The Demo Is Not the System
> **Working claim:** A model that accepts an image, audio clip, or document is not a system that reliably perceives, extracts, or decides. The demo measures the model on inputs it chose.

Working claim: A model that accepts an image, audio clip, or document is not a system that reliably perceives, extracts, or decides. The demo measures the model on inputs it chose. Production measures the whole pipeline on inputs the user chose. The gap between those two is an ingestion, normalization, grounding, evaluation, and review system that the demo quietly assumes away.
The shape of the deception
The claims-team story in the introduction is not an anecdote about one bad weekend; it is the canonical shape of every multimodal project that ships on the strength of a demo. The shape is always the same. A capable model produces a fluent, plausible answer on a clean, well-chosen input. Everyone in the room can verify the answer at a glance, because the input is legible to humans too. The system feels finished. Then real inputs arrive, and they are not clean, not well-chosen, and frequently not even the modality the team designed for, and the model keeps producing fluent, plausible answers, now sometimes wrong, with no change in tone to signal which is which.
The reason this is worth a whole chapter is that the deception is structural, not incidental. It is built into how multimodal capability is demonstrated and benchmarked. The GPT-4V system card is unusually candid about this: it documents that the model can produce confident, detailed descriptions that are incorrect, that it struggles with certain spatial and counting tasks, and that its reliability varies sharply with image type and quality. Those caveats are easy to read and easy to forget the moment a demo works. The benchmark numbers reinforce the forgetting. When a model posts a strong score on an integrated-capability suite like MM-Vet or a discipline-spanning suite like MMMU, it is tempting to read "70%" as "works seven times out of ten on my problem." It does not mean that. It means seven times out of ten on that benchmark's curated, mostly-legible images, evaluated that benchmark's way. Your problem has its own image distribution and its own definition of correct, and the only number that matters is the one you measure on it.
