several real projects, but the shape is exact, built something that demoed beautifully.

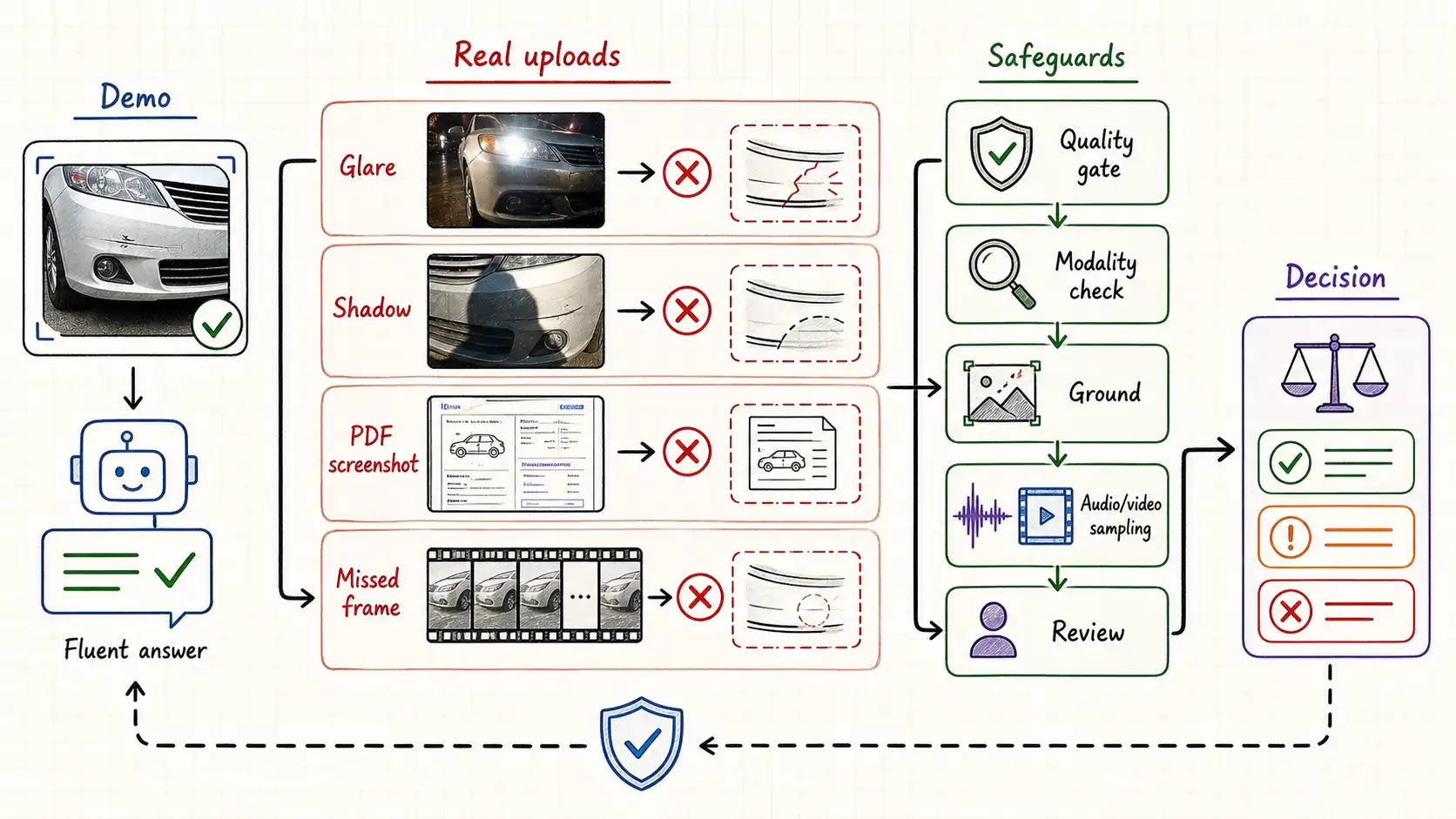
Research spine: this chapter stays grounded in GPT-4V system card and MMMU-Pro, then applies that evidence to the operating judgment in the book. A team I will call the claims team, the details are composited from several real projects, but the shape is exact, built something that demoed beautifully. They handled auto insurance, and the slow, expensive part of their workflow was the first-notice-of-loss triage: a human looking at photos a policyholder uploaded after a fender-bender, deciding whether the damage matched the claimed location, estimating severity, and routing the claim. When vision-language models became good enough to describe an image in fluent paragraphs, someone on the team wired one up. You upload a photo of a dented bumper, the model writes three sentences about the damage, and an extraction step pulls out a severity band and a damaged-part list. The first demo was the kind that ends meetings early. Someone uploaded a clean, well-lit photo of a crumpled rear quarter panel, and the system said moderate damage to the rear left quarter panel, consistent with a low-speed impact, no visible structural deformation, which was exactly what the adjuster in the room would have said, in nine seconds instead of nine minutes.
