The CLAIM Framework
> **Working claim: ** A taxonomy tells you what went wrong after the fact. A framework tells you what to check before you answer.

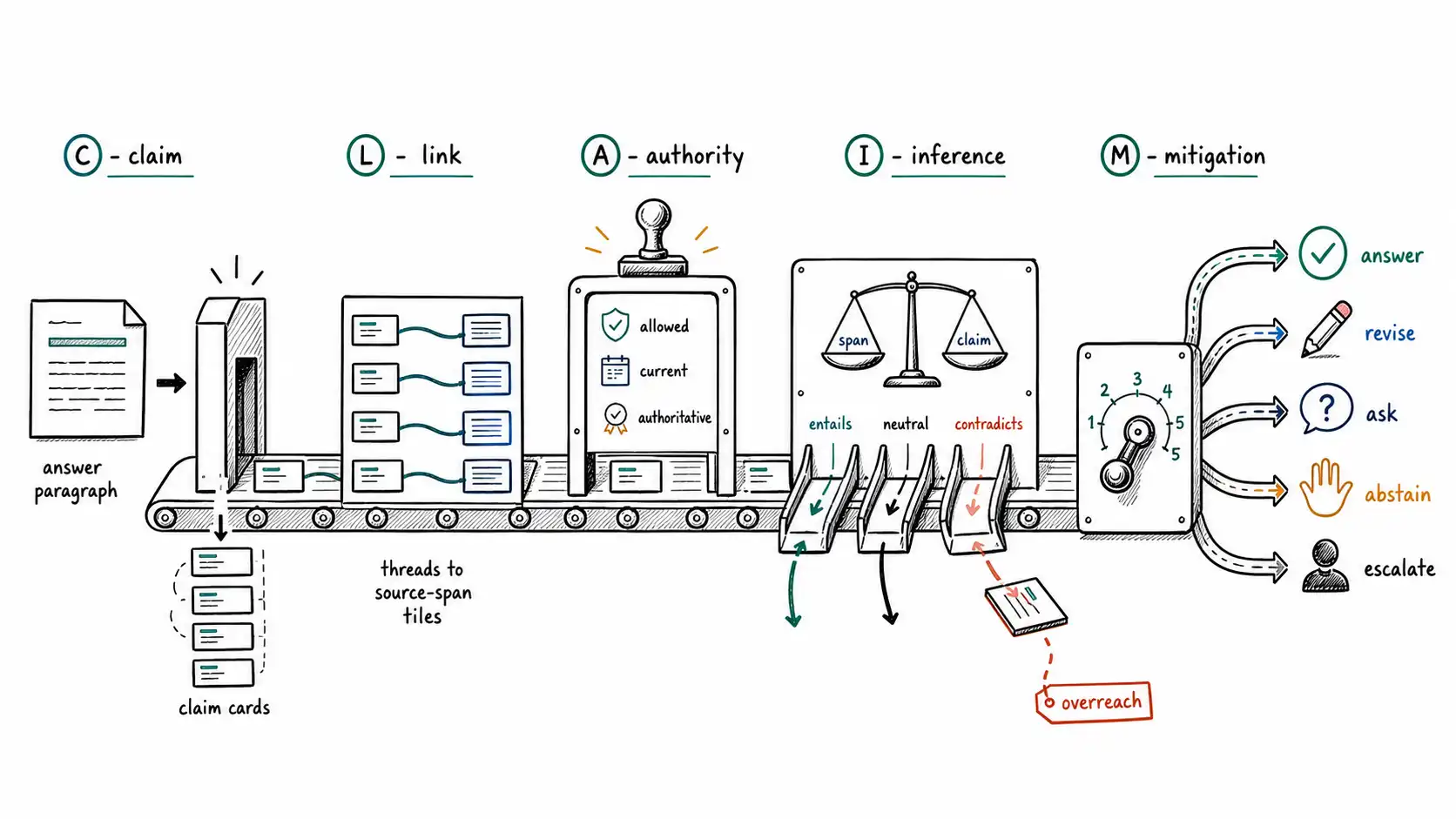
The CLAIM Framework is the control flow for reducing AI hallucination before an answer reaches a user.