The authors of MMMU-Pro made this concrete in an uncomfortable way. They took MMMU and hardened it, filtering questions a text-only model could answer without the image, adding harder distractor options, and including a "vision-only" setting where the question is embedded inside the image rather than supplied as text. Model scores dropped substantially. The same models, on a benchmark designed to remove the shortcuts, looked much weaker. The lesson is not that the models are bad. The lesson is that headline multimodal performance is fragile to exactly the conditions production guarantees: inputs the model cannot shortcut, details it must actually perceive, and questions it cannot answer from text priors alone.
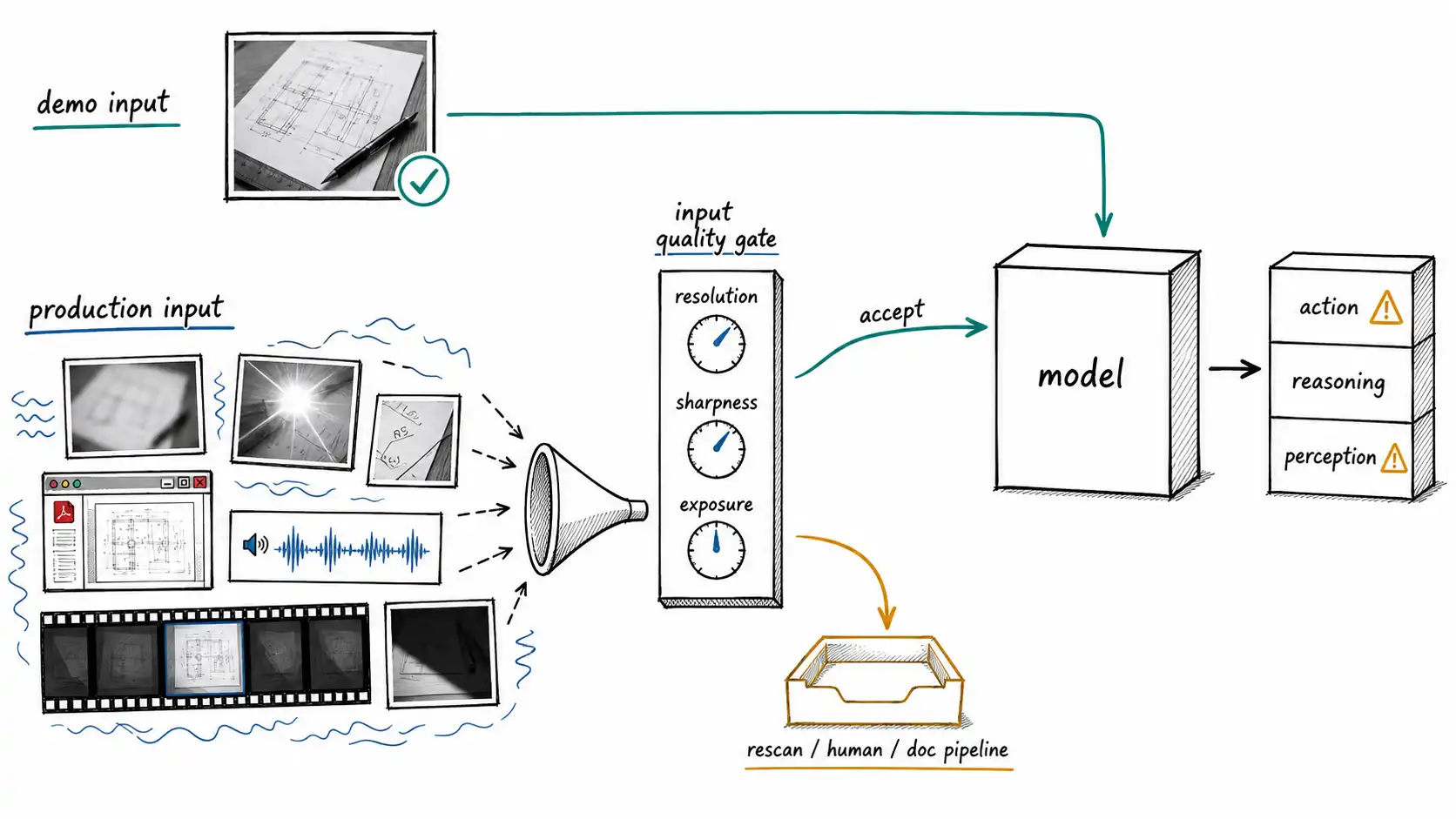
What actually changes when input is not text
It is worth being precise about what is different, because the differences are the source of every new failure mode. Text input arrives as discrete tokens that map directly to the model's vocabulary; what you sent is, more or less, what the model reasons over. Non-text input does not work that way. An image is resized, split into patches or tiles, and encoded into a bounded set of visual tokens. Audio is windowed and turned into spectral features. Video is sampled into frames and then each frame is treated like an image. In every case there is a lossy projection between the raw signal the user supplied and the representation the model reasons over, and the loss is not uniform, it falls hardest on small, low-contrast, off-center, or briefly-present detail, which is frequently exactly the detail that carries the answer.
This produces a clean way to decompose multimodal failure that we will use for the rest of the book. Separate the pipeline into three layers, bottom to top:
- Perception: did the relevant signal survive ingestion and reach the model at all? (The crack was a reflection; the gouge was in shadow; the frame with the dent was never sampled; the quiet word was lost to room noise.)
- Reasoning: given what was perceived, did the model draw the right conclusion? (It saw the damage but mis-estimated severity; it read the chart's bars but added them wrong; it saw two dates and chose the superseded one.)
- Action: given the conclusion, did the surrounding system do the right thing? (It auto-routed a serious claim to fast-track; it posted a wrong invoice value to the ledger; it closed a ticket on a misread screenshot.)
Most teams debug the middle layer, because that is the layer the model owns and the layer that is fun to argue about. Most incidents originate in the bottom and top layers: perception that lost the signal, and action that trusted an unverified conclusion. Keep the three layers separate in your head and in your logs, because a fix at the wrong layer is wasted: a better prompt will not recover a detail that ingestion already destroyed, and a better model will not save you from auto-acting on a confident guess.
