Self-Consistency and the Limits of the Judge
> **Working claim: ** When you have no reference to check against, you fall back on two instruments: *consistency* (does the model agree with itself across samples?) and *judgment* (does a model rate the output?).

LLM-as-judge hallucination checks help when references are missing, but they need calibration, bias controls, and a clear fallback to source-based verification.
Key Takeaways
- Self-consistency is useful because unsupported claims often vary across samples; stable wrong beliefs can still pass it.
- Semantic uncertainty is stronger than string disagreement because it clusters meanings rather than wordings.
- An LLM judge is powerful and biased by position, verbosity, style, and its own model priors.
- Use judges as measured instruments with gold checks, not as oracles that replace span verification.
Read this with source-span verification, interventions and limits, and llm as a judge.
**Working claim: ** When you have no reference to check against, you fall back on two instruments: consistency (does the model agree with itself across samples?) and judgment (does a model rate the output?). Both are genuinely useful and both are systematically biased. Consistency detects uncertainty but not confident, consistent error. A judge inherits the generator's blind spots and adds its own. Knowing precisely what each cannot see is the difference between a detector and a placebo.
Why consistency is a signal at all
The mechanism from Chapter 4 explains why sampling the same prompt several times tells you something. If the model knows an answer, the relevant fact was well represented in training, the probability mass is concentrated, then multiple stochastic samples converge: you get the same answer, possibly worded differently. If the model is guessing, the mass is spread across several plausible continuations, the samples diverge: different names, different numbers, different claims. Divergence across samples is a proxy for the model's own uncertainty, and uncertainty correlates with hallucination.
SelfCheckGPT operationalized this as a black-box, zero-resource hallucination detector: generate several samples, then for each sentence in the main answer, measure how supported it is by the other samples. A sentence that recurs across samples is probably grounded in something stable the model knows; a sentence that appears in one sample and contradicts or is absent from the others is probably fabricated. The beauty is that it needs no external knowledge source and no logit access, only the ability to sample, which is why it works on hosted models in open-domain settings where reference-based verification (Chapter 10) is impossible.
def self_consistency_score(prompt, model, n_samples=5, temperature=0.7) -> dict:
"""For each claim in the primary answer, measure support across resampled answers."""
primary = model.complete(prompt, temperature=0.0) # the answer to check
samples = [model.complete(prompt, temperature=temperature, seed=i)
for i in range(n_samples)]
claims = extract_claims(primary)
scores = {}
for claim in claims:
# support = fraction of samples whose content ENTAILS the claim
support = sum(1 for s in samples if entails(s, claim.text)) / n_samples
scores[claim.text] = support # low support => likely hallucinated
return {"claims": scores,
"flagged": [c for c, s in scores.items() if s < 0.5]}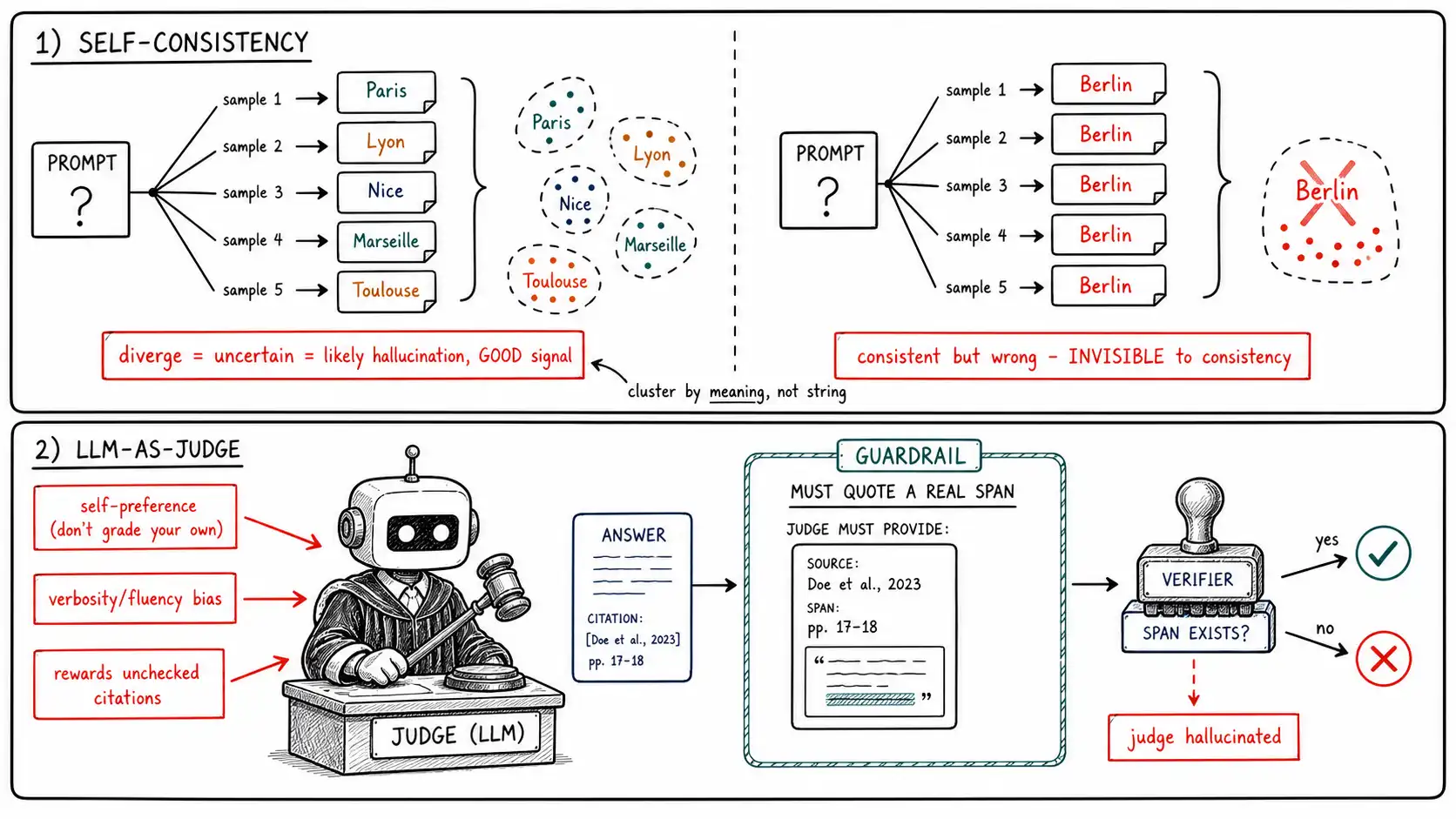
What consistency cannot see
