Teaching a System to Say "I Don't Know"
> **Working claim: ** The most valuable output an AI system can produce is often a calibrated refusal. A system that abstains when its evidence is insufficient converts an undetectable confident falsehood into a visible, safe non-answer.

AI abstention turns an unsupported confident answer into a visible non-answer the product can route, measure, and improve.
Key Takeaways
- The safest answer is often I do not know, especially when the evidence chain cannot be completed.
- Selective prediction makes abstention tunable through risk-coverage curves instead of vague caution.
- The threshold must reflect the cost matrix: wrong answer, abstention, escalation, and delay do not cost the same.
- A good refusal is specific about what is missing and what the system can do next.
Read this with interventions and their limits, measuring unsupported claims, and human loop is not a plan.
**Working claim: ** The most valuable output an AI system can produce is often a calibrated refusal. A system that abstains when its evidence is insufficient converts an undetectable confident falsehood into a visible, safe non-answer. But abstention is a two-sided cost, refuse too readily and the system is useless; refuse too rarely and it is dangerous, so abstention is not a feature you add, it is a *threshold you tune against an explicit cost matrix. *
Why abstention is the highest-use intervention
Recall the floor that every previous chapter has bumped against: a confident, consistent, fluent falsehood can defeat consistency checks, fool a judge, and, if no reference is available, survive verification. The one move that always helps against that floor is for the system to decline to answer when it cannot establish support. Abstention does not require detecting which falsehood is present; it requires only detecting that support is insufficient, which is a weaker and more achievable condition. You do not have to know the answer is wrong. You only have to know you cannot show it is right.
This reframes the system's job. A naive assistant has one output: an answer. An abstention-capable assistant has a portfolio of outputs, answer, partial answer with caveats, clarifying question, "I don't have enough information, " escalate to a human, and chooses among them based on the strength of the evidence chain. The CLAIM framework's M-step was this portfolio all along. This chapter makes it operational, and the central idea is borrowed from a well-studied area: selective prediction.
Selective prediction: the formal frame
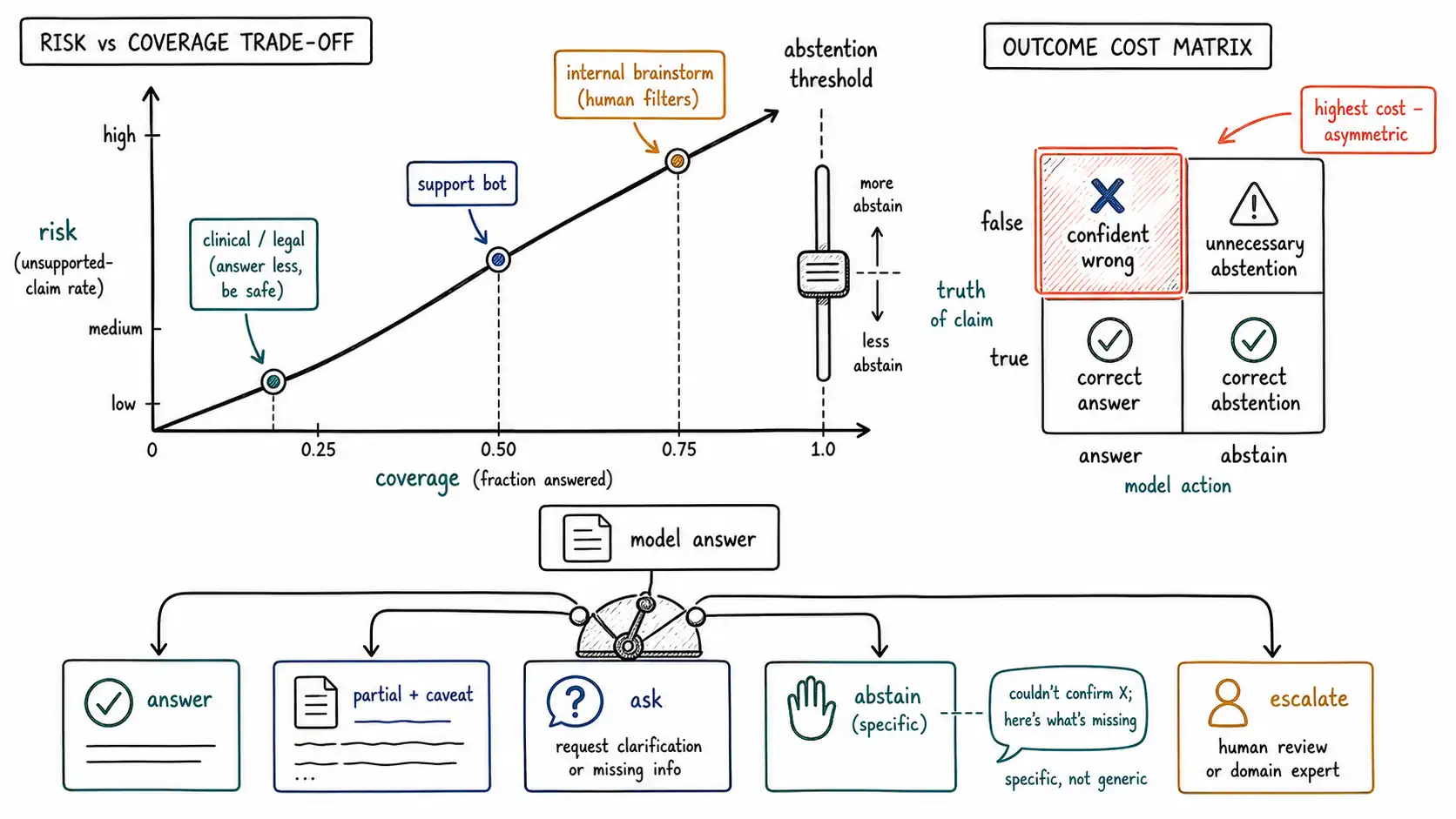
Selective prediction (also called selective classification, or learning with a reject option) is the formalization that abstention needs. The idea: a predictor is paired with a gating function that decides, per input, whether to predict or abstain. You then characterize the system by its risk-coverage curve, as you lower the confidence threshold required to answer, coverage (the fraction of inputs you answer) rises and risk (the error rate on answered inputs) typically rises too. The curve makes the trade explicit and tunable: you pick the operating point where the error rate on answered questions is acceptable, and you accept the coverage that comes with it.
