When Retrieval Fails Before Generation Begins
> **Working claim: ** "Add RAG" is the most over-prescribed cure in the field because it treats hallucination as a knowledge problem when it is often a *grounding* problem.

RAG hallucination often starts before generation, when the system drops a constraint, misses the right span, buries evidence, or retrieves stale context.
Key Takeaways
- Adding retrieval does not remove hallucination; it moves the failure surface into rewrite, retrieve, rerank, assemble, generate, and cite stages.
- Context recall and context precision belong upstream of final-answer grading.
- Hybrid retrieval, currency metadata, and position-aware assembly solve different rows of the failure matrix.
- If the right evidence was never retrieved, no truthfulness prompt can save the answer.
Read this with model calibration, citation laundering, and why RAG pipelines fail in month three.
**Working claim: ** "Add RAG" is the most over-prescribed cure in the field because it treats hallucination as a knowledge problem when it is often a grounding problem. Retrieval introduces its own family of failures, miss, noise, conflict, staleness, that all happen before the model generates a token, plus a separate family that happens during generation when the model ignores or over-reads what it was given. Most "RAG still hallucinates" complaints are one of these eight failures, misnamed.
The promise and the bait-and-switch
Retrieval-augmented generation was a genuine advance: instead of relying on what the model memorized, you retrieve relevant passages and put them in the context, so the model can ground its answer in current, specific, governable text. Done well, it converts a missing-knowledge failure (Chapter 4) into a retrievable one and gives you a corpus you can curate, which, per Chapter 2, is how you turn the truth problem into a faithfulness problem you can actually manage.
The bait-and-switch is the belief that adding retrieval removes hallucination. It does not. It replaces one failure mode (the model guesses from parametric memory) with a pipeline of new ones, each of which can produce a confident wrong answer, and several of which are worse than the original because the wrong answer now arrives wrapped in retrieved-looking authority. The mental model to install: RAG does not eliminate the place where hallucination can occur. It moves the failure surface from one box (the model) to six (rewrite, retrieve, rerank, assemble, generate, cite), and gives you the chance to put a detector on each.
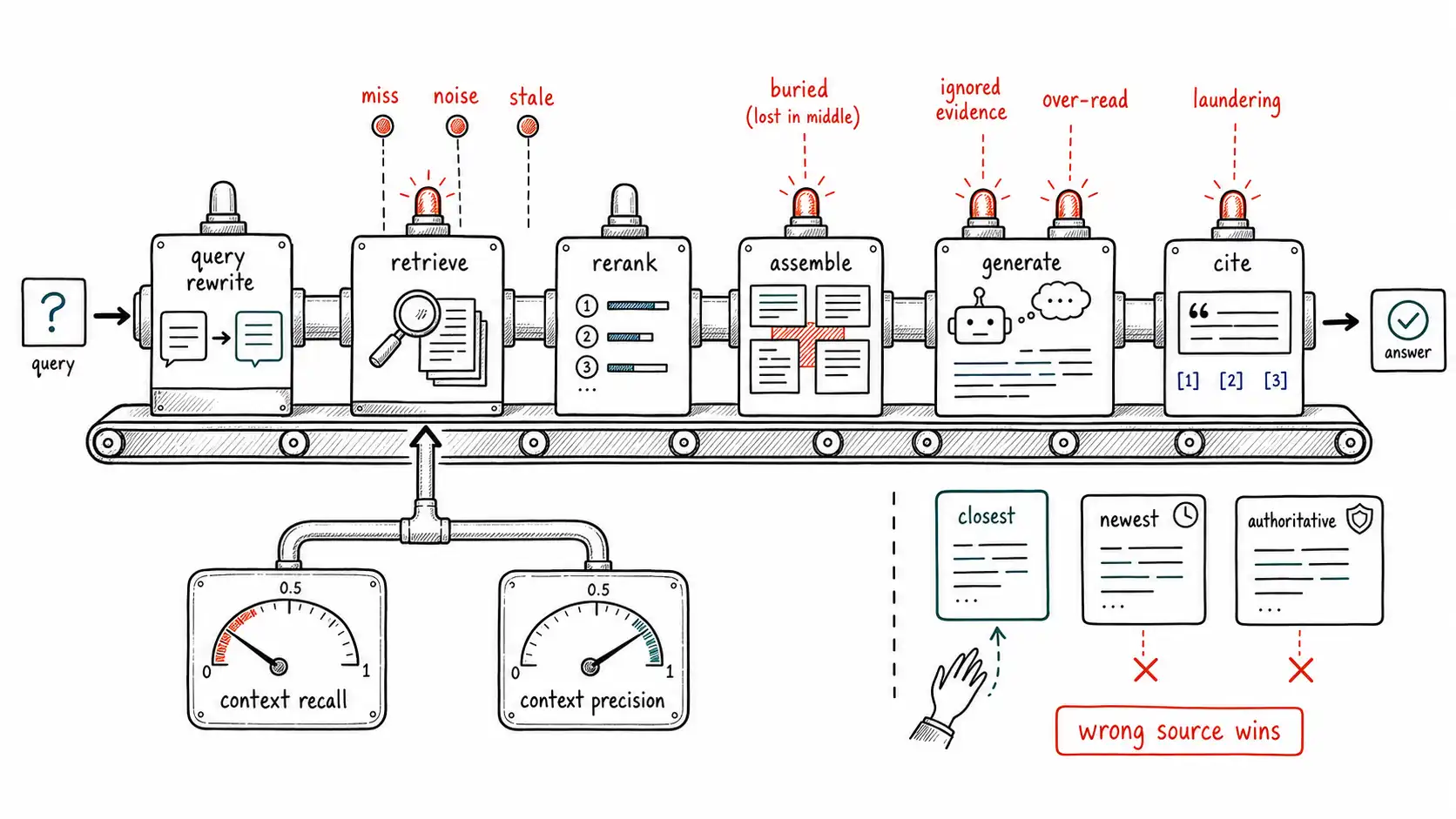
The RAG failure matrix
This is the central artifact of the chapter. Each row is a distinct failure with a distinct symptom, cause, detector, and fix. The discipline is to localize a RAG failure to one row before reaching for a remedy, exactly as Chapter 1 localized the litigation failure to a station.
