Operating Against Hallucination in Production
> **Working claim: ** Offline evaluation tells you what the system did on your golden set. Production tells you what it does on the world's questions, against a corpus that drifts, for users who behave nothing like your test cases.

AI hallucination monitoring in production starts at the claim grain, because request-level dashboards hide unsupported facts until users find them.
Key Takeaways
- Offline evals tell you what happened on the golden set; production shows corpus drift, new user behavior, and unseen slices.
- Instrument every factual claim with source, span, confidence, verdict, and mitigation metadata.
- Monitor unsupported-claim rate, abstention rate, citation precision, and user correction by slice.
- Treat each production hallucination as a detection failure, then turn it into a regression item.
Read this with measuring unsupported claims, domain playbooks, and offline vs online evaluation.
**Working claim: ** Offline evaluation tells you what the system did on your golden set. Production tells you what it does on the world's questions, against a corpus that drifts, for users who behave nothing like your test cases. Operating against hallucination is a control loop: instrument every claim, monitor the unsupported-claim rate, detect corpus drift, route user corrections back into evals, and have a runbook ready for the day the system asserts something untrue to someone who acts on it.
The gap offline evaluation cannot close
A system can pass its golden set and hallucinate in production for reasons the golden set structurally cannot see. Real queries are messier, more ambiguous, more adversarial, and more out-of-distribution than test cases. The corpus the system retrieves from changes underneath it, documents are added, superseded, deleted, so an answer that was faithful last week is stale this week with no code change at all. And users do things test harnesses never do: they ask follow-ups that depend on a misremembered earlier turn, paste in their own (wrong) context, and trust the answer in ways that turn a small unsupported claim into a large realized harm.
