Production Architecture for Multimodal Systems
> **Working claim:** A multimodal system in production is mostly a pipeline for turning raw media into versioned, provenance-linked derived artifacts and keeping them consistent as models and extraction logic change.

Working claim: A multimodal system in production is mostly a pipeline for turning raw media into versioned, provenance-linked derived artifacts and keeping them consistent as models and extraction logic change. The model call is a small, replaceable part. The hard parts are storage, versioning, reprocessing, observability, and the incident runbook, and a team that designs only the model call has designed the least durable component.
The reprocessing that broke everything quietly
A document-AI company upgraded its vision-language model, a genuinely better model, higher accuracy on their evals, and rolled it out. New documents were processed by the new model; old documents kept their old extractions. Six weeks later, a customer noticed that two invoices from the same supplier, uploaded a month apart, had been extracted differently: one had the freight charge as a line item, one folded it into the total, because the two model versions handled that template differently. Neither extraction was flagged as belonging to a particular model version. When the customer asked which was correct, the company could not even reconstruct which model had produced which extraction, because the derived artifacts carried no version stamp. The upgrade had silently created an inconsistent corpus, and the lack of versioning made the inconsistency both invisible until a customer found it and impossible to fix cleanly afterward.
This is the defining operational fact of multimodal systems: the durable thing is not the answer, it is the pile of derived artifacts, and that pile is produced by extraction logic and models that change over time. A multimodal system accumulates, for every piece of raw media, a growing set of derivatives, extracted text, OCR with boxes, captions, embeddings, thumbnails, crops, transcripts, table JSON, frame indexes, each produced by some version of some pipeline. Treating these as ephemeral outputs of a single model call, rather than as versioned assets with lineage, is the architectural mistake that turns a model upgrade into a quiet corpus-consistency incident. The model call is the easy, swappable part; the artifact lifecycle is the system.
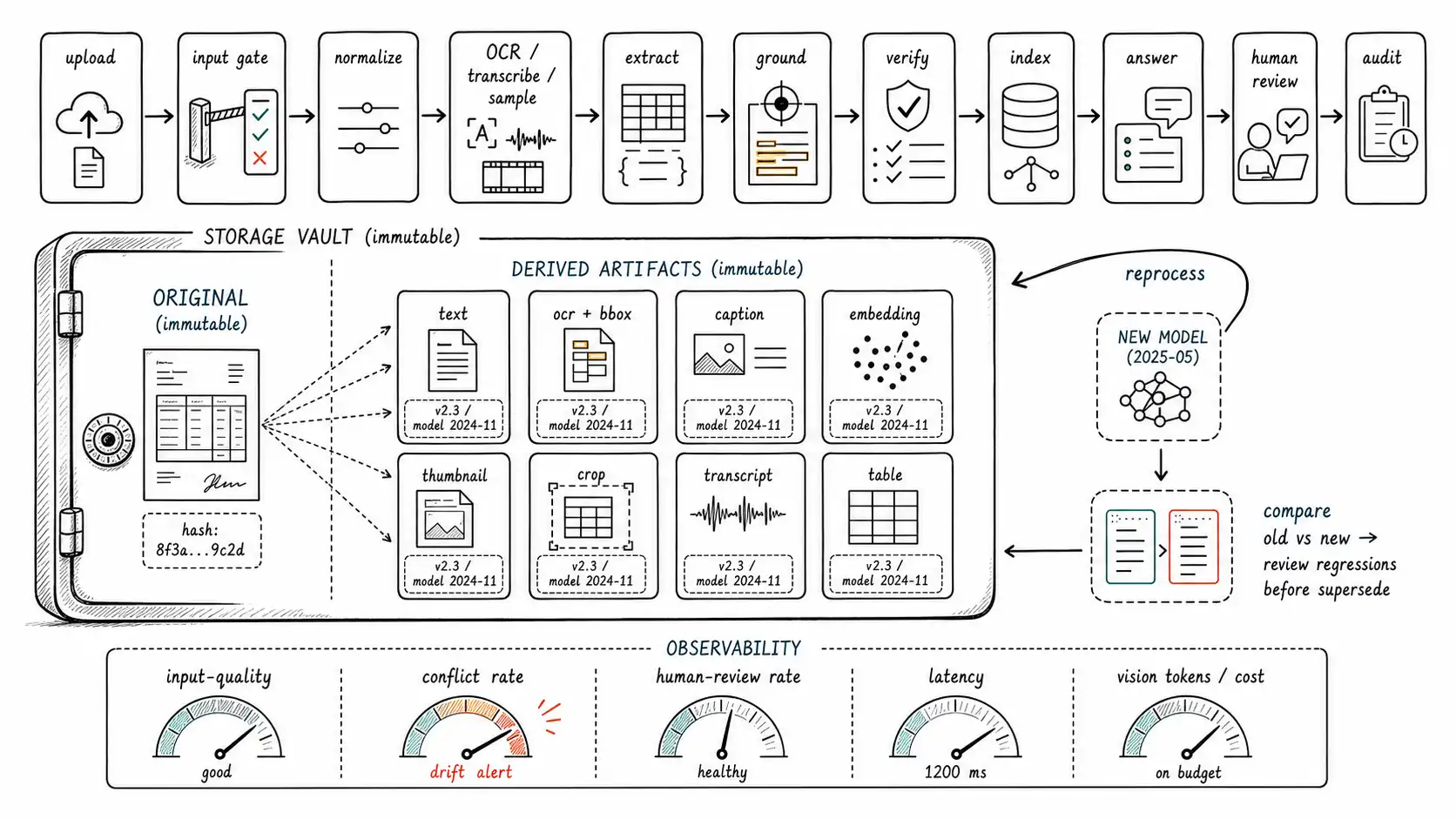
