A Citation Is Not Proof
> **Working claim: ** A citation is a *claim about the relationship between an assertion and a source*. Models are excellent at producing the *form* of that claim and terrible, unaided, at guaranteeing its *truth*.

Citation hallucination is dangerous because a real-looking citation can transfer trust without proving the cited span supports the claim.
Key Takeaways
- A citation is a claim about a relationship between an assertion and a source, not proof by itself.
- Fabricated, misattributed, over-extended, and stale citations need different detectors.
- The fix is to derive the citation from a verified span, not let the model write it as decoration.
- Measure citation precision and citation recall separately because laundering and uncited assertion fail in opposite directions.
Read this with RAG hallucination failures, The Compression Press, and rag evaluation.
**Working claim: ** A citation is a claim about the relationship between an assertion and a source. Models are excellent at producing the form of that claim and terrible, unaided, at guaranteeing its truth. Asking a model to "cite its sources" produces citations, not grounding. A citation is proof only when it is evidence-bound: derived from a verified span, not generated alongside the claim it decorates.
The most reassuring failure mode
Of all hallucination types, the cited falsehood is the most dangerous, precisely because it is the most reassuring. A bare claim invites skepticism. A claim with "(Smith v. Jones, 412 F.3d 884)" after it invites trust, because a citation signals that someone did the work of checking. The whole social function of a citation is to transfer the reader's verification burden to a source. When the model produces a citation it did not actually derive from evidence, it is exploiting that social function, not deliberately, but mechanically, because it learned the form of grounded writing, and the form includes citations.
This is why "ask the model to cite its sources" is among the most popular and most misleading mitigations. It works on the part of the problem that is easy (producing citation-shaped text) and not on the part that is hard (ensuring the citation supports the claim). Teams add it, see citations appear, and conclude the system is now grounded. The litigation team had citations. The citations were perfect. The holdings were invented. **Citations measure effort signaling, not grounding, unless the system enforces the binding. **
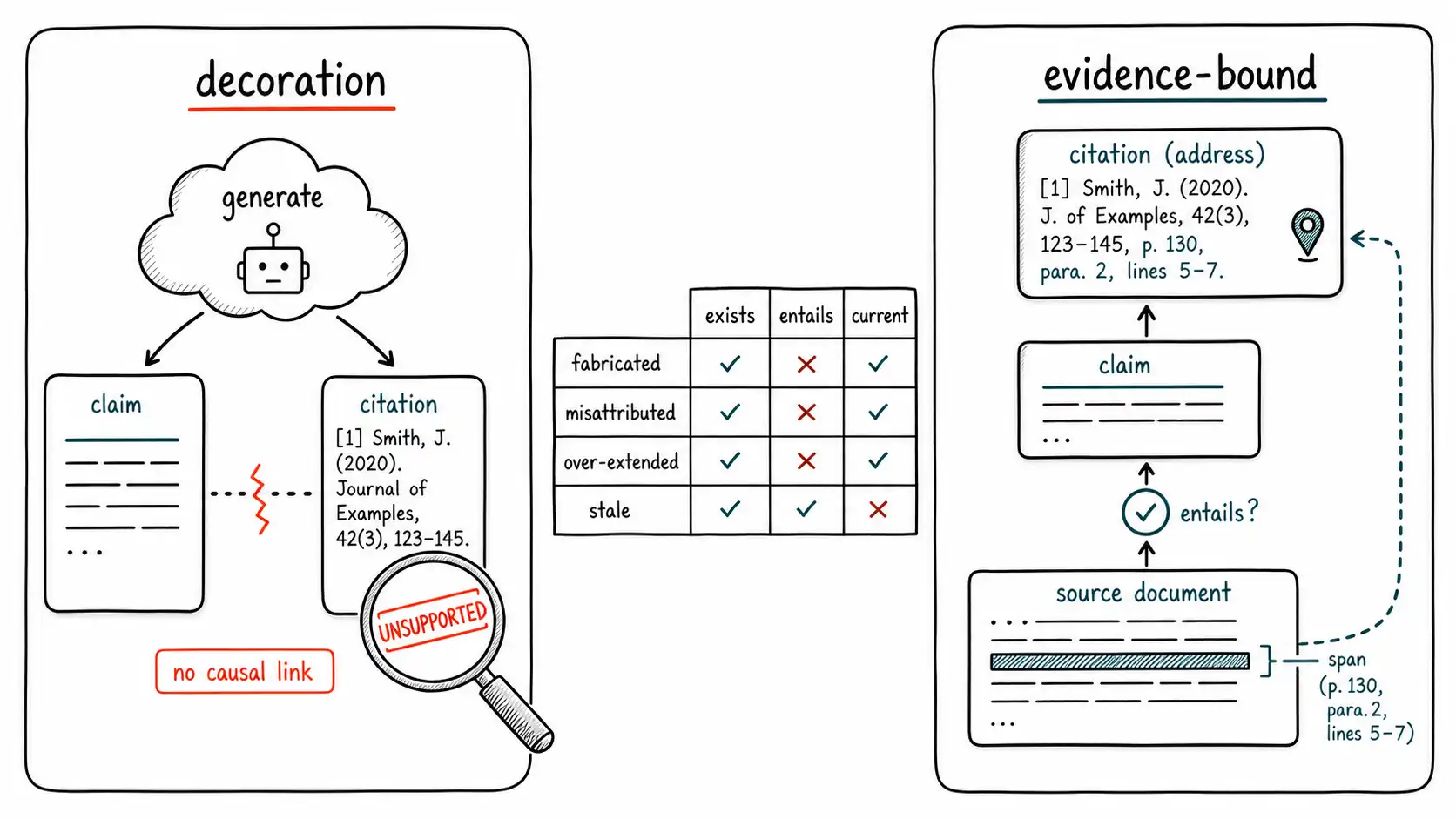
Four ways a citation lies
It helps to be precise about the distinct ways a citation can be wrong, because they have different detectors.
The fabricated citation points at a source that does not exist. This is the easiest to catch, you resolve the citation against the source store and it is not there. It is also the one most likely to be caught by users, which is why, perversely, it is becoming less common: as models improve, they fabricate fewer non-existent sources and more misattributed real ones, trading an easily-caught failure for a hard-to-catch one.
The misattributed citation points at a real source that exists but does not support the claim, the litigation failure. The source resolves; an existence check passes; only an entailment check against the cited text catches it. This is citation laundering, and it is the dominant citation failure in well-built systems because the easy failures have been engineered out.
