Multimodal RAG and Cross-Modal Search
This chapter turns multimodal rag and cross-modal search into a concrete operating problem for the multimodal book.

Working claim: Multimodal retrieval is not "vector search with images added." It is a routing-and-reranking problem across heterogeneous indexes where the right file can be retrieved for the wrong region, the right text matched to the wrong visual object, and a visually similar result returned that is semantically wrong, and where region-level provenance must survive retrieval or the generated answer cannot be grounded or verified.
Four ways multimodal retrieval is wrong while looking right
The original RAG idea is simple and powerful: retrieve relevant evidence, then generate an answer conditioned on it, so the model's output is grounded in retrieved facts rather than parametric memory. Multimodal RAG inherits the framing and adds failure modes that text RAG never had, because the evidence is now images, document regions, table cells, audio segments, and video frames, retrieved through indexes that each have their own blind spots. Four failures recur, and they all look like success at the surface because the system confidently returns something:
- Right file, wrong region. The retriever finds the correct 40-page contract but the chunk it returns is from the wrong clause; the answer is grounded in the document but in the wrong part of it. Without region-level provenance, the answer cites "the contract" and is unverifiable.
- Right text, wrong visual object. A query for "the red warning light" retrieves a document whose OCR text mentions "red warning light" but whose actual image shows a green indicator; the text matched, the pixels did not.
- Visually similar, semantically wrong. The Chapter 5 failure inside retrieval: an image query returns a visually near-identical but semantically different item (wrong SKU, wrong version, wrong region's form).
- Modality mismatch. A query that should hit the table index ("what was Q3 EMEA revenue?") is routed only to the text index, which retrieves prose about revenue and misses the table cell that holds the number.
Each of these returns a plausible result, so each passes a casual look. The discipline of this chapter is to design retrieval so these failures are caught, by routing queries to the right index, reranking heterogeneous candidates honestly, and preserving region-level provenance so that every retrieved piece of evidence can be grounded and verified per Chapters 3 and 8.
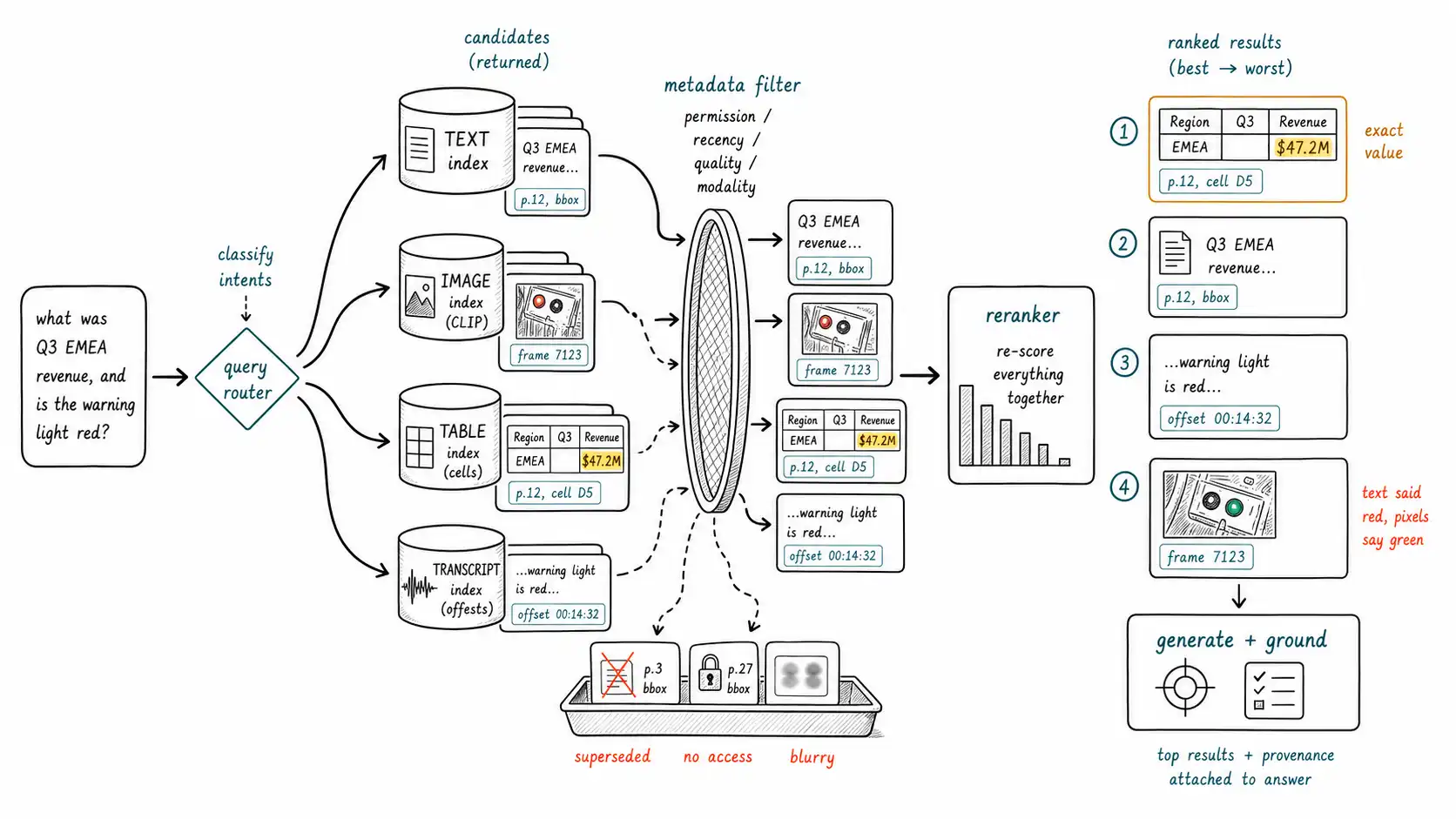
Separate indexes per modality, or one shared index?