This is why production needs its own apparatus, organized as a control loop the NIST AI RMF would recognize: measure (instrument every answer), monitor (watch the rates and their drift), respond (route corrections, run the runbook), and improve (feed it all back into evals and the system). The offline program (Chapter 14) is the calibration anchor; the production loop is where the system actually lives.
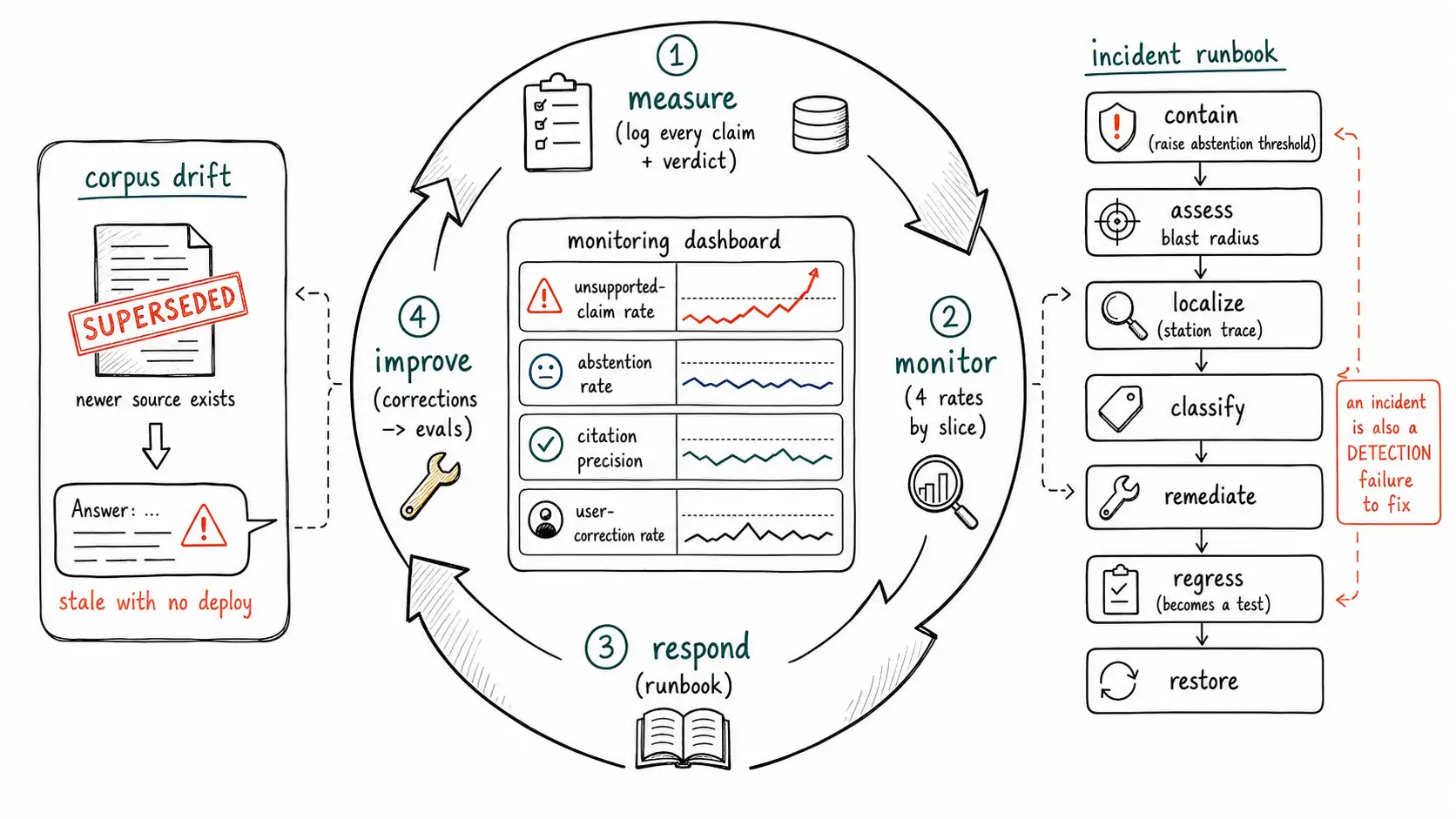
Instrument every claim, not every request
The foundational decision is what to log. Logging requests and responses is the default and it is insufficient, because the unit of hallucination is the claim, and you cannot compute an unsupported-claim rate from response blobs. You log at the claim grain: every answer is decomposed, every claim carries its verdict, its supporting span, and its source, the output of the Chapter 10 pipeline, persisted.
CREATE TABLE answer_events (
event_id TEXT PRIMARY KEY,
ts TIMESTAMP NOT NULL,
user_segment TEXT,
query TEXT NOT NULL,
query_type TEXT, -- classified online
action TEXT NOT NULL, -- 'answer','revise','ask','abstain','escalate'
corpus_version TEXT NOT NULL, -- for drift attribution
latency_ms INTEGER,
model_version TEXT NOT NULL
);
CREATE TABLE claim_events (
event_id TEXT REFERENCES answer_events(event_id),
claim_text TEXT NOT NULL,
claim_type TEXT NOT NULL,
verdict TEXT NOT NULL, -- verifier verdict (signal, not ground truth)
verifier_conf REAL, -- calibrated confidence in the verdict
supporting_span TEXT,
source_id TEXT,
cited BOOLEAN NOT NULL
);
CREATE TABLE user_corrections (
event_id TEXT REFERENCES answer_events(event_id),
claim_text TEXT, -- which claim, if identified
correction_type TEXT, -- 'factually_wrong','unsupported','stale','other'
user_note TEXT,
ts TIMESTAMP NOT NULL
);The corpus_version on every answer is the lever for the drift problem; the verifier_conf keeps the verifier's output honest as a signal (Chapter 10); and user_corrections is the channel that turns the most reliable detector you have, the user who noticed, into data.
The monitoring dashboard
Four rates, watched over time, sliced by segment and query type, catch most production hallucination trends before they become incidents.