Key Takeaways
- CLAIM asks five questions in order: claim, link, authority, inference, mitigation.
- The unit is the atomic claim, not the answer, because unsupported facts hide inside otherwise useful paragraphs.
- Authority is separate from entailment: a stale or forbidden source can support a claim and still be the wrong source.
- Mitigation makes answer only one option among revise, ask, abstain, and escalate.
Read this with the working taxonomy, fluency is not evidence, and evals that predict production.
**Working claim: ** A taxonomy tells you what went wrong after the fact. A framework tells you what to check before you answer. CLAIM is the control flow of an anti-hallucination system: for every claim, find its link, test its authority, judge whether inference exceeded evidence, and choose a mitigation. The output of CLAIM is not always "answer." Often the correct output is "ask, " "abstain, " or "escalate."
The five questions, as a pipeline
The taxonomy from Chapter 2 is a way to label a failure that already happened (for a comprehensive map of those failure types, see the Survey on Hallucination in Large Language Models (Huang et al.)). CLAIM is the way to prevent it, a set of five questions a mature system asks about every factual statement, in order, before that statement reaches a user. The letters are a mnemonic; the value is that each question routes to a concrete component and a concrete decision.
- **C: Claim. ** What exactly is being asserted? Decompose the output into atomic claims. You cannot verify a paragraph; you verify claims.
- **L: Link. ** For each claim, what specific span, tool result, or state record supports it? Not the document, the span.
- **A: Authority. ** Is that source allowed for this user, current as of now, and authoritative for this kind of question?
- **I: Inference. ** Did the model stay inside the evidence, or infer beyond it? A claim can have a real link and still over-reach what the link supports.
- **M: Mitigation. ** Given the above, what should the system do: answer, revise, ask, abstain, or escalate?
The order is not decorative. Each question depends on the answer to the previous one. You cannot ask about the link until you have an atomic claim. You cannot ask about authority until you have a link to a source. You cannot ask about inference until you have a link whose strength you can judge. And the mitigation decision is a function of all four. CLAIM is a pipeline, and the rest of this section walks it as one.
C: Claim: decompose before you defend
Decomposition was introduced in Chapter 2; here it becomes the entry point of the pipeline. The reason it comes first is that every downstream check operates per-claim, and a system that tries to verify whole answers will systematically pass partly-fabricated ones. FActScore demonstrated the cost of skipping this: paragraph-level judgments hide the fraction of atomic facts that are unsupported.
def extract_claims(answer: str, extractor) -> list[AtomicClaim]:
"""Turn a fluent answer into atomic, independently checkable claims.
Implemented with an LLM under a strict instruction: split into minimal
factual statements, preserve qualifiers as separate QUALIFIER claims,
and never merge two facts into one claim."""
raw = extractor.decompose(answer) # returns list[{text, type}]
return [AtomicClaim(text=c["text"], claim_type=ClaimType(c["type"])) for c in raw]A subtlety that matters in practice: *qualifiers must survive decomposition as their own claims. * "Effective in adults" and "effective" are different claims; collapsing the scope is exactly how compression-driven hallucination (Chapter 8) sneaks through a verifier that only checks the headline fact. A good decomposition prompt is explicit that scope, conditions, and hedges are first-class claims.