The first architectural decision is whether to keep one shared embedding space (e. g. CLIP/ImageBind, where a text query can hit image and text alike) or separate, modality-specialized indexes (a text index, an image index, a table index, a transcript index). The honest answer is both, in layers, and the reasoning is the Chapter 5 boundary.
A shared space (CLIP, ImageBind) is excellent for recall-oriented fan-out: a single query can retrieve candidates across modalities cheaply, finding the image, the document, and the transcript moment that resemble the query. It is poor at precision on the dimensions captions ignore, exact identity, version, the precise table value. Separate specialized indexes are the opposite: a table index with structured cells answers "Q3 EMEA revenue" exactly; a transcript index with offsets answers "when did they say X" precisely; a layout-aware document index returns the right region, not just the right file. The mature architecture uses the shared space (or a query router) to decide which specialized indexes to hit and to provide cross-modal recall, and uses the specialized indexes for precise, provenance-rich retrieval. This is the retrieval-layer expression of "candidates from the space, decisions from structure."
Routing a query to the right indexes
Routing is where the modality-mismatch failure is prevented. A query has an implied object of truth (MODAL's O) that determines which indexes can answer it: a question about a precise number wants the table index; a question about an image's content wants the image index; a question about something said wants the transcript index; a question about a clause wants the document-region index. Routing classifies the query and fans out accordingly.
from dataclasses import dataclass
@dataclass
class RetrievalResult:
chunk_id: str
modality: str # "text" | "image" | "table" | "transcript" | "video"
score: float
source_id: str # provenance root
region: dict # page+bbox / audio offset / frame - survives retrieval
payload: dict # text, table_json, image_crop_uri, etc.
def route_and_retrieve(query: str, ctx) -> list[RetrievalResult]:
intents = classify_query_intents(query) # may be multiple
results: list[RetrievalResult] = []
# Fan out only to the indexes the object of truth needs.
if "precise_value" in intents or "table" in intents:
results += table_index.search(query, ctx, k=10) # structured cells
if "visual_object" in intents or "image" in intents:
results += image_index.search(embed_text(query), ctx, k=20) # CLIP-style
if "spoken" in intents:
results += transcript_index.search(query, ctx, k=10) # with offsets
if "document" in intents or not intents:
results += doc_region_index.search(query, ctx, k=20) # layout-aware regions
# Metadata filters apply BEFORE ranking: permission, recency, quality, modality.
results = [r for r in results
if allowed(r.source_id, ctx.user) # permission (Ch. 15)
and not superseded(r.source_id) # recency (Ch. 6)
and r.payload.get("quality_ok", True)] # input-quality gate
return resultsTwo things matter beyond the routing. Every RetrievalResult carries its region, the page+bbox, the audio offset, the frame, so provenance survives retrieval and the eventual answer can be grounded; a retrieval system that returns only the text and drops the region has thrown away the ability to verify or cite, which is the "right file, wrong region" failure baked into the architecture. And the metadata filters, permission, recency, quality, modality, apply before ranking, because a high-similarity result the user is not allowed to see, or that is superseded, or that came from a blurry image, should never compete for the top slots. These filters encode the Chapter 5 lesson (the dimensions the embedding ignores) directly into the retrieval path.