This is exactly the right mental model for hallucination abstention. Replace "error rate" with "unsupported-claim rate" and "confidence" with "the verifier's faithfulness signal, " and you have a knob: answer only when the support signal clears a threshold; abstain otherwise. The threshold sets your operating point on the risk-coverage curve.
def risk_coverage_curve(items, support_signal, is_correct, thresholds):
"""For each abstention threshold, compute (coverage, risk_on_answered).
items: eval items; support_signal[i] in [0,1]; is_correct[i] in {0,1}."""
curve = []
for t in thresholds:
answered = [i for i in items if support_signal[i] >= t]
if not answered:
curve.append((t, 0.0, None)); continue
coverage = len(answered) / len(items)
risk = 1 - sum(is_correct[i] for i in answered) / len(answered)
curve.append((t, coverage, risk))
return curveA typical curve for a RAG assistant might read: at threshold 0.5, coverage 0.95 and risk 0.18; at 0.7, coverage 0.78 and risk 0.07; at 0.85, coverage 0.52 and risk 0.02. Each row is a product decision. A clinical tool picks the 0.85 row, answer half the questions, be wrong on 2% of those, abstain on the rest. An internal brainstorming tool picks the 0.5 row, answer almost everything, tolerate 18% error because the human filters it. Same model, same verifier, different operating point, chosen from the curve and from the cost matrix below.
The cost matrix makes the threshold honest
A threshold chosen by feel is a threshold chosen wrong. The honest way to set it is an explicit cost matrix that prices the two errors abstention trades between, and crucially, prices them differently because they are not symmetric.
| Outcome | What happened | Cost driver |
|---|---|---|
| Correct answer | Answered, was right | Value delivered (negative cost) |
| Confident wrong answer | Answered, was wrong | Highest cost, acted on, hard to catch, erodes trust |
| Correct abstention | Abstained, would have been wrong | Small cost, user mildly inconvenienced, harm avoided |
| Unnecessary abstention | Abstained, would have been right | Cost, usefulness lost, user frustrated, may bypass system |
The asymmetry is the whole point: in most serious applications, a confident wrong answer costs far more than an unnecessary abstention, because the wrong answer is acted upon and the abstention merely sends the user elsewhere. The threshold should be set where the expected cost is minimized given these weights, which, for high-stakes domains, pushes coverage down and abstention up. The mistake teams make is treating coverage as the metric to maximize ("answer everything!"), when the metric to minimize is expected cost, and the cheapest way to lower it is usually to abstain more on the questions where support is weak.
def expected_cost(curve_point, costs, base_correct_rate):
"""Expected cost at one operating point, given the cost weights."""
t, coverage, risk = curve_point
if risk is None:
return costs["unnecessary_abstain"] * 1.0 # answered nothing
answered = coverage
abstained = 1 - coverage
wrong = answered * risk
right = answered * (1 - risk)
# of the abstained, some would have been right (unnecessary), some wrong (correct abstain)
unnec = abstained * base_correct_rate
correct_abstain = abstained * (1 - base_correct_rate)
return (costs["confident_wrong"] * wrong
+ costs["unnecessary_abstain"] * unnec
+ costs["correct_abstain"] * correct_abstain
- costs["correct_answer_value"] * right)You sweep this over the risk-coverage curve and pick the minimum-cost threshold. It turns "how cautious should the assistant be?" from an argument into a calculation, and the calculation's inputs (the cost weights) are exactly the conversation product and risk should be having anyway.
How a system actually abstains
The threshold is the policy; the mechanism is how the abstention signal is produced and how the refusal is phrased. Three layers, in order of reliability.