L: Link: bind each claim to a span
The Link step is where "the model cited a source" becomes "the model's claim is supported by a specific span." This is the inversion from Chapter 1, made into a step: the citation must be derived from the binding, not generated alongside the claim. Concretely, after decomposition you attempt to locate, for each claim, the span in the retrieved evidence (or the tool result, or the state record) that supports it.
def link_claims(claims: list[AtomicClaim], evidence: list["Span"], linker) -> None:
"""For each claim, find the best supporting span. Mutates claims in place."""
for claim in claims:
candidate = linker.best_span(claim.text, evidence) # retrieval + scoring
if candidate and candidate.score >= linker.link_threshold:
claim.supporting_span = candidate.text
claim.source_id = candidate.source_id
# claims with no span survive to the Inference step as "unlinked"Two outcomes from the Link step already matter. A claim that finds a strong span is potentially supported, the Inference step still has to confirm the span actually entails the claim rather than merely sharing vocabulary. A claim that finds no span is an immediate flag: it is either extrinsic hallucination or a claim the system should not be making. The RAGAS framework's context precision and context recall metrics live at this step, they measure whether the retrieved context even contains the spans the answer needs, which determines whether linking could succeed at all. If context recall is low, the Link step will fail for reasons that have nothing to do with the model: the evidence was never there to link to.
A: Authority: a real source can still be the wrong source
Authority is the step teams skip most often, because a found link feels like success. But a link to a real span only establishes faithfulness, not factuality (Chapter 2). Authority asks three sub-questions of the linked source:
- **Allowed? ** Is this user permitted to see this source? A claim supported by a document the user has no access to is a leak, not an answer.
- **Current? ** Is the source the current version, or has it been superseded? The introduction's water-damage example and the litigation example both turned on a real source that was stale. A claim faithfully supported by an obsolete addendum is a faithful falsehood.
- **Authoritative? ** Is this source the right kind of source for this claim? A community forum post and a regulatory filing can both contain the string "the limit is 10mg"; only one is authoritative for a dosing claim.
@dataclass
class AuthorityCheck:
allowed: bool
current: bool
authoritative: bool
@property
def passes(self) -> bool:
return self.allowed and self.current and self.authoritative
def check_authority(claim: AtomicClaim, source_index) -> AuthorityCheck:
src = source_index[claim.source_id]
return AuthorityCheck(
allowed=source_index.user_can_read(claim.source_id),
current=not src.superseded and (src.valid_until is None or src.valid_until > now()),
authoritative=src.authority_tier <= source_index.required_tier(claim.claim_type),)Authority is where the book's faithfulness-first strategy reconnects to factuality. You make a governed corpus the source of truth, and Authority enforces that claims rest only on the parts of it that are allowed, current, and of sufficient authority for the claim type. The truth problem has not vanished; it has moved to corpus curation, where you can actually manage it, and retrieval-augmented generation is the architectural pattern that makes that governed corpus the model's primary evidence source.
I: Inference: the gap between a link and a justification
The Inference step is the subtlest and the one that separates a real verifier from a citation-format checker. A claim can have a strong link, high lexical and semantic overlap with a span, and still not be entailed by that span. The span talks about the topic; the claim asserts something the span does not actually say. This is the litigation failure in its purest form: the cited opinion was about force majeure, scoring high on any similarity metric, while saying nothing about the asserted holding.
Inference therefore requires an entailment judgment, not a similarity judgment, and the distinction is the difference between catching citation laundering and waving it through. Entailment asks: if the span is true, must the claim be true? Similarity asks: do these two texts talk about the same thing? Citation laundering scores high on the second and fails the first.
def check_inference(claim: AtomicClaim, entailer) -> str:
"""Classify the relationship between the linked span and the claim."""
if claim.supporting_span is None:
return "UNLINKED" # extrinsic: nothing to entail
relation = entailer.classify(claim.supporting_span, claim.text)
# relation in {"entails", "neutral", "contradicts"}
if relation == "entails":
return "SUPPORTED"
if relation == "contradicts":
return "CONTRADICTED" # intrinsic hallucination
return "OVERREACH" # span is on-topic but does not entailThe three non-supported outcomes, UNLINKED, CONTRADICTED, OVERREACH, are the three hallucination signatures, and they map straight onto the taxonomy: extrinsic synthesis, intrinsic contradiction, and citation laundering. A system that only checks similarity sees OVERREACH as success. The entailment check is what makes Inference more than retrieval.
