Introduction: The Holding That Never Was
The system did almost everything right, which is what made the failure so hard to see.

Research spine: this chapter stays grounded in FActScore and ALCE, then applies that evidence to the operating judgment in the book. AI hallucination diagnosis starts by tracing the claim chain, not by declaring that the model made something up.
Key Takeaways
- The legal-research failure is dangerous because most visible pieces looked right: query, retrieved cases, citation form, and confident prose.
- Calling the failure hallucination too early hides the stations that actually failed.
- The book argues for claim-level evidence binding, abstention, and production instrumentation rather than prompt-only fixes.
- The first repair is diagnostic discipline: localize the broken link before changing the model.
Read this with the book front matter, the confident wrong answer, and why RAG pipelines fail in month three.
The system did almost everything right, which is what made the failure so hard to see.
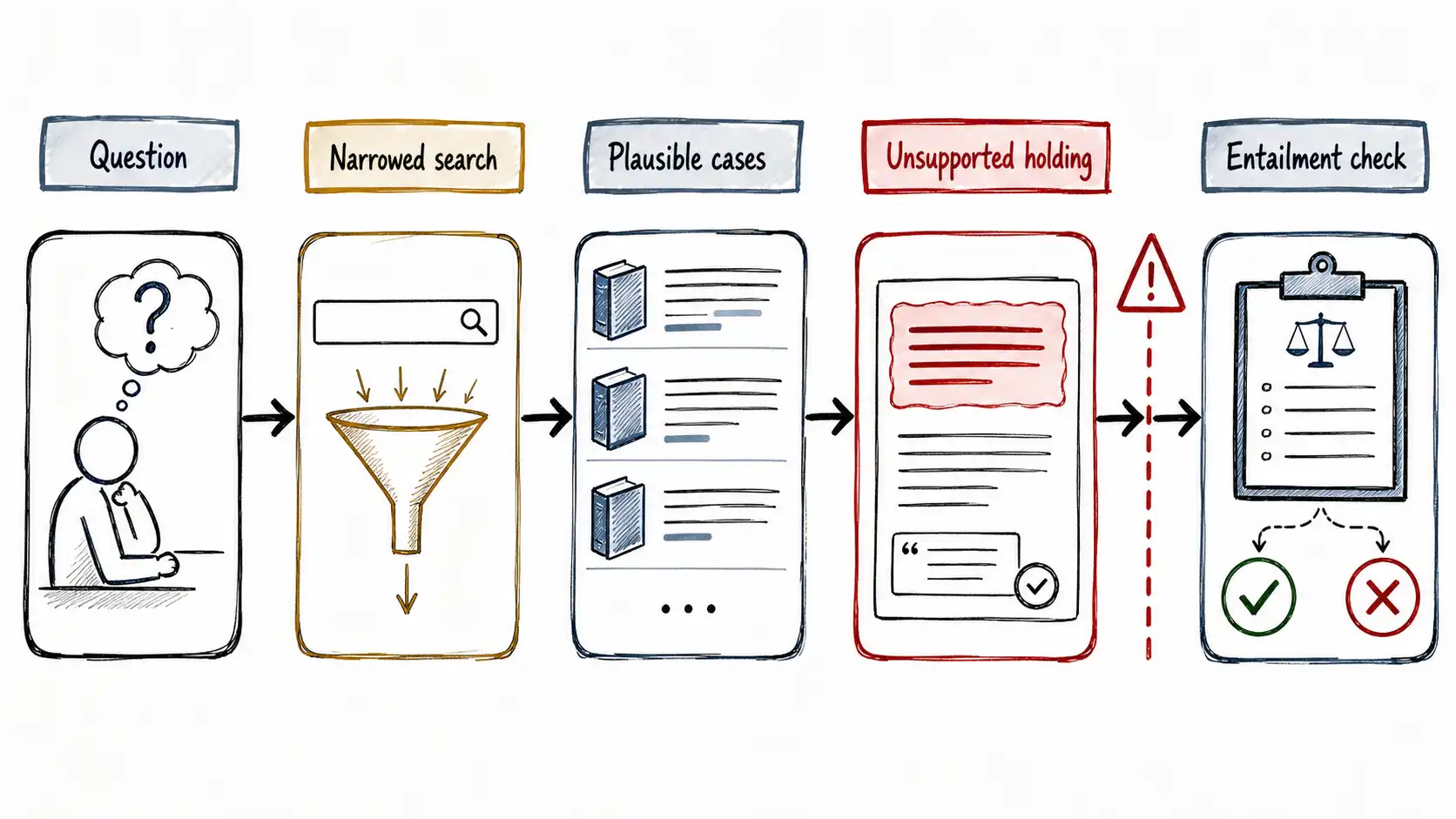
A litigation-support team, the details composited from several real deployments, the shape exact, had built a research assistant for a regional law firm. An associate would type a question in plain language: "Has any court in this circuit held that a force-majeure clause covers a government-ordered shutdown?" The assistant rewrote the question into a search query, retrieved a set of opinions and secondary sources from a licensed legal database, and drafted an answer with citations in the firm's house style. The associates loved it. It turned an afternoon in the books into ninety seconds, and the citations looked exactly like the ones a careful junior would produce: case name, reporter, court, year, a parenthetical describing the holding.