Reranking heterogeneous candidates
After fan-out, you have candidates of different modalities with scores that are not comparable: a CLIP cosine similarity, a BM25 text score, and a table-match score live on different scales and mean different things. Naively merging by raw score lets one index's scoring quirk dominate. Reranking solves this by re-scoring all candidates against the query with a single, consistent model that sees the actual content, not just the first-stage score.
| Signal | What it captures | When it dominates |
|---|---|---|
| First-stage similarity | Cheap recall ranking within one index | Never alone; it's a candidate filter |
| Cross-encoder rerank | Query-content relevance, modality-aware | The default precision step |
| Exact-match / structured | SKU, version, value equality | When object of truth is an identifier or number |
| Recency / version | Currency of the evidence | Forms, prices, policies, anything time-sensitive |
| Source authority | Trust of the source (official vs user-generated) | High-stakes answers |
The reranker's job is to take heterogeneous candidates and produce a single honest ordering by relevance to the query and the object of truth, promoting the table cell over the prose-about-revenue when the question wants a number, promoting the current form over last year's, demoting the visually-similar-but-wrong-SKU. This is also where the "right text, wrong visual object" failure is caught: a reranker that actually looks at the retrieved image crop (not just its OCR text) can notice the indicator is green, not red, and demote it. MM-Vet's emphasis on integrated capability is the reminder that retrieval quality and reasoning quality compound: a reranker that surfaces the right grounded evidence is doing half the work of getting the answer right.
The retrieval result must carry provenance to the answer
The thread tying this chapter to the rest of the book is that provenance must survive the entire retrieval-to-answer path. When the generator produces the final answer, each claim in that answer should trace to a specific retrieved RetrievalResult and through it to a SourceRegion (Chapter 8). This is what makes the generated answer groundable and verifiable rather than a fluent synthesis floating free of its evidence. Concretely, the generation step should be constrained to cite the chunk IDs it used, and a post-generation check should confirm each material claim is supported by a retrieved region, the multimodal version of the "evidence before eloquence" discipline.
def answer_with_provenance(query, results, ctx):
top = rerank(query, results)[:6] # honest cross-modal ordering
prompt = build_grounded_prompt(query, top) # passes chunk_ids + crops
draft = vlm.generate(prompt) # asked to cite chunk_ids
# Post-check: every material claim must map to a retrieved region.
claims = extract_claims(draft)
for c in claims:
c.region = region_for_cited_chunk(c.cited_chunk_id, top)
c = reverify(c, ctx) # Ch. 8 independent re-read
return assemble_answer(claims) # each claim grounded + checkedThe "right file, wrong region" failure is caught here: if a claim cites a chunk whose region does not actually support it, the re-verification fails and the claim is flagged. The "visually similar, semantically wrong" failure is caught by the structured filters upstream and the reranker. The "modality mismatch" is caught by routing. None of these are caught by "embed everything into one index and return the top-k, " which is the architecture most multimodal RAG systems start with and the one that produces confidently-grounded-in-the-wrong-place answers. DocVQA-style evaluation, where the answer must be supported by a specific document region, is the right test bed for this whole pipeline, because it scores not just whether the answer is right but whether it is supported.
Cross-modal search as a product surface
Worth a closing note: the same machinery powers product features users ask for, text-to-image search ("find the slide with the architecture diagram"), image-to-product search (Chapter 5's retail case), audio-to-moment search ("find where the customer mentioned cancellation"). The architecture is identical: route by object of truth, retrieve with provenance, filter on the dimensions the embedding ignores, rerank honestly, and present results with their grounding so the user can verify. The retail visual-search failure, the meeting "find the moment" feature, and the document "find the clause" feature are the same system with different index emphases, and they succeed or fail on the same disciplines: did provenance survive, were the embedding-blind dimensions filtered structurally, and is each result something the user can check at a glance. Cross-modal search is where multimodal RAG becomes visible to users, and where the cost of dropping provenance becomes a support ticket rather than a silent incident. This chapter follows Video Is Not Just Frames; the next movement evaluates whether the system is actually working: Evaluation: Seeing Is Not Verifying.
Chapter summary
Multimodal RAG inherits the RAG framing and adds failures text RAG never had, right file/wrong region, right text/wrong visual object, visually similar/semantically wrong, and modality mismatch, all of which return plausible results and pass a casual look. The architecture that catches them uses a shared embedding space (CLIP, ImageBind) for recall-oriented cross-modal fan-out and specialized indexes (text, image, table, transcript, document-region) for precise, provenance-rich retrieval, choosing between them by the query's object of truth. Routing classifies the query and fans out only to the indexes that can answer it, preventing modality mismatch; every retrieval result carries its region (page+bbox, offset, frame) so provenance survives retrieval and the answer can be grounded; and metadata filters for permission, recency, quality, and modality apply before ranking, encoding the Chapter 5 dimensions the embedding ignores. Reranking re-scores heterogeneous, non-comparable first-stage scores with a single content-aware model, promoting the exact table cell over prose-about-revenue and demoting the visually-similar-wrong-SKU and the green-light-that-text-called-red. Provenance must survive all the way to the answer: generation cites chunk IDs, and a post-check re-verifies each material claim against its retrieved region (Ch. 8), catching the right-file-wrong-region failure that "embed everything into one index" bakes in. The same machinery powers user-facing cross-modal search, which succeeds or fails on the identical disciplines, surviving provenance, structural filtering of embedding-blind dimensions, and presenting results with grounding the user can verify.