Storage: originals and derived artifacts, linked by hash
The foundation is a storage layout that keeps originals immutable and links every derived artifact back to the exact bytes it came from. The original is the source of truth; everything else is reproducible from it given a pipeline version. Linking by content hash means a derived artifact can always be traced to its origin and a re-derivation can always be checked against it.
-- Originals are immutable; everything derived links back by hash + version.
CREATE TABLE source_media (
source_id UUID PRIMARY KEY,
content_hash TEXT NOT NULL UNIQUE, -- sha256 of the raw bytes
uri TEXT NOT NULL, -- object store location
modality TEXT NOT NULL, -- image | document | audio | video
mime_type TEXT NOT NULL,
bytes BIGINT NOT NULL,
uploaded_at TIMESTAMPTZ NOT NULL,
tenant_id UUID NOT NULL, -- for permission + deletion scope
retention_class TEXT NOT NULL -- drives deletion policy (Ch. 15)
);
CREATE TABLE derived_artifact (
artifact_id UUID PRIMARY KEY,
source_id UUID NOT NULL REFERENCES source_media(source_id),
source_hash TEXT NOT NULL, -- which bytes (must match source)
kind TEXT NOT NULL, -- ocr | layout | caption | embedding
-- | thumbnail | crop | transcript | table
pipeline_name TEXT NOT NULL, -- e.g."doc-extract"
pipeline_version TEXT NOT NULL, -- e.g."2.3.1" (CODE version)
model_id TEXT, -- e.g."vlm-2024-11" (MODEL version)
payload_uri TEXT NOT NULL, -- where the artifact lives
region JSONB, -- page+bbox / offset / frame (Ch. 8)
created_at TIMESTAMPTZ NOT NULL,
superseded_by UUID REFERENCES derived_artifact(artifact_id)
);
CREATE INDEX ON derived_artifact (source_id, kind);
CREATE INDEX ON derived_artifact (pipeline_version, model_id); -- find by versionEvery derived artifact records which code version and which model produced it. This single discipline is what the document-AI company lacked: with it, the inconsistent invoices are immediately explicable ("one was extracted by doc-extract 2.2 on vlm-2024-08, the other by 2.3 on vlm-2024-11"), the inconsistency is queryable before a customer finds it ("show me all sources with extractions from more than one model version"), and a reprocessing job can systematically bring the old corpus up to the new version with a full record of what changed. The superseded_by link preserves the old extraction for audit while marking the current one: the same supersession pattern documents use, now applied to the system's own outputs.