The decisive limitation, and the one that disqualifies consistency as a sole detector: **a confident, consistent error is invisible to it. ** If the model has learned a falsehood (the TruthfulQA case) or has a strong, wrong parametric prior, every sample agrees, on the wrong answer. The samples converge beautifully; the convergence is on a fabrication. Consistency measures self-agreement, and a model can agree with itself about something false as easily as something true. This is not a tuning problem; it is structural. Consistency detects the spread of the model's belief, not its correctness, and a tight spread around a wrong belief reads as high confidence.
The second limitation is subtler and motivates Semantic Uncertainty: naive consistency over strings conflates wording variation with substance variation. The model might answer "Paris, " "It's Paris, " and "The capital is Paris", three different strings, one meaning, perfect substantive agreement that a string-match consistency check would underrate. Semantic uncertainty fixes this by clustering samples into meaning groups (using an entailment model: two answers are the same meaning if they bidirectionally entail) and measuring entropy over meanings. High semantic entropy, samples spread across distinct answers, is the clean uncertainty signal; high lexical entropy with low semantic entropy is just paraphrase, and not a hallucination signal at all. Any production consistency check should operate over meanings, not strings.
The third is cost: consistency multiplies inference by the sample count. Five samples is five times the latency and spend. This pushes consistency toward an offline or sampled role, running it on a slice of traffic for monitoring, or on high-stakes answers, rather than on every request. Self-Consistency for chain-of-thought shows the related use as an accuracy improver (marginalize over reasoning paths, take the majority answer), which is a different goal, improving the answer rather than detecting hallucination, but shares the cost profile and the meaning-clustering need.
The LLM-as-judge: powerful and quietly biased
The second reference-free instrument is asking a model to judge an output: "is this answer faithful to the context?" "does this claim contain a hallucination?" It is attractive because it is flexible (you can ask any question in natural language), cheap relative to human review, and scalable. Zheng et al. studied it rigorously and found that a strong judge model agrees with human preferences at rates comparable to human-human agreement on many tasks, which is the empirical license for using judges at all. But the same study, and the broader literature, catalog biases that make a naive judge unreliable in ways that correlate with hallucination, which is the worst possible failure for a hallucination detector.
The biases that matter most for our purpose:
- **Self-preference / self-consistency bias. ** A judge tends to rate outputs from its own model family, or outputs that match its own generation, more favorably. If the same model generates and judges, it will rate its own fluent fabrication as faithful, because the fabrication is exactly the kind of text it finds probable. Using the generator as its own judge is the single most common and most dangerous judge setup.
- **Verbosity / fluency bias. ** Judges reward longer, more fluent, more confident answers, which is precisely the surface signature of a polished hallucination. The more fluent the fabrication, the higher a biased judge rates it. The judge's bias and the hallucination's disguise are aligned.