The modality-risk matrix
Before any code, it helps to write down what each modality does to you. This matrix is the seed of the MODAL framework's "Limits" question and recurs, refined, throughout the book.
| Modality | What it looks like it is | What it actually is | Primary new blind spot |
|---|---|---|---|
| Text | The thing the model is good at | Discrete tokens, near-lossless | Ambiguity, injected instructions |
| Image | "The model can see it" | A down-sampled, tiled, token-budgeted projection | Tiny / low-contrast / occluded detail vanishes silently |
| Audio | "Just text after transcription" | A time signal with speakers, overlap, accents, noise | A single misheard word inverts meaning; non-speech events lost |
| Video | "Just frames" | Time + space; causality between frames | The answer lives in frames you didn't sample |
| Document (scan/PDF) | "Just an image" or "just its text" | Layout + typography + tables + stamps + page order | Structure and supersession are destroyed by naive extraction |
| Chart / dashboard | "The model can read it" | Estimated values from a rendered figure | Confident numeric values that are simply wrong |
| Screenshot | "An image of a screen" | A document, a chart, or text, mislabeled as a photo | Modality confusion; UI text below OCR resolution |
The table earns its place by being a checklist you run before building. For each input your product will accept, name the modality honestly (a screenshot of a PDF is not a photo), name the object of truth (a field value, not a description), and name the blind spot you are signing up to measure. The claims team would have caught three of their four failures by filling in one row each.
An input-quality gate, before the model
The cheapest, highest-use thing most multimodal systems are missing is a gate that inspects the input before spending a model call on it, not to reject users, but to detect when an input is outside the envelope the system can be trusted on, and to route it to a human, a re-capture prompt, or a different pipeline. The gate does not need the model; it needs cheap signal-quality heuristics.
from dataclasses import dataclass
from enum import Enum
class Modality(str, Enum):
PHOTO = "photo"
SCREENSHOT = "screenshot"
SCANNED_DOC = "scanned_doc"
CHART = "chart"
UNKNOWN = "unknown"
@dataclass
class IngestVerdict:
modality: Modality
accept: bool
reasons: list[str] # why we hesitated, for logs and user messaging
route: str # "model", "rescan_prompt", "human", "doc_pipeline"
def gate_image(img, meta) -> IngestVerdict:
reasons = []
# 1. Resolution: detail below the model's effective patch size is invisible.
if min(img.width, img.height) < 512:
reasons.append("low_resolution")
# 2. Sharpness: variance of the Laplacian is a cheap blur proxy.
if laplacian_variance(img) < BLUR_THRESHOLD:
reasons.append("likely_blurry")
# 3. Exposure: clipped highlights/shadows hide detail (the glare/shadow cases).
if clipped_highlight_fraction(img) > 0.10 or clipped_shadow_fraction(img) > 0.25:
reasons.append("extreme_exposure")
# 4. Modality detection: is this even a photo? (Screenshot-of-PDF case.)
modality = classify_modality(img, meta) # cheap classifier, not the LLM
if modality in (Modality. SCANNED_DOC, Modality. CHART):
return IngestVerdict(modality, accept=True, reasons=reasons,
route="doc_pipeline") # different pipeline entirely
# 5. Decide.
if "likely_blurry" in reasons or "extreme_exposure" in reasons:
return IngestVerdict(modality, accept=False, reasons=reasons,
route="rescan_prompt") # ask the user to retake
return IngestVerdict(modality, accept=True, reasons=reasons, route="model")The exact thresholds are not the point and must be calibrated on your data; the discipline is. Note three design choices. First, the gate detects modality and reroutes, a screenshot of an invoice goes to the document pipeline, not the photo pipeline, which alone would have saved the claims team's third failure. Second, when quality is bad, the best action is often a re-capture prompt ("the photo looks blurry, can you retake it in better light?"), which is cheaper, faster, and more accurate than any model heuristic for fixing a bad image. Third, every hesitation is logged as a structured reason, so that later you can measure how often inputs fall outside the envelope, a number most teams never know.