The over-extended citation points at a real source that supports part of the claim but not the whole. The source says "the drug was approved"; the claim says "the drug was approved for pediatric use." The citation is partly earned, which is the hardest case for both humans and automated checks, because the source is genuinely relevant and a quick read confirms the topic. Catching it requires checking entailment of every atomic claim, not the sentence as a whole, the FActScore decomposition discipline from Chapter 2.
The stale citation points at a real source that supported the claim when it was current and no longer does. The exclusion clause cited from the superseded policy is a stale citation. It passes existence and entailment against the cited text; it fails only an Authority/currency check. This is the citation that survives every span-level check and is still wrong, which is why CLAIM separates Authority (A) from Inference (I): a citation can be perfectly entailed and perfectly obsolete.
| Citation failure | Source exists? | Span entails claim? | Source current? | Detector |
|---|---|---|---|---|
| Fabricated | No | - | - | Resolve against source store |
| Misattributed | Yes | No | - | Entailment: span ⊨ claim |
| Over-extended | Yes | Partly | - | Per-atomic-claim entailment |
| Stale | Yes | Yes | No | Currency / authority check |
The inversion that makes a citation proof
Chapter 1 introduced the structural fix and this chapter operationalizes it. In most deployed systems, the data flow is:
claim → (model also writes) citationThe model generates the claim and, alongside it, a citation. The two are siblings, both products of the same fluent generation, and there is no causal link between them, which is exactly why the citation can be perfect while the claim is invented. The fix is to invert the dependency:
evidence span → claim → citation (derived from the span)The citation must be a function of the span that was verified to support the claim. You cannot produce the citation without first producing the span; the citation is the span's address. This is the difference between a system that displays citations and a system whose citations are load-bearing. Concretely:
@dataclass
class BoundCitation:
claim: str
source_id: str
span_text: str # the exact span, retrieved -- not paraphrased by the model
span_offset: tuple[int, int]
entailment: str # must be "entails" to be shown as support
source_valid_now: bool
def bind_citations(claims, evidence, entailer, source_index) -> list[BoundCitation]:
"""Build citations FROM verified spans. A claim with no entailing,
current span gets NO citation -- and is flagged for the M-step."""
bound = []
for claim in claims:
span = best_span(claim.text, evidence)
if span is None:
claim.label = "UNLINKED"; continue
relation = entailer.classify(span.text, claim.text)
if relation!= "entails":
claim.label = "OVERREACH" if relation == "neutral" else "CONTRADICTED"
continue
src = source_index[span.source_id]
bound.append(BoundCitation(
claim=claim.text, source_id=span.source_id, span_text=span.text,
span_offset=span.offset, entailment="entails",
source_valid_now=(not src.superseded and src.is_current()),))
return boundNote what this code refuses to do: it never lets the model write the citation string. The citation is constructed from the span the verifier confirmed. A claim that cannot be bound to an entailing, current span gets no citation and is handed to the mitigation step, to be dropped, hedged, or escalated. The system can no longer display a citation it has not earned. This is the entire content of "evidence-bound citation, " and it converts the most dangerous failure mode into a non-event by construction.