-- Daily unsupported-claim rate and abstention rate, by query type
SELECT date_trunc('day', a.ts) AS day, a.query_type,
ROUND(AVG(CASE WHEN c.verdict <> 'supported' THEN 1.0 ELSE 0 END), 3)
AS unsupported_claim_rate,
ROUND(AVG(CASE WHEN a.action = 'abstain' THEN 1.0 ELSE 0 END), 3)
AS abstention_rate,
ROUND(AVG(CASE WHEN c.cited AND c.verdict = 'supported' THEN 1.0
WHEN c.cited THEN 0 END), 3)
AS citation_precision,
COUNT(DISTINCT a.event_id) AS answers
FROM answer_events a
JOIN claim_events c ON c.event_id = a.event_id
WHERE a.ts >= now() - interval '30 days'
GROUP BY day, a.query_type
ORDER BY day DESC, unsupported_claim_rate DESC;- Unsupported-claim rate is the headline. A rise on a slice is the early-warning siren. The RAGAS framework provides the formalized faithfulness metric this rate draws from.
- Abstention rate is watched in both directions: a sudden drop can mean the abstention gate broke (it is answering things it should refuse); a sudden rise can mean retrieval degraded (it is refusing things it could answer) or the corpus lost coverage.
- Citation precision falling signals laundering creeping in, often after a model or prompt change that loosened the binding.
- User-correction rate is the ground-truth-ish signal; a rise here, especially on claims the verifier marked
supported, means the verifier is missing a failure class and the golden set needs new items.
The pattern to internalize: these rates are leading indicators read by slice. The overall number can be flat while a single high-stakes slice degrades, exactly as in offline eval. Alert on slice movement, not just aggregate.
Corpus drift: the failure with no code change
The most insidious production hallucination has no deploy attached to it. The corpus changed, a policy was superseded, a price updated, a document deleted, and answers that bind to the now-stale or now-missing source go wrong while every metric about the model stays flat. This is why corpus_version is on every answer event, and why a drift monitor is a distinct thing from a model monitor.
-- Stale-source exposure: answers still citing sources that have since been superseded
SELECT a.corpus_version, COUNT(DISTINCT a.event_id) AS answers_at_risk
FROM answer_events a
JOIN claim_events c ON c.event_id = a.event_id
JOIN source_catalog s ON s.source_id = c.source_id
WHERE s.superseded_at IS NOT NULL
AND a.ts < s.superseded_at + interval '1 day' -- answered around the supersession
GROUP BY a.corpus_version;Two operational requirements follow. First, sources must carry validity metadata (superseded_at, valid_until), the Authority data from CLAIM, without which currency cannot be checked at all. Second, supersession should invalidate caches and re-run affected evals: when a document is superseded, the golden-set items whose gold spans pointed at it are now testing against stale ground truth, and a drift-aware eval program re-labels them. Drift is the clearest case of why offline evaluation alone is insufficient, the golden set was correct when written and silently wrong now.
The feedback loop
User corrections are the highest-value signal in the system because they catch the failures every automated detector missed, the confident, consistent, fluent falsehoods from Chapter 11's floor. The loop must be deliberate, not incidental:
- Capture the correction at the claim grain (the
user_correctionstable), with enough context to reproduce. - Triage by the taxonomy: is it
unsupported,stale,factually_wrong(corpus error),over-refusal? The triage routes the fix to a chapter. - Reproduce offline, then add it as an
answerable/unanswerablegolden-set item with gold spans, every correction becomes a regression test (OpenAI evals loop). - Attribute to a station (query / retrieval / synthesis / attribution / verification / corpus) using Chapter 1's localization, so the fix is targeted.
- Close by shipping the fix and confirming the new eval item passes, and, if the verifier had marked the claim
supported, by improving the verifier or its calibration set, because it has a blind spot.
Step 5's last clause is the one teams skip and the one that compounds: a user correction on a verifier-supported claim is not just a bad answer, it is evidence your detector is wrong, and treating it only as a content fix leaves the detector blind for the next instance.