| Stage | Failure | Symptom | Detector | First fix |
|---|---|---|---|---|
| Query rewrite | Constraint dropped | Answer addresses a narrower/different question | Compare entities/constraints in query vs. rewrite | Preserve constraints; multi-query |
| Retrieve | Miss | Right doc exists, not returned | Context recall vs. gold span | Better embeddings; hybrid (BM25 + dense) |
| Retrieve | Noise | Irrelevant passages included | Context precision | Higher threshold; rerank; fewer k |
| Retrieve | Conflict | Sources disagree; answer picks one | Cross-passage contradiction check | Surface conflict; currency rule |
| Retrieve | Staleness | Old version retrieved | Currency check vs. doc date | Filter by validity; prefer current |
| Chunk | Span split | Supporting fact straddles two chunks | Recall with chunk-boundary analysis | Overlap; semantic chunking |
| Rerank | Mis-rank | Best passage demoted below cutoff | Recall@k before/after rerank | Better reranker; raise k pre-rerank |
| Assemble | Position | Relevant passage buried mid-context | Positional sweep | Bracket strong passages at edges |
| Generate | Ignored evidence | Right passage present, answer ignores it | Faithfulness + attribution | Source-aware prompt; force citations |
| Generate | Over-read | Answer claims more than passage supports | Entailment / claim coverage | Claim-to-span verification |
| Cite | Laundering | Real citation, unsupported claim | Span ⊨ claim | Bind citation to verified span |
The matrix makes a point that is easy to lose: only the bottom three rows are "the model hallucinating" in any direct sense. The top eight are retrieval and assembly failures, and they are invisible to any amount of prompt engineering or model upgrading. If your right document was never retrieved, no instruction to "use only the provided context" can save you, the context does not contain the answer.
The pre-generation failures, in detail
Retrieval miss is the failure that masquerades most convincingly as a model problem. The right document exists in your corpus; the query did not surface it, usually because of a vocabulary mismatch, the user asked about "termination for convenience" and the clause was written as "either party may cancel without cause." Dense retrieval (DPR) helps with synonymy but is not magic; pure-dense systems still miss exact identifiers, rare terms, and codes that lexical search (BM25) would catch. This is why hybrid retrieval, combining dense and lexical signals, is the most reliable single improvement: it covers each method's blind spot. The detector is context recall: of the spans needed to answer, what fraction were retrieved? A low context recall means the model is being asked to answer from evidence that does not contain the answer, and any answer it gives is a hallucination by construction.
Retrieval noise is the opposite failure and it is underrated because it does not feel like a failure, you returned more context, surely that is safer? It is not. Irrelevant passages dilute attention and supply distractors the model may latch onto, and the Lost in the Middle effect means the more you stuff in, the deeper the relevant passage sinks. The detector is context precision: of what was retrieved, what fraction was actually relevant? High recall and low precision is a common, dangerous combination, the answer is in there, buried, alongside three confident distractors.
Retrieval conflict is the failure the introduction's insurer hit and the litigation team hit: two retrieved sources disagree, often because one is current and one is superseded. The model is now in the conflicting-context situation from Chapter 4, resolving the conflict by an opaque mixture of recency, length, position, and confidence of phrasing, not by a principled rule. The fix is not to hope the model picks right; it is to detect the conflict (a cross-passage contradiction check) and resolve it before generation with an explicit currency/authority rule, then either answer from the authoritative source or surface the conflict to the user.
Retrieval staleness is conflict's quieter cousin: only the old version is retrieved, so there is no conflict to detect, just a faithfully-supported wrong answer. The only defense is data-layer currency, every document carries a validity window, and retrieval filters to current versions or at least flags stale ones. This is the A (Authority/current) in CLAIM, enforced at retrieval time rather than hoped for at generation time.