- **Position and formatting bias. ** In pairwise judging, the order of options sways the verdict; in scoring, formatting and the presence of citations (even unverified ones) inflate scores. A judge can be swayed by a citation it never checked, the laundering it is supposed to catch.
def judge_faithfulness(answer, context, judge_model) -> dict:
"""Use an LLM as a faithfulness judge -- with the guardrails that make it usable."""
verdict = judge_model.json(
instruction=(
"For EACH atomic claim in the answer, decide if it is supported by the "
"context. Quote the exact supporting span or write NONE. A claim with no "
"quoted span is UNSUPPORTED regardless of plausibility. Do not reward "
"fluency, length, or the mere presence of a citation."
),
answer=answer, context=context,)
# Guardrail: the judge must produce a SPAN, not just a label -- forcing it to
# do the linking work makes verbosity/fluency bias much harder to exploit.
for claim in verdict["claims"]:
if claim["label"] == "SUPPORTED" and not span_in_context(claim["span"], context):
claim["label"] = "JUDGE_HALLUCINATED_SPAN" # the judge itself fabricated
return verdictMaking the judge usable
The judge biases are not a reason to abandon judges; they are a specification for how to constrain them. The guardrails, in order of impact:
- **Never let the generator judge itself. ** Use a different model, ideally a different family, as the judge. This breaks self-preference bias, the most damaging one.
- **Force the judge to produce evidence, not just a label. ** Require a quoted span for every "supported" verdict, and then verify the span exists in the context programmatically (the
span_in_contextcheck above). A judge that must point at a real span cannot reward fluency alone, it has to do the linking work, and a fabricated span is caught by a string check. This single guardrail neutralizes most verbosity and fluency bias, because the judge can no longer "feel" that a fluent claim is supported; it must locate the support. - **Decompose before judging. ** Judge atomic claims, not whole answers, for the same reason verification does, a paragraph-level judgment averages over a supported/unsupported mix and hides the fabrication.
- **Calibrate the judge. ** A judge is a model producing a signal; measure its agreement with human labels on a golden set, track it, and treat its confidence as a feature requiring calibration (Chapter 5), not as truth.
The deepest caveat, stated plainly: **a model judging hallucination can hallucinate while judging it. ** It can fabricate the supporting span (caught by the span_in_context check), misjudge entailment, or confidently rate a fabrication as faithful. The guardrails reduce these; they do not eliminate them. A judge is a useful, scalable, imperfect detector whose reliability you measure against human labels, not assume.
Choosing the right instrument
The instruments are complementary, and a mature detection stack uses them in layers matched to what each can see. A decision guide:
| Situation | Best instrument | Why |
|---|---|---|
| Provided source (RAG, summary) | Reference-based verification (Ch. 10) | Concrete ground truth; entailment is checkable |
| Open-domain, can retrieve | Retrieve, then reference-based (FEVER pattern) | Convert to the checkable case |
| Open-domain, no source, need cheap signal | Self-consistency / semantic uncertainty | Detects uncertainty without external knowledge |
| Need a scalable faithfulness label | LLM-as-judge with span guardrail + separate judge | Flexible, but constrain and calibrate it |
| High stakes, low volume | Human review (Ch. 14) | The only instrument without a model blind spot |
| Confident, learned falsehood | External fact-check against authority | Consistency and judges both miss it |
The bottom two rows are the honest floor. For a confident, consistent, fluent falsehood, the model's strong wrong prior, rendered beautifully, every automated instrument in this chapter can fail simultaneously: consistency sees agreement, the judge sees fluency and a citation, and there is no provided source to contradict it. The only defenses are an external authoritative source (turning it into the reference-based case) and human review. A system whose failure cost justifies neither has accepted a residual rate of confident, undetectable hallucination, and the responsible thing is to know that number and bound the system's use accordingly, not to pretend the automated stack closed the gap.
Chapter summary
When no reference is available, detection falls back on two instruments, each useful and each systematically biased. Self-consistency (SelfCheckGPT) samples the prompt repeatedly and flags claims the samples do not agree on, divergence is a proxy for the model's uncertainty, but it is blind to confident, consistent errors (learned falsehoods, strong wrong priors), because it measures self-agreement, not correctness; and it must operate over meanings, not strings (semantic uncertainty), or it confuses paraphrase with substantive disagreement, at a cost that pushes it toward sampled/offline use. LLM-as-judge is flexible and scalable and agrees with humans at usable rates, but carries biases that align with hallucination's disguise: self-preference (never let the generator judge itself), verbosity/fluency bias (it rewards polished fabrication), and citation/position bias. The guardrails that make a judge usable: use a different model, force it to quote a real span you then verify programmatically (neutralizing fluency bias because the judge must do the linking), decompose before judging, and calibrate it against human labels (a model mostly knows what it knows), while accepting that a judge can hallucinate while judging. The instruments are complementary and chosen by situation, with one honest floor: for a confident, consistent, fluent falsehood, every automated instrument can fail at once, and only an external authoritative source or human review remains, a residual rate to measure and bound, not to wish away. The next movement turns from claim extraction and source-span verification to reducing hallucination: the full menu of interventions and, unsentimentally, the limits of each.