Privacy, Safety, and High-Stakes Images
This chapter turns privacy, safety, and high-stakes images into a concrete operating problem for the multimodal book.

Working claim: Multimodal media is among the most sensitive data a system can hold, faces, documents, locations, medical conditions, minors, and a vision model that produces fluent, confident readings of high-stakes images is a liability multiplier unless privacy, retention, and safety are designed in. The same images you store for accuracy and audit are the images a breach, a subpoena, or a deletion request will be about.
The photos you did not mean to keep
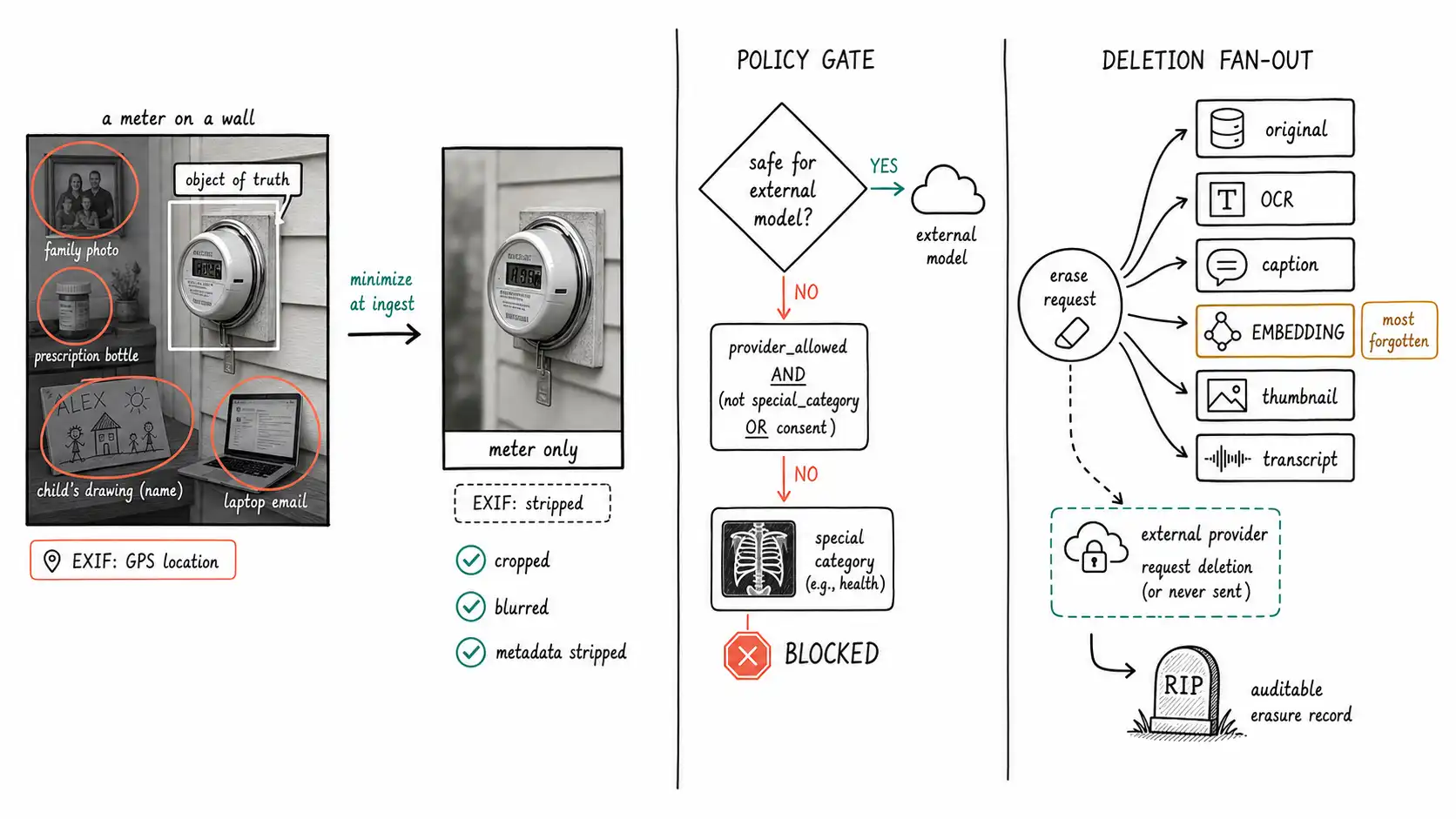
A field-services company built an app where technicians photographed equipment they were repairing, and a vision model logged the work. The feature worked. What the team did not plan for was *everything else in the photos. * Technicians, photographing a meter on a wall, captured the homeowner's family photos, prescription bottles on a counter, a child's drawing with a name on it, a laptop screen with an open email. All of it went into object storage, indefinitely, linked to a customer record, embedded into a searchable index, and passed through a third-party vision API. None of it was the object of truth. All of it was now sensitive data the company was storing, processing, and exposing to its retrieval system and its model provider, without consent, without a retention limit, and without any way to find or delete it.