Measuring the pre-generation surface
Before any generation-side fix, you measure whether retrieval could succeed. RAGAS formalizes the two metrics that matter here and they belong in your eval suite permanently.
def context_recall(gold_spans: list[str], retrieved: list[str], entailer) -> float:
"""Fraction of needed spans that are entailed by the retrieved context.
If this is low, the model cannot answer faithfully -- the evidence isn't there."""
if not gold_spans:
return 1.0
found = sum(1 for g in gold_spans
if any(entailer.classify(r, g) == "entails" for r in retrieved))
return found / len(gold_spans)
def context_precision(retrieved: list[str], question: str, judge) -> float:
"""Fraction of retrieved passages that are actually relevant to the question.
Low precision = distractors and dilution, even if recall is high."""
if not retrieved:
return 0.0
relevant = sum(1 for r in retrieved if judge.is_relevant(r, question))
return relevant / len(retrieved)The diagnostic value is in separating these two from the answer-level metric. A team that only measures "was the final answer right?" cannot tell a retrieval miss from a generation failure, and so cannot choose between "improve the embeddings" and "improve the prompt." Measuring recall and precision upstream of generation tells you which half of the pipeline to fix. If recall is high and the answer is still wrong, the problem is generation-side; if recall is low, no generation fix will help.
The generation-side failures
When retrieval succeeds and the answer is still wrong, you are in the bottom three rows.
Ignored evidence is the model answering from parametric memory despite having the right passage in front of it, common when the retrieved fact contradicts the model's training-time prior, or when the passage sits in the Lost in the Middle trough. The fix is partly assembly (put it at a strong position) and partly prompting (explicit source-aware instructions and forced per-claim citation, which make ignoring the evidence harder).
Over-read is unsupported synthesis against a real passage: the passage supports part of the claim and the model extends it. This is the litigation failure when the cited case is relevant but the holding is inflated. Only an entailment-based claim-coverage check (Chapter 10) catches it; similarity does not.
Citation laundering is over-read with a citation attached, and it is the most dangerous because the citation is real and survives a "does this source exist?" check. It gets its own chapter next. The fix is the inversion from Chapter 1: bind the citation to the verified span, do not let the model emit a citation it did not derive from evidence.
Self-RAG is worth naming here as a research direction that fights the generation-side failures structurally: the model is trained to emit reflection tokens that decide when to retrieve, whether a passage is relevant, and whether its own output is supported, folding the faithfulness check into generation rather than bolting it on after. It is a useful pattern to know even if you implement the checks externally: the goal is a system that knows when its claim is unsupported, by whatever means.
The honest limits of retrieval
Retrieval is necessary for grounded systems and it is not sufficient, and saying so plainly is the chapter's job. Three limits to keep in front of the team:
First, retrieval can only ground claims that have a source. Claims that require synthesis across sources, judgment, or inference are not grounded by retrieval alone; they need the Inference check, because the spans support the inputs to the reasoning, not the conclusion. A perfectly retrieved set of premises does not make the model's deduction valid.
Second, retrieval inherits the quality of the corpus. Faithfulness to a wrong, biased, or stale corpus produces faithful falsehoods. The Authority check is the only thing standing between "the model used the source" and "the source was right to use, " and it depends on metadata (dates, versions, authority tiers) that the corpus must carry. No retrieval algorithm supplies what the documents lack.
Third, retrieval adds failure modes you must now monitor. You have traded one opaque box for a pipeline of six measurable stages: which is a good trade, because measurable is better than opaque, but only if you actually measure. A RAG system without context-recall and context-precision telemetry has more places to fail and no more visibility than the model it replaced.
Chapter summary
"Add RAG" is over-prescribed because it treats hallucination as missing knowledge when it is usually missing grounding, and adding retrieval does not remove the failure surface, it moves it from one opaque box (the model) to six measurable stages (rewrite, retrieve, rerank, assemble, generate, cite). The RAG failure matrix names eleven distinct failures across those stages; only the bottom three (ignored evidence, over-read, citation laundering) are the model hallucinating directly, and the top eight are retrieval and assembly failures invisible to any prompt or model change. The pre-generation failures, miss (fix with hybrid dense+lexical retrieval), noise (fix with precision and reranking), conflict and staleness (fix with currency/authority rules applied at the data layer), must be measured upstream of the answer with RAGAS-style context recall and precision, because that is the only way to tell a retrieval problem from a generation problem and so choose the right fix. The generation-side failures need entailment-based claim-coverage checks, not similarity, and Self-RAG points at folding those checks into generation. Retrieval's honest limits: it grounds only claims that have a source, inherits the corpus's errors (Authority is the only guard), and adds failure modes you must now monitor. This chapter builds on the calibration and self-knowledge foundation from What Models Know About What They Know. The next chapter takes the most insidious row of the matrix, citation laundering, and shows why a citation is not proof.