The pilot went to a few hundred real users. Within two weeks the team had a folder of failures that did not look like the demo at all.
A policyholder photographed a bumper at night, under a streetlight, and the glare across the wet paint became, in the model's description, a long horizontal crack consistent with impact. There was no crack. There was a reflection. The system had described damage that was not there.
Another user uploaded a photo where the actual damage, a deep gouge, sat in shadow under the wheel arch, and the model, attending to the bright, undamaged hood that filled most of the frame, called it minor cosmetic scuffing. The system had missed damage that was there.
A third user did not upload a photo of a car at all. They uploaded a screenshot of the repair estimate PDF their body shop had emailed them, because the upload button said "add a photo" and that was the photo they had. The model gamely described it as a document showing line items, and the extraction step, expecting a damage description, produced garbage. The system had been handed a different modality wearing the costume of the expected one.
A fourth case was the one that got escalated. A user uploaded a short video, they had walked around the car with their phone, and the system sampled one frame per second, none of which happened to catch the two-second pan across the damaged door. The model described an undamaged car. The claim was auto-routed to a fast-track, low-touch path. The damage was real and significant. A transcript of the video's audio, where the user said "you can see the big dent on the driver's door here, " existed in the file and was never consulted, because the team had treated the video as "just frames."
None of these failures were the model "not working." On clean inputs it worked as well as the demo promised. The failures came from everything around the model that the demo had quietly assumed: that inputs would be sharp, well-lit, correctly framed, of the expected modality, and that a confident description was the same thing as a verified fact. The team had built a demo. They had not yet built a system.
That gap, between a model that can produce an impressive multimodal answer once, and a system that can produce a defensible multimodal answer repeatedly, on messy real-world media, and prove what it saw, is the subject of this book.
Why this confusion is so easy to fall into
The confusion is not a sign of a careless team. It is the predictable result of a genuinely impressive capability arriving faster than the engineering vocabulary to reason about it. When a model can look at a photograph and discuss it as fluently as a person, the natural inference is that it sees the way a person sees, that the pixels are available to it the way they are available to you. They are not. The image is resized, tiled, and turned into a bounded number of visual tokens before the model ever reasons about it. Fine detail, a hairline crack, a small digit on a meter, a checkbox, a single misread cell in a table, may simply not survive that compression, and the model will still answer fluently, because fluency is cheap and accuracy is not.
The same trap appears in every modality, wearing different clothes. Speech recognition that produces a clean-looking transcript invites the inference that the meeting has been understood, when a single misheard word, "we will not ship Friday" transcribed as "we will ship Friday", can invert the one fact that mattered. A model reading a chart invites the inference that it has measured the chart, when it has estimated values from a low-resolution rendering and will confidently report 42 where the bar is at 47. A document pipeline that extracts text invites the inference that the document is understood, when the layout, the table structure, the stamp, and the fact that page 3 supersedes page 1 have all been thrown away.
This matters because the moment you credit the model with a capability it does not reliably have, you stop building the parts of the system that actually provide it. You skip the input-quality gate that would have caught the night-time glare. You skip the modality detector that would have noticed the screenshot-of-a-PDF. You skip the grounding step that would have tied the "crack" to a pixel region a human could check. You skip the structured re-extraction that would have disagreed with the chart reading. You skip the audio track that contained the answer. The demo makes the surrounding engineering look unnecessary, and the surrounding engineering is the product.
What this book argues
The argument follows the natural complexity gradient of multimodal work, perception, then representation, then documents, then time-based media, then retrieval, then evaluation, then operations, then specific use cases, and it builds.