In the pilot's third week, a partner reviewing a draft brief pulled one of the cited cases. The case was real. The court was real. The year was right. The parenthetical, the one-sentence summary of what the court held, described a holding the case did not contain. The opinion existed; the holding attributed to it did not. The associate had been about to file a brief that told a judge a real court had decided something it never decided.
When the team did the post-mortem, the instinct in the room was the instinct in every room: *the model hallucinated. * But that phrase, said out loud, immediately stopped being useful, because it did not tell anyone what to change. So they did something better. They traced the sentence backward, claim by claim, and found not one failure but a chain of them.
The query rewrite had quietly narrowed the question, dropping the word government-ordered and searching for force-majeure cases generally. Retrieval had returned related, plausible material, force-majeure opinions, but not the specific line of cases the associate actually needed, because that line used different vocabulary. The model, handed a stack of genuinely relevant-looking cases that did not quite answer the question, did what language models do: it produced a fluent, coherent continuation. It synthesized a holding that would have answered the question, attached it to the most prominent retrieved case, and formatted the citation perfectly, because formatting a citation is a text-shaping task and the model is superb at text-shaping. Nothing in the pipeline ever checked whether the parenthetical was *entailed by the text of the cited opinion. * There was no evaluation for legal entailment at all. The citation looked like proof. It was decoration.
That is the anatomy this book is about. Not "the model lies, " but: which claim lacked support, and at which station did the system fail to notice?
Why "it hallucinated" is a diagnosis that prevents diagnosis
There is a particular danger in a word that feels explanatory but explains nothing."Hallucination" is such a word. It names the symptom, a confident, unsupported claim, and by naming it, it tempts you to treat the symptom as the disease. Teams that say "the model hallucinated" reach, almost reflexively, for one of a handful of cures: lower the temperature, add retrieval, instruct the model to cite its sources, append a disclaimer, upgrade to a larger model, or add the words be truthful and do not make things up to the system prompt.
Each of those moves can help in the right situation. The trouble is that they are remedies for different diseases, and applied to the wrong one they do nothing, or worse, they hide the problem under a thicker layer of fluent prose. Lowering the temperature reduces the variety of wrong answers; it does not manufacture evidence. Adding retrieval helps when the failure was missing knowledge; it does nothing when the right document was retrieved and then ignored, and it makes things worse when retrieval injects a confidently wrong distractor. Asking for citations produces citations; whether those citations support the claims is a separate question that "ask for citations" never answers, as the litigation team learned. A bigger model is more fluent, and more fluent wrong answers are harder to catch, not easier.
The reflex fails for a simple reason: it skips the diagnostic step. In every other engineering discipline, you localize a fault before you fix it. You do not replace random components on a misbehaving server and hope. You read the logs, reproduce the failure, find the line. Hallucination has resisted this discipline mostly because the vocabulary collapsed: a dozen distinct faults all surface as the same fluent, plausible, wrong sentence, and the field reached for one word to cover all of them.
What this book argues
The argument runs in nine movements, and they build.
Naming the failure comes first, because you cannot reduce what you cannot distinguish. We build a taxonomy, fabricated entities, fabricated citations, wrong attribution, unsupported synthesis, stale facts, contradicted answers, invented tool results, misplaced certainty, and the distinction the research literature draws between intrinsic hallucination (contradicting the provided source) and extrinsic hallucination (adding content the source neither supports nor contradicts). Then we introduce CLAIM, the framework the rest of the book runs on: decompose the output into atomic Claims; find the Link (source span, tool result, or state record) for each; check that the source has Authority (allowed, current, authoritative); ask whether the model's Inference stayed inside the evidence; and choose a Mitigation, answer, revise, ask, abstain, or escalate.