This is the privacy fact of multimodal systems that text systems mostly escape: media captures far more than the object of truth, and that excess is frequently sensitive. A text form captures the fields it asks for. A photograph captures whatever was in frame; a scanned document captures every other field on the page; an audio recording captures every voice in the room; a video captures bystanders. The system's intended data is a small foreground; the captured data is the whole scene, and the scene contains faces, identifiers, locations (EXIF GPS in photos), health information, and minors. Designing a multimodal system means designing for the data you did not mean to collect as much as the data you did, because regulators, breaches, and deletion requests will treat all of it as yours.
Minimization: capture and keep less
The first principle, from privacy regulation and security practice alike, is data minimization: collect and retain only what the object of truth requires. For multimodal systems this is harder than for text because you cannot un-see what is in frame, but there are real levers:
- Strip metadata on ingest. Photos carry EXIF, including GPS coordinates and device identifiers. Unless location is the object of truth, strip it at ingest. The field-services app was storing the exact GPS of every customer's home in image metadata it never used.
- Redact at ingest, before storage and before the model. Run face detection, license-plate detection, and PII detection (names, account numbers, faces) and redact or blur regions that are not the object of truth before the image is stored, indexed, or sent to a model provider. The meter reading does not require the family photos in the background; blur everything outside the region of interest.
- Crop to the object of truth. The same crop-to-region pattern that improves accuracy and cost (Chapter 14) is a privacy control: if you only store and process the cropped meter, you have not collected the room. Cropping is the single technique that serves accuracy, cost, and privacy at once.
- Prefer derived artifacts over originals where possible. If the object of truth is a meter reading, you may be able to store the extracted value and a tight crop, and delete the full original after a short verification window, rather than retaining the whole scene forever.
These are not after-the-fact cleanups; they are ingest-time transforms, because once the full image is in storage, the index, and the provider's logs, "delete it later" is a promise across systems you may not control. Minimization at ingest is the only kind that actually reduces exposure.
Special categories and consent
Some multimodal data is not merely personal but special-category, health data, biometric data (faces used for identification), data about children. GDPR Article 9 places special restrictions on processing such data, and medical images, photographs of identifiable people, and recordings of minors routinely fall into it. The engineering consequences are concrete: special-category media needs a lawful basis and usually explicit consent; it should be tagged as special-category in the storage schema (so retention, access, and deletion policies can treat it differently); and it frequently should not be sent to a third-party model provider without a data-processing agreement that permits it. A system that treats a chest X-ray, a photo of a customer's face, and a meter reading as undifferentiated "images" has no way to apply the stricter handling the sensitive ones require. The schema must carry a sensitivity classification, set at ingest, that drives downstream policy.
-- Sensitivity is set at ingest and drives retention, access, and routing.
ALTER TABLE source_media
ADD COLUMN sensitivity TEXT NOT NULL DEFAULT 'standard',
-- 'standard' | 'pii' | 'special_category' | 'minor'
ADD COLUMN consent_basis TEXT, -- lawful basis / consent reference
ADD COLUMN provider_allowed BOOLEAN NOT NULL DEFAULT FALSE, -- may leave our boundary?
ADD COLUMN redaction_applied JSONB; -- what was blurred/stripped at ingest
-- Special-category media must not be sent to an external provider
-- unless explicitly permitted, and must have a consent basis.
CREATE OR REPLACE VIEW media_safe_for_external_model AS
SELECT source_id FROM source_media
WHERE provider_allowed = TRUE
AND (sensitivity <> 'special_category' OR consent_basis IS NOT NULL);The view encodes a policy gate: before any media is sent to an external model, it must pass media_safe_for_external_model. This turns "we should be careful with medical images" from a wiki page into a constraint the pipeline enforces, and it is the kind of control the NIST AI RMF calls for, risk-based handling differentiated by data sensitivity, enforced in the system rather than left to discipline.
Deletion that actually reaches the derived artifacts
A deletion request, GDPR Article 17's right to erasure, a customer offboarding, a retention-policy expiry, is where multimodal systems most often fail quietly, because deletion has to reach not just the original but every derived artifact: the OCR text, the captions, the embeddings in the vector index, the thumbnails, the crops, the transcript, the table JSON, and any copy that landed in a model provider's logs. A system that deletes the original and leaves the embedding in the search index has not deleted the data; the person is still findable, and their content is still retrievable. This is exactly why Chapter 13's derived-artifact table links every artifact to its source by id: deletion becomes a traversal.
def erase_source(source_id, reason: str):
"""Erasure must reach ALL derived artifacts, not just the original."""
artifacts = db.query(
"SELECT artifact_id, kind, payload_uri FROM derived_artifact WHERE source_id = %s",
source_id)
for a in artifacts:
if a.kind == "embedding":
vector_index.delete(a.artifact_id) # remove from search
object_store.delete(a.payload_uri) # remove the artifact bytes
db.delete_artifact(a.artifact_id)
object_store.delete(source_of(source_id).uri) # the original last
db.tombstone_source(source_id, reason) # auditable record of deletion
# Provider-side: issue deletion to any external model provider that logged it.
if was_sent_external(source_id):
provider.request_deletion(source_id)
audit_log.write("erasure_complete", source_id=source_id, artifacts=len(artifacts))The function is deliberately exhaustive because the failure is always an artifact the deletion forgot. The vector index is the most commonly forgotten one, embeddings feel abstract, but an embedding of a face is still that face's data, and a search over it still surfaces the person. The provider-side deletion is the most commonly impossible one, which is why provider_allowed and minimization matter so much upstream: the cheapest way to handle "delete it from the provider" is to never have sent it. Deletion designed as an afterthought reaches the original and misses the corpus; deletion designed into the artifact lineage reaches everything, and produces an auditable tombstone proving it did.