Versioning and reprocessing as a first-class operation
Because models and pipelines improve, reprocessing the existing corpus is not an exception; it is a standing operation that must be designed, not improvised during an upgrade. The questions a reprocessing design must answer: When a model improves, do you reprocess everything (consistency, at cost) or only on demand (cheaper, inconsistent)? How do you compare old and new extractions to catch regressions (the new model is better on average but worse on one template)? How do you avoid reprocessing breaking grounding (the boxes must still point at the right regions)?
The pattern that works is to treat each extraction as reproducible given (source bytes, pipeline version, model id) and to make reprocessing a job that produces new derived artifacts linked to the same source, comparing each new artifact to the old before superseding. The comparison is an eval (Chapter 12): run the new pipeline against the golden set and against a sample of the real corpus, diff the outputs, and surface the cases where new and old disagree for human review before bulk-superseding. A model upgrade is thus gated by the same slice-aware eval that gates a launch, and the corpus migrates with a record of every changed value. The GPT-4o system card and GPT-4V system card are reminders that model behavior shifts meaningfully between versions; treating that shift as a managed reprocessing event rather than a silent rollout is the difference between an upgrade and an incident.
The processing event schema for observability
A multimodal pipeline has more steps than a text one, ingest, gate, normalize, OCR/transcribe, extract, ground, verify, index, and each can fail or degrade independently. Observability requires a structured event per processing step, so that when accuracy drops you can see which step drifted rather than guessing.
{
"event": "artifact_processed",
"source_id": "8c1f...",
"tenant_id": "t-204",
"modality": "document",
"pipeline_version": "2.3.1",
"model_id": "vlm-2024-11",
"steps": [
{ "step": "input_gate", "outcome": "accept", "quality": {"blur": 0.12, "res": "ok"} },
{ "step": "ocr", "outcome": "ok", "char_conf_mean": 0.97, "ms": 410 },
{ "step": "extract", "outcome": "ok", "fields_found": 7, "ms": 1300 },
{ "step": "verify", "outcome": "conflict","field": "total", "ms": 80 },
{ "step": "disposition", "outcome": "human_review", "reason": "verify_conflict" }
],
"total_ms": 1800,
"vision_tokens": 1430,
"cost_usd": 0.021
}This event makes the operationally important quantities first-class: the input-quality distribution (how often inputs fail the gate, a leading indicator of upstream problems like a new low-quality source), the verification/conflict rate (how often claims fail their checks, the honest reliability signal from Chapter 3), the human-review rate (the automation reality), per-step latency, and per-document cost in vision tokens (Chapter 14). Dashboards built on these answer the questions that matter in production: Is the conflict rate climbing (model or input drift)? Is one tenant's input-quality distribution far worse than others (a slice problem)? Did the latest pipeline version change the human-review rate? The NIST AI RMF frames this as continuous measurement and monitoring of AI risk, and for multimodal systems the per-step event is the unit that makes such monitoring possible.
Human-in-the-loop as designed capacity, not a fallback
Every prior chapter has routed something to human review, out-of-envelope inputs, conflicts, handwriting, low-confidence decision words, high-stakes claims. In production, human review is not a safety valve you bolt on; it is a designed capacity with a budget, a queue, and an interface, and it has to be sized. The verification discipline gives you the number: the human-review rate is the fraction of inputs whose claims do not reach verified, and it is measurable before launch from the eval set. If 20% of invoices will route to review, and you process 10, 000 a day, you need reviewers for 2,000 reviews a day, and the review interface must be efficient, which is exactly what grounding (Chapter 8) provides: a reviewer confirming a highlighted box clears a case in seconds, where a reviewer reading a whole document does not. A system designed for human review at scale has visual citations, a triage order (high-stakes and high-conflict first), and a feedback path where reviewer corrections become eval cases. A system that treats review as an afterthought discovers at launch that its review rate is unaffordable and either staffs it in a panic or quietly raises its automation threshold past what is safe.