The incident runbook
The day will come when the system asserts something untrue to a user who acts on it. A pre-written runbook turns panic into procedure. OWASP's framing of Improper Output Handling and Excessive Agency is the reminder that the blast radius depends on what the user (or downstream agent) did with the claim. The Huang et al. survey catalogs the hallucination types that appear most frequently in deployed systems, the same taxonomy that drives step 4's classification below.
**Runbook: production hallucination incident. **
**1. Contain. ** If the failure is reproducible and high-stakes, raise the abstention threshold for the affected slice (Chapter 13): degrade to caution immediately, before root cause. For agents, suspend the affected tool/action. **2. Assess blast radius. ** Query
answer_eventsfor all answers in the affected slice / corpus_version / model_version since the suspected onset. How many users saw it? Did any act on it (theaction/downstream-effect log)? **3. Localize. ** Run the Chapter 1 trace on the failing answer: query → retrieval → synthesis → attribution → verification → corpus. Which station failed? Was it drift (no deploy) or a change (deploy)? **4. Classify. ** Place it in the taxonomy (Chapter 2). The row names the fix. 5. Remediate at the station: fix the corpus (supersede/correct the source), the retrieval (hybrid/rerank/currency filter), the binding (citation verification), the verifier (new calibration data), or the threshold (abstention). **6. Regress. ** Add the incident as a golden-set item with gold spans. Confirm it now abstains or answers correctly. 7. Restore the abstention threshold once the fix is verified, and write the postmortem with the station, the class, and the detection gap (why did monitoring not catch it sooner?). **8. Improve detection. ** If a user found it before monitoring did, the monitor or the verifier has a gap, file that as its own action.
The runbook's quiet thesis: an incident is not just a wrong answer to fix, it is a detection failure to fix. The first wrong answer is forgivable; the second instance of the same class reaching a user is a process failure.
What "good operations" looks like
A mature anti-hallucination operation is recognizable by a few properties, and they are the practical close of the engineering argument. It logs at the claim grain, so the unsupported-claim rate is a real, sliceable number rather than a vibe. It watches that rate and its siblings by slice, with corpus drift as a first-class, separately-monitored failure that needs no deploy. It treats every user correction as both a content fix and a detector improvement, growing the golden set toward the real failure distribution. It has a runbook that contains first and localizes second, and that treats a missed incident as a detection gap. And it knows its residual, the rate of confident, undetected hallucination that the whole stack does not catch, and bounds the product's claims and the user's trust to match. That last property is the honest one: you are not eliminating hallucination, you are measuring it, bounding it, catching most of it before the user, and being truthful about the rest.
Chapter summary
Offline evaluation is the calibration anchor; production is where the system lives, and it hallucinates for reasons the golden set cannot see, out-of-distribution queries, a drifting corpus, and users who turn small unsupported claims into large realized harm. The production loop is the NIST-RMF control cycle: measure, monitor, respond, improve. Measure means logging at the claim grain, every claim with its verdict, span, source, and the verifier's calibrated confidence, plus a user-corrections channel, because the unsupported-claim rate cannot be computed from response blobs. Monitor watches four rates by slice: unsupported-claim rate (the siren), abstention rate (in both directions), citation precision (laundering creep), and user-correction rate (especially on verifier-supported claims, which reveal detector blind spots), alerting on slice movement, not aggregate. Corpus drift is the insidious failure with no deploy: sources need validity metadata, supersession must invalidate caches and re-run affected evals, and corpus_version on every answer is what attributes it. The feedback loop turns each correction into a triaged, reproduced, attributed, regressed test, and, when the verifier had marked the claim supported, into a detector improvement. The incident runbook contains first (raise the abstention threshold), then assesses blast radius, localizes by station, classifies by taxonomy, remediates, regresses, and restores, treating every incident as also a detection failure to fix. Good operations logs per claim, monitors by slice with drift first-class, treats corrections as detector data, runs a contain-first runbook, and knows and bounds its residual rate. This chapter's control loop builds directly on Measuring Unsupported Claims, which established the golden-set schema and metric definitions. The final movement applies the whole apparatus to concrete domains in Playbooks by Domain.