**Evidence-coverage gating (most reliable). ** For grounded systems, the abstention signal is the faithfulness check from Chapter 10: if the core claims cannot be linked to entailing, current spans, the system has no support and should abstain. This is the strongest abstention basis because it is grounded in the actual evidence chain, not in the model's self-report. RAGAS context-recall feeding the gate is the canonical pattern: low recall means the evidence to answer was never retrieved, so answering is fabrication by construction, abstain or re-retrieve.
**Calibrated-confidence gating (use with measurement). ** Where no reference exists, the abstention signal is the calibrated confidence score from Chapter 5, recalibrated, never the raw model output. Models (Mostly) Know What They Know is the license: there is enough self-knowledge signal to gate on, if you have measured and recalibrated it. The boxed warning from Chapter 5 applies in full here, an uncalibrated confidence gate leaks at the high-confidence end.
**Trained abstention (helpful, limited). ** Fine-tuning or preference-tuning a model to say "I don't know" on questions it cannot support (InstructGPT-style) genuinely raises the floor, the model learns the behavior of declining. The limit is calibration: a model trained to abstain can abstain on the wrong questions (over-refusal on answerable ones, the cost-matrix's "unnecessary abstention") and still answer confidently on unanswerable ones it happens to have a strong prior about. TruthfulQA is the relevant reminder, a learned falsehood feels like knowledge to the model, so trained abstention does not fire on it. Trained abstention is a useful prior, not a substitute for evidence-coverage gating.
def abstention_decision(claims, support_signal, query_ambiguous, stakes, threshold) -> dict:
core = [c for c in claims if c.is_core]
core_supported = all(c.label == "SUPPORTED" for c in core)
if core_supported and support_signal >= threshold:
return {"action": "ANSWER"}
if query_ambiguous:
return {"action": "ASK",
"message": clarifying_question(claims, query_ambiguous)}
if stakes == "high":
return {"action": "ESCALATE", "message": "Routing to a specialist."}
# the calibrated refusal:
return {"action": "ABSTAIN",
"message": refusal_text(claims), # specific, not a generic apology
"missing": [c.text for c in core if c.label!= "SUPPORTED"]}A good refusal is specific
The last detail separates a useful abstention from a frustrating one: *what the refusal says. * A generic "I'm sorry, I can't help with that" is nearly as bad as a wrong answer, because it teaches users the system is useless and trains them to route around it (and around its safety). A good refusal is specific and actionable: it says what it could and could not establish, names the missing evidence, and offers a path."I found the policy on water-damage coverage but could not find a current version confirming the exclusion for government-ordered closures; the document I have may be superseded. I can flag this for a specialist or you can confirm the policy effective date." That refusal preserves trust, advances the task, and is honest about the evidence chain, it is the M-step rendered as language. The difference between specific and generic refusal is, in practice, the difference between users who trust abstention and users who disable it.
The failure mode of abstention itself
Honesty requires naming how abstention goes wrong, because a poorly-built abstention system fails in both directions at once. Over-abstention makes the system useless and, worse, trains users to disable the caution or bypass the tool, so a too-cautious system can increase realized harm by driving users to an ungated path. Under-abstention is the original problem unsolved. And a miscalibrated abstention signal produces the worst case: confident on the questions it should refuse, refusing the questions it could answer, abstaining anti-correlated with support. This is why abstention is inseparable from calibration (Chapter 5) and verification (Chapter 10): the abstention decision is only as good as the support signal it gates on. Abstention is not a safety blanket you throw over a system; it is the visible output of a measured evidence chain, and a system that abstains on a bad signal has simply moved its hallucination from the answer to the refusal.
Chapter summary
A calibrated refusal is often an AI system's highest-value output, because abstention defeats the floor every other chapter hits, a confident, consistent, fluent falsehood, without requiring you to detect which falsehood is present; you need only detect that support is insufficient, a weaker and more achievable condition. Selective prediction is the formal frame: pair the predictor with a gating function and characterize the system by its risk-coverage curve, then choose an operating point. The threshold must be set against an explicit, asymmetric cost matrix, a confident wrong answer costs far more than an unnecessary abstention in serious applications, so the metric to minimize is expected cost, not coverage, which usually pushes high-stakes systems toward abstaining more. The abstention signal comes, in order of reliability, from evidence-coverage gating (the faithfulness check; the strongest basis), calibrated-confidence gating (measured, never raw), and trained abstention (a useful prior that misfires on learned falsehoods and can over-refuse). A good refusal is specific and actionable, naming what was and was not established and offering a path, because a generic refusal trains users to disable the caution. And abstention has its own failure mode: over-abstention drives users to ungated paths and can increase realized harm, under-abstention leaves the problem unsolved, and a miscalibrated signal abstains anti-correlated with support, so abstention is inseparable from interventions and their limits and verification. The next movement turns the whole apparatus into something you run continuously: measuring unsupported claims, production measurement, and monitoring.