Safety: confident readings of unsafe and high-stakes images
The second half of this chapter is the other kind of risk: not the data the system holds, but the claims it makes about high-stakes images. Two distinct safety problems arise.
First, unsafe input content. Users upload images that are violent, sexual, illegal (including CSAM), or otherwise harmful, sometimes deliberately to probe the system, sometimes incidentally. A multimodal system needs content-safety classification at ingest, both to refuse processing harmful content and to comply with legal obligations around certain categories, and it needs this before the content reaches the general model or the storage layer. The GPT-4V and GPT-4o system cards document extensive safety work precisely because image inputs open an attack surface (and a harm surface) that text inputs do not, including the use of images to carry injected instructions or to elicit unsafe outputs.
Second, and more insidious, confident readings of high-stakes images the system should not be trusted to read. This is where the whole book converges on a safety conclusion. A vision model will produce a fluent, confident interpretation of a medical image, a structural-safety photo, a security-camera frame, and that confidence is uncalibrated to its accuracy (Chapter 1) and unverifiable without an independent check (Chapter 3). The harm of a confident wrong reading scales with the stakes: a wrong meter reading is an annoyance, a missed hazard in a safety inspection is an injury, a wrong interpretation of a medical image is a misdiagnosis. The safety requirement for high-stakes images is therefore not "make the model more accurate"; it is calibrated abstention and human authority: the system must be designed to escalate to a qualified human rather than to auto-act, to present its reading as decision support with grounding (Chapter 8) rather than as a verdict, and to refuse confidently-when-it-should when the input is out of its safe envelope. A safety inspection assistant that auto-closes a hazard report on a model's say-so has converted a fluent guess into a liability; the same assistant that surfaces, prioritizes, and grounds findings for a human inspector has used the model's real value without mistaking it for evidence.
The harm-asymmetry that changes the threshold
A final operational point that the evaluation chapter set up: for high-stakes images, errors are not symmetric, and the system's thresholds must reflect that. Missing a hazard (false negative) and flagging a non-hazard (false positive) have wildly different costs, and a system tuned to maximize overall accuracy will trade them at parity, which is wrong. The threshold for action should be set by the consequence-weighted error, which usually means a multimodal high-stakes system is deliberately tuned toward over-escalation, flag more, abstain more, route more to humans, accepting a higher false-positive (and human-review) rate to drive down the catastrophic false-negative rate. This is a product and risk decision, not a model-quality decision, and it is the right place for the NIST AI RMF's risk-tiering to enter the architecture: classify each multimodal use by its harm profile, and let the harm profile, not the demo's accuracy, set how much the system is allowed to do on its own. The reframe that opened the book, from "can it see?" to "can we prove what it saw, and how wrong might it be?", lands here as a safety principle: for high-stakes images, you do not deploy a model that sees; you deploy a system that knows the limits of its sight and hands the consequential decisions to someone accountable.
Chapter summary
Multimodal media captures far more than the object of truth, and the excess, faces, prescription bottles, children's names, laptop screens, EXIF GPS, is frequently sensitive data the system never meant to collect but now stores, indexes, sends to a provider, and is legally responsible for. Data minimization is therefore an ingest-time discipline: strip metadata, redact and blur regions outside the object of truth, crop to the region (which also serves accuracy and cost), and prefer tight derived artifacts over retained originals, because once full media is in storage, the index, and provider logs, "delete later" is a promise across systems you may not control. Special-category data (health, biometric, minors; GDPR Article 9) needs a sensitivity classification set at ingest that drives retention, access, and a policy gate preventing it from reaching an external model without consent. Deletion (GDPR Article 17) must fan out to every derived artifact, especially the embedding in the vector index, the most forgotten one, and the provider-side copy, the hardest one, which the artifact-lineage links from Chapter 13 make a traversal rather than a guess, producing an auditable tombstone. On safety, two problems arise: unsafe input content needs content classification before the model and storage (the GPT-4V/GPT-4o system cards document the expanded attack and harm surface of images), and confident readings of high-stakes images demand calibrated abstention and human authority rather than auto-action, because the harm of a confident wrong reading scales with the stakes. Because high-stakes errors are asymmetric, thresholds should be set by consequence-weighted error and tuned toward over-escalation, with the NIST AI RMF's risk-tiering deciding how much the system may do alone, which is the book's opening reframe arriving as a safety principle: for high-stakes images, deploy a system that knows the limits of its sight, not a model that sees. This chapter builds on the cost and operational discipline in Cost, Latency, and the Price of Vision Tokens; the playbooks for applying all of these disciplines are collected in The Use Case Field Guide.