M: Mitigation: answer is one option among five
The final step is the one most systems do not have at all, because they only know how to answer. CLAIM's M step turns the per-claim verdicts into a response policy with five possible actions:
| Situation across claims | Action | Why |
|---|---|---|
All claims SUPPORTED, authority passes | Answer | The chain is intact end to end |
Some claims OVERREACH or UNLINKED, but fixable | Revise | Drop or hedge the unsupported claims, re-answer |
| Query was ambiguous; evidence is fine | Ask | Clarify before answering; ambiguity drove the gap |
Core claims UNLINKED and not recoverable | Abstain | No evidence exists; say so (Chapter 13) |
CONTRADICTED or high-stakes + authority fails | Escalate | Hand to a human; the cost of being wrong is high |
def decide(claims: list[AtomicClaim], query_ambiguous: bool, stakes: str) -> str:
verdicts = [c.label for c in claims]
if any(v == "CONTRADICTED" for v in verdicts):
return "ESCALATE" if stakes == "high" else "REVISE"
core_unsupported = [c for c in claims
if c.is_core and c.label in ("UNLINKED", "OVERREACH")]
if not core_unsupported:
return "ANSWER"
if query_ambiguous:
return "ASK"
if stakes == "high":
return "ESCALATE"
if recoverable(core_unsupported):
return "REVISE"
return "ABSTAIN"The decision is intentionally conservative and intentionally stakes-aware. The same set of verdicts produces a "revise" in a low-stakes internal tool and an "escalate" in a clinical or legal context. This is the practical face of calibration (Chapter 5) and abstention (Chapter 13): the system's willingness to refuse should scale with the cost of being wrong, and that cost is a product decision, not a model property.
CLAIM is a lens, not a liturgy
A warning, because frameworks invite ritual. CLAIM is not a five-section template to staple onto every feature. Not every claim needs all five checks at full strength; the weight you put on each step is a function of stakes and latency budget. A casual internal search tool might run a cheap Link-and-Inference pass and skip a formal Authority tier. A clinical decision-support tool runs all five with human review wired into M by default. The discipline CLAIM enforces is not "always do all five", it is "for every factual claim, be able to say where its link is, whether its source has authority, and what you would do if it didn't." A system that cannot answer those questions for its own outputs is not grounded; it is decorated, like the litigation system's citations.
Used this way, CLAIM also gives a team a shared vocabulary for failures, which is half the battle."The model hallucinated" becomes "the claim was OVERREACH at the Inference step on a source that also failed Authority because it was stale", a sentence that tells three different engineers what to fix. The framework's real product is that sentence.
Chapter summary
CLAIM is the control flow of an anti-hallucination system: Claim (decompose the output into atomic, independently checkable claims, preserving qualifiers), Link (bind each claim to a specific supporting span, not a document, with RAGAS-style context recall determining whether linking can even succeed), Authority (confirm the linked source is allowed, current, and authoritative, the bridge from faithfulness back to factuality), Inference (test entailment, not similarity, because citation laundering scores high on similarity and fails entailment, yielding the three hallucination signatures UNLINKED, CONTRADICTED, OVERREACH), and Mitigation (turn the per-claim verdicts into one of five actions: answer, revise, ask, abstain, escalate, weighted by stakes). The order is a true pipeline: each step consumes the previous step's output. The framework's most important contribution is making "answer" only one of five legitimate outcomes; a calibrated abstention or a clarifying question is often the correct, highest-value response. CLAIM is a lens whose step weights scale with stakes, not a liturgy run identically every time. The next movement steps back to ask why fluent models produce unsupported claims in the first place, starting with a working taxonomy of hallucination and the mechanism CLAIM is built to contain, then turning to fluency as the disguise that makes those claims hard to catch.