Quoting versus paraphrasing the span
A subtle but important design choice: should the system show the exact span text, or the model's paraphrase of it? Show the exact span. The moment you let the model paraphrase the supporting evidence, you reopen the door to extrinsic hallucination inside the citation itself, the model "summarizes" the span in a way that drifts toward the claim it wants to support. The ALCE work on citation generation evaluates exactly this axis, citation precision (does the cited passage support the statement) and recall (are all statements citation-supported), and the cleanest way to keep precision high is to make the citation point at verbatim source text the user can read, not at the model's gloss of it. A user who can see the exact span can verify the binding themselves; a user who sees only a paraphrase is trusting the model twice (see Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Lewis et al.) for the grounding architecture that citation binding completes).
Measuring citation quality
Citation quality is measurable and belongs in the eval suite as two numbers, mirroring ALCE and RAGAS:
def citation_precision(answer_claims, entailer) -> float:
"""Of claims that carry a citation, what fraction are actually entailed
by the cited span? Low precision = laundering / over-extension."""
cited = [c for c in answer_claims if c.source_id is not None]
if not cited:
return 1.0
supported = sum(1 for c in cited
if entailer.classify(c.supporting_span, c.text) == "entails")
return supported / len(cited)
def citation_recall(answer_claims) -> float:
"""Of claims that REQUIRE a citation (factual, non-trivial),
what fraction actually carry one? Low recall = uncited assertions."""
need = [c for c in answer_claims if c.requires_citation]
if not need:
return 1.0
return sum(1 for c in need if c.source_id is not None) / len(need)The two numbers fail in opposite directions and you need both. High recall with low precision is the citation-laundering regime: everything is cited, the citations do not hold. High precision with low recall is the under-citation regime: the citations that exist are good, but many factual claims float uncited, each an unverified assertion. The target is high on both, and tracking them separately tells you which way a regression went.
When citations are not enough: and when they are too much
Two boundary cases keep this honest.
Citations are not enough for synthesized conclusions. If the answer is a judgment that draws on several sources, "based on these three filings, the company is likely to miss guidance", no single span entails the conclusion, because the conclusion is an inference. The right design cites the premises (the spans that support the inputs) and flags the conclusion as inference, ideally with the model's reasoning exposed so a human can check the step. Citing premises while the conclusion floats is honest; citing the conclusion to a premise that does not entail it is laundering.
Citations can also be too much. Forcing a citation on every sentence, including the connective tissue, the restatements, the genuinely common knowledge, trains users to ignore citations through sheer volume, and pressures the model toward over-extension (it will find some span to point at). The requires_citation flag in the recall metric matters: citation is for non-trivial factual claims, not for every clause. A system that cites well cites selectively and accurately, which is more trustworthy than one that cites everything and approximately.
Chapter summary
A citation is a claim about the relationship between an assertion and a source, and models are superb at producing the form of that claim while unable, unaided, to guarantee its truth, so "ask the model to cite its sources" produces citation-shaped text, not grounding. Citations lie in four distinct ways with four distinct detectors: fabricated (resolve against the store), misattributed (entailment check), over-extended (per-atomic-claim entailment), and stale (currency/authority check), and the easy failures are being engineered out, leaving the hard ones (misattribution, over-extension, staleness) dominant in well-built systems. The structural fix is the inversion: build the citation from the verified span (evidence → claim → citation) rather than letting the model emit it alongside the claim, and show the verbatim span rather than the model's paraphrase so the user can verify the binding directly. Measure citation precision and recall separately, because they fail in opposite directions: high-recall/low-precision is laundering, high-precision/low-recall is uncited assertion. Two honest boundaries: cite premises and flag conclusions as inference rather than laundering a conclusion onto a premise; and cite selectively on non-trivial claims, because over-citation trains users to ignore citations and pressures the model to over-extend. The prior chapter showed when retrieval fails before generation begins and how those upstream failures amplify citation errors; the next movement leaves question answering for a failure mode teams forget: the hallucinations that summaries and transformations introduce in The Compression Press.