A failure taxonomy you can log against
When something does go wrong, "the model was wrong" is too coarse to act on. Adopt a fixed taxonomy and tag every reviewed failure with exactly one primary class. The classes map to the three layers and to the modalities:
| Class | Layer | Example | The fix lives in |
|---|---|---|---|
| Perception error | Perception | Damage in shadow read as no damage | Ingestion, resolution, lighting, gate |
| OCR error | Perception | "5,100" read as "5,700" | OCR engine, preprocessing, crop |
| Grounding error | Reasoning | Right value, attributed to wrong field/region | Layout parsing, box alignment |
| Temporal error | Perception | Event missed because its frame wasn't sampled | Frame sampling, shot detection |
| Reasoning error | Reasoning | Bars read correctly, summed wrong | Prompt, decomposition, tool use |
| Policy error | Action | Acted on a low-confidence answer | Thresholds, review gates |
The taxonomy is load-bearing because each class has a different owner and a different fix, and because the distribution of classes tells you where to invest. A system whose failures are 60% perception errors does not need a smarter model; it needs better ingestion. A system whose failures are 60% policy errors does not need better perception; it needs to stop auto-acting on low-confidence outputs. You cannot see that distribution unless you log it.
Why visual confidence is not textual confidence
There is a subtler reason demos mislead, and it deserves naming because it underlies the whole book. A model's fluency is uncorrelated with its accuracy on perception. When a language-only model is unsure about a fact, it sometimes hedges. When a multimodal model cannot make out a detail in a down-sampled image, it does not usually say "the resolution is too low for me to read that meter"; it produces a confident reading, because the training signal rewards plausible, well-formed answers and the model has no privileged access to its own perceptual uncertainty. Both the GPT-4V system card and the GPT-4o system card describe exactly this pattern of confident errors on details and counts.
This is why the book's second motif, a vision answer is not evidence until it is verified, is not a slogan but an architectural requirement. You cannot use the model's tone as a confidence signal, and you usually cannot use its self-reported confidence either. The trustworthy confidence signals are external: input-quality scores from the gate, agreement between the model's reading and an independent structured extraction, agreement across multiple frames or multiple crops, and whether the claim can be grounded to a specific region a human could check. We will build all of these. For now, hold the principle: in a text system, a fluent answer is at least an answer in the medium it was trained to be reliable in; in a multimodal system, a fluent answer about a blurry image is fluent text about something the model may never have clearly seen.
The reframe: from "can it see?" to "can we prove what it saw?"
The claims team's recovery did not start with a better model. It started with a reframe. They stopped asking "can the model see the damage?" and started asking a chain of harder questions: Is this input in our quality envelope? Is it the modality we think? What exactly are we extracting, a severity band, a part list, as opposed to a description? Can each extracted item be tied to a region of the image a human reviewer could open? How wrong is each item allowed to be before a human must look? And how often, sliced by lighting and device, are we wrong? Those questions are the MODAL framework, and answering them turned a demo into a system that could fail safely, routing the night-time glare to re-capture, the screenshot to the document pipeline, the shadowed gouge and the low-confidence severity to human review, and the video to a frame sampler that no longer skipped the door.
None of those questions are about whether the model can see. All of them are about whether the system can prove what it saw, locate it, and bound its own error. That is the difference between a demo and a system, and it is the whole book in miniature.
Chapter summary
Multimodal demos deceive structurally, not incidentally: a capable model produces fluent answers on clean, self-chosen inputs, and keeps producing fluent answers, now sometimes wrong, on the messy, user-chosen inputs production guarantees. Benchmark scores reinforce the illusion; MMMU-Pro showed that hardening a benchmark to remove shortcuts drops the same models sharply, because production removes the same shortcuts. The root cause is that every non-text input passes through a lossy projection, resized and tiled images, windowed audio, sampled video, that destroys exactly the small, faint, off-center, or brief detail that often carries the answer, while the model answers with undiminished fluency. Decompose failure into three layers, perception, reasoning, action, and note that incidents cluster at the bottom (lost signal) and top (acting on a guess), not the middle that teams love to debug. Build a modality-risk matrix before building anything; add an input-quality gate that detects modality and reroutes or asks for a re-capture before spending a model call; and tag every failure with a fixed taxonomy so the distribution of classes tells you whether to invest in ingestion, perception, grounding, or guardrails. Above all, internalize that visual confidence is not textual confidence: a fluent description of a blurry image is fluent text about something the model may never have clearly seen, which is why the rest of this book is about proving what the system saw rather than asking whether it can see. This chapter follows the framing set in Introduction: The Photo of the Bumper; the next chapter extends the argument modality by modality: Every Modality Brings Its Own Blind Spots.