The demo is not the system comes first. We separate the modalities by their distinct blind spots, refuse to treat OCR, captioning, and visual reasoning as the same task, and establish the book's hardest rule early: a vision answer is not evidence until it is verified. A description is a claim. A field value tied to a pixel box, cross-checked against a structured re-extraction, is closer to a fact.
How machines learn cross-modal meaning comes second. Without turning the book into model theory, we build the mental models you actually need: encoders and embeddings for images, audio, and text; contrastive learning and CLIP-style alignment; vision-language models and instruction tuning; joint embedding spaces and, crucially, where those spaces lie to you. A caption is not an image. An OCR string is not a document. Similarity in a shared space is a ranking signal, not a verdict.
Documents are multimodal objects is the practical heart of the early book. A scanned invoice is not text and not "an image", it is layout, typography, tables, merged cells, stamps, signatures, checkboxes, page order, and scanner noise, all at once. We build ingestion schemas that preserve bounding boxes and page numbers, decide when a screenshot beats text extraction and when it does not, and make grounding and visual citation first-class so that every extracted value can be pointed back at the pixels it came from.
Audio and video are time systems comes fourth. Audio is not text after transcription: it has speakers, timestamps, confidence, accents, overlapping speech, and non-speech events, and a transcript alone can miss the emotional or visual context that changes the meaning. Video is not just frames: it has temporal causality, and the frame you sample is a sampling decision that can delete the answer. We build timestamped transcript schemas, video ingestion pipelines, and the evals that catch a transcription error before it changes a task assignment.
Multimodal RAG and evaluation come next, together, because they are the discipline that separates a system from a demo. We route queries across text, image, table, and video indexes; we keep region-level provenance through retrieval; and then we evaluate perception separately from reasoning, because OCR accuracy is not answer accuracy and a benchmark average hides the slice, the one lighting condition, accent, or document template, where the system quietly fails.
Production architecture closes the book before the field guide. Multimodal systems store originals and a growing pile of derived artifacts; they reprocess when models upgrade; they pay real money per image page and audio minute; and they touch faces, documents, minors, and medical data, which makes privacy and retention load-bearing rather than optional. We build the storage layout, the cost model, the observability schema, and the runbook for the incident you will eventually have: *the system extracted the wrong value from a document and acted on it. *
The book ends with a use case field guide, invoice extraction, medical form review, support-screenshot assistants, retail visual search, meeting intelligence, call-center QA, safety inspection from photos, chart and dashboard analysts, and UI-screenshot debugging, each as a short playbook of what multimodal genuinely helps with, what it does not solve, what ingestion it demands, how to evaluate it, and how it fails.
How to read this book
It is written to be read in order, because the movements build, but it is also written so that an engineer in the middle of a specific fire can open to the relevant chapter and find a usable artifact: an ingestion schema, a grounding function, a routing table, an eval fixture, a cost model, a runbook. The code is deliberately about multimodal infrastructure, preserving provenance, grounding claims to regions, re-extracting structure to verify a reading, sampling video without deleting the answer, evaluating perception apart from reasoning, and not about generic image-upload demos. Every example is chosen to preserve provenance and to test a real failure mode, because that is what the demo skipped and what the product needs.
Throughout, the tone is skeptical without being cynical. Multimodal models are a genuine advance; some of them are astonishing. The skepticism is aimed not at the capability but at the story told about the capability, the story that says inputs are clean, that seeing is the same as measuring, that a transcript is an understanding, that the hard parts have been abstracted away. They have not. They have moved into ingestion, grounding, evaluation, and operations, which is where the rest of this book lives.
A demo only needs a good answer once, on an input it chose. A product needs a defensible answer repeatedly, on inputs the user chose: blurry, glared, cropped, accented, noisy, in the wrong modality, with the answer in shadow or in the two seconds you didn't sample. The claims team's system gave a good answer in the demo and four dangerous ones in week two. The rest of this book is about the difference.
The Front Matter: Multimodal in Practice lays out the MODAL framework and the book's full table of contents. Turn the page. Someone is about to upload a photo of a bumper at night, and the system needs to know the difference between a crack and a reflection. The Demo Is Not the System is where we start building the answer.