Why models produce unsupported claims comes second. We explain the mechanism honestly, without overstating what is known: next-token prediction rewards plausible continuation, not verified fact; the training objective imitates the distribution of human text, including its confident wrongness; parametric memory is lossy and undated; and decoding choices change the variance of outputs but cannot conjure evidence the model never had. We treat calibration seriously, the finding that large models, especially on multiple-choice formats, carry usable signal about their own correctness, alongside the equally important finding that this signal is fragile and degrades under fine-tuning, formatting, and open-ended generation.
Retrieval failure is not generation failure is the movement many teams need most, because "add RAG" is the most over-prescribed cure in the field. We separate the failures that happen before the model generates a single token, retrieval miss, retrieval noise, retrieval conflict, retrieval staleness, chunking and reranking failures, position effects, from the failures that happen during generation: retrieved-but-ignored evidence, answers unsupported by the context, and citation laundering, where the system cites a source that does not actually support the claim.
Summaries and transformations is the movement people forget. Hallucination is not only question answering. A summary can contradict its source (intrinsic) or add facts the source never contained (extrinsic); it can swap entities, corrupt numbers and dates, drop the qualifier that changes the meaning, over-compress until a hedge becomes an assertion, or invent an action item in a meeting that nobody agreed to.
Tools, agents, and hallucinated actions raises the stakes. An agent can claim it sent the email it never sent, interpret a tool's error as success, act on stale state, or invent a capability it does not have. Here the unsupported claim is not just wrong, it can be wrong *about the state of the world the system is supposed to be changing. *
Detection and verification turns to instruments: claim extraction, source-span verification, entailment checks, self-consistency sampling, and the genuine but limited usefulness of an LLM acting as a judge. We are honest about what each instrument can and cannot see.
Mitigation patterns is deliberately unsentimental. Every intervention, better prompts, abstention instructions, RAG, hybrid search and reranking, structured outputs, tool use, fine-tuning, verification loops, human review, product design, is mapped to the specific failure mode it addresses and the ones it does not. The most important mitigation gets its own chapter: teaching a system to abstain, because a calibrated "I don't know" is often the highest-value output an AI system can produce.
Evaluation and monitoring in production closes the engineering argument. We build claim-level metrics, faithfulness and citation-precision measures, golden sets and real-query sampling, an annotation guide for labeling unsupported claims, a monitoring schema, the SQL to report on it, and the runbook for the incident you will eventually have: *the system asserted something untrue to a user. *
Use-case playbooks ends the book on the ground, walking through internal knowledge assistants, legal and healthcare and finance research tools, support bots, meeting summarizers, code assistants, and workflow agents, each with its likely hallucination types, evidence requirements, and escalation rules.
How to read this book
It is written to be read in order, because the movements build, but each chapter is also a usable unit. An engineer in the middle of a specific fire can open to the relevant chapter and find an artifact: a taxonomy, a verifier, an eval fixture, a structured answer schema, a monitoring query, a runbook. The code is deliberately verification and evaluation infrastructure, claim extractors, source-span mappers, entailment gates, self-consistency samplers, citation validators, tool-result schemas, abstention policies, hallucination dashboards, and not generic chatbot plumbing. Every code example exists to measure or reduce an unsupported claim. That is the whole point.
The tone is diagnostic and unsentimental, but not despairing. Hallucination cannot be eliminated; a system that can produce novel sentences can produce novel false ones. But it can be measured, bounded, attributed, and, crucially, caught before it reaches the user far more often than most deployed systems catch it today. The pessimism in this book is aimed at the easy cures, not at the problem. The problem is tractable. It is just not a single problem.
The litigation team's assistant gave a perfect answer in the demo and a dangerous one in week three. Between those two moments sat a chain of small, nameable failures, none of which was "the model hallucinated." The rest of this book is about learning to see the chain.
This introduction follows Front Matter: Hallucination, Mechanically, which sets up the book's framework and shared spine. Turn the page. The first full chapter, The Confident Wrong Answer, opens with the same question this litigation failure raised: why does the sentence sound right even when nothing supports it?