Latency, batching, and the shape of the workload
Multimodal processing is heavier than text, and the latency budget shapes the architecture. Two workload shapes dominate, and they want different designs. Interactive (a user uploads a screenshot and waits for an answer) needs low latency: process synchronously, but do the cheap input gate first so you fail fast on bad inputs, and crop aggressively so you send fewer, more-relevant vision tokens (Chapter 14). Batch (a nightly run over a document backlog, a corpus reprocessing) tolerates latency and should maximize throughput: batch the model calls, process modalities in parallel, and checkpoint so a failure does not restart the whole run. Many systems are both, interactive for new uploads, batch for reprocessing, and the artifact storage above is what lets them share extraction logic. The Gemini 1.5 report's very large contexts change the batch calculus for long media (you can process a whole long document or video in fewer calls), but they raise per-call latency, so the interactive path still wants retrieval over a pre-built index rather than stuffing everything into one slow call.
The incident runbook for wrong extraction
Because the unique multimodal incident is "the system extracted the wrong value from a piece of media and acted on it, " the runbook for it should be pre-written, and it has a specific shape that the architecture above enables. When a wrong extraction is reported: (1) reproduce, fetch the original by hash and re-run the exact pipeline version and model that produced the bad artifact, confirming the failure is in the system and not a data-entry error; (2) localize, use the per-step event to find the failing layer (gate, OCR, extract, verify) and the failure taxonomy class from Chapter 1; (3) assess blast radius, query the derived-artifact table for all extractions from the same pipeline_version/model_id on the same template or slice, because one wrong extraction usually means a slice is broken, not a single document; (4) contain, route the affected slice to human review and supersede the bad artifacts; (5) fix and reprocess, fix the layer, gate the fix through slice-aware eval (the DocVQA discipline: test across document types and templates, not just overall accuracy), and reprocess the affected corpus with the comparison-before-supersede discipline; (6) regression, add the case (and its slice) to the golden set so it cannot recur silently. Every step in this runbook depends on something the architecture provided: immutable originals, version-stamped artifacts, per-step events, supersession, slice-aware eval, which is the chapter's argument in one paragraph: the production system is the artifact lifecycle and its observability, and the model is a part you can swap. This chapter builds on the evaluation discipline in Evaluation: Seeing Is Not Verifying; the economics of running this pipeline at scale are the subject of Cost, Latency, and the Price of Vision Tokens.
Chapter summary
In production, the durable thing is not the answer but the growing pile of derived artifacts (text, OCR-with-boxes, captions, embeddings, thumbnails, crops, transcripts, table JSON, frame indexes), produced by extraction logic and models that change over time, so the defining architecture is the artifact lifecycle, and the model call is the small, swappable part. The defining incident is a silent one: a model upgrade re-extracts new documents differently from old ones, and without version stamps the inconsistency is invisible until a customer finds it and unfixable afterward. The fix is storage that keeps originals immutable and links every derived artifact to its source by content hash and records the producing code version and model id, making inconsistency queryable and reprocessing systematic. Reprocessing is a first-class standing operation gated by the same slice-aware eval that gates launches, comparing new extractions to old and reviewing regressions before bulk-superseding. A per-step processing event makes input-quality, conflict rate, human-review rate, latency, and per-document vision-token cost first-class for observability and drift detection, in line with the NIST AI RMF's continuous-monitoring posture. Human review is designed capacity sized from the measurable review rate and made efficient by grounding-based visual citations, not an afterthought. Latency budgets split the workload into interactive (gate first, crop aggressively, retrieve over an index) and batch (parallelize, batch, checkpoint). And the pre-written runbook for wrong extraction, reproduce, localize, assess blast radius across the slice, contain, fix-and-reprocess, regress, depends entirely on immutable originals, version-stamped artifacts, per-step events, and supersession, which is the chapter's thesis made operational.