Fluency Is Not Evidence
> **Working claim: ** A language model is an engine for producing probable continuations of text.

Fluency is not evidence because a language model can produce probable text without proving that any claim is supported.
Key Takeaways
- Next-token fluency is a language signal, not a truth signal.
- Instruction tuning and RLHF improve helpfulness but do not turn the model into a fact-checker.
- Decoding settings change variance and repetition; they do not create missing evidence.
- Scale helps broad capability and can still amplify learned falsehoods when the training text contains common errors.
Read this with the CLAIM Framework, model calibration, and the AI-Native thesis.
**Working claim: ** A language model is an engine for producing probable continuations of text. Probability of text and truth of claims are correlated through the training data but are not the same quantity, and the model has no separate channel for "I am now stating something I cannot support." Hallucination is not a malfunction of this engine. It is the engine working exactly as designed, applied to a question where the most probable continuation is not the true one.
The objective the model was actually trained on
Start with what the model optimizes, because every downstream behavior is a shadow of it. A base language model is trained to predict the next token given the preceding tokens, minimizing the difference between its predicted distribution and the distribution of human-written text. The loss it minimizes rewards one thing: assigning high probability to the token a human actually wrote next. It does not, anywhere in that loss, contain a term for "is this claim true." Truth enters only indirectly, to the extent that true statements were more common in the training text than false ones, which, for many topics, they were, and for many others, they emphatically were not.
This is the mechanical root of the book's motif. Fluency is not evidence because fluency, assigning high probability to a coherent continuation, is the entire objective, and truth is a correlate, not a constraint. When you ask the model a question, it does not consult a fact and then phrase it. It produces the continuation that the training distribution makes probable. If the true continuation was well represented in training, the probable continuation tends to be true. If it was not, because the fact is rare, recent, private, or simply absent, the model still produces a probable continuation, shaped like the answers it has seen, and that continuation is a guess wearing the clothing of a fact.
There is no internal flag that fires when the model crosses from "recalling" to "guessing." The same machinery produces both, with the same fluency, often with the same surface confidence. A human expert who does not know an answer usually sounds different, they hedge, they say "I think, " they slow down. The model has learned the form of confident expertise from text where the author actually was confident and correct, and it reproduces that form whether or not it has the substance. This is why a fabricated citation reads exactly like a real one: the model learned the shape of a citation, and the shape is all it needs to produce.
Why "be truthful" is a weak instruction
This mechanism explains why the most common reflexive fix, adding "be truthful and do not make things up" to the system prompt, is so weak. The instruction conditions the model toward text that looks like careful, hedged, truthful writing. It can genuinely help on the margins: it shifts the distribution toward more cautious phrasings, more "I'm not sure, " fewer flat assertions on shaky ground. But it does not give the model a fact it does not have, and it does not install a verification step. It changes the style of the continuation, not its grounding. A model told to be truthful will, on a question it cannot answer, often produce a fluently hedged falsehood instead of a fluently confident one, which is sometimes better and sometimes worse, because a hedge can read as informed caution rather than as "I am guessing."
InstructGPT and the RLHF line of work strengthen this lever considerably: tuning on human preferences for helpful, honest, harmless responses does shift the model toward appropriate hedging and refusal, and reduces some classes of confident fabrication. This is real and worth using. But the same work shows the lever has limits and side effects, alignment can induce over-refusal or sycophancy, and preference tuning optimizes for what raters liked, which is correlated with, but not identical to, what was true. The honest summary: instruction and preference tuning move the distribution toward better-calibrated language. They do not turn the model into a fact-checker, because the underlying engine is still producing probable text.
Where probable and true diverge: a catalog
It helps to name the specific situations where the most probable continuation is reliably not the true one, because each is a distinct hallucination generator and each has a different mitigation.
**Missing knowledge. ** The fact was never in the training data, or was too rare to be learned. The model has no stored signal, so it interpolates from neighbors, producing a plausible value shaped like the right kind of answer. This is the dominant source of fabricated entities and citations. Mitigation: retrieval (put the fact in the context) or abstention (admit the gap).
**Stale knowledge. ** The fact was in training, but the world changed after the training cutoff. The model confidently reports the old value, because the old value is exactly what its parameters encode. Parametric memory is undated, the model cannot tell you when it learned something, and it has no mechanism to prefer recent over old. Mitigation: retrieval against a current source, and an Authority check (Chapter 3) that prefers current evidence over parametric memory.
**Overgeneralization. ** The model has learned a pattern, "drugs in this class are dosed at X", and applies it to a case where the pattern does not hold. The continuation is probable given the pattern and wrong given the specifics. This produces subtly wrong attributes and is hard to catch because it is usually right. Mitigation: require a specific span for specific claims; do not let pattern-completion substitute for evidence.
**Learned falsehood. ** The false answer was more common in training than the true one. This is TruthfulQA's domain: questions tied to popular misconceptions, where the most probable continuation is the misconception. The chilling finding is that scale can worsen this, because a larger model imitates the human distribution more faithfully, including its confident errors. Mitigation: external fact-checking against authoritative sources; you cannot prompt your way out of a falsehood the model learned as the majority view.
**Ambiguity. ** The query underspecifies the answer, so multiple continuations are probable. The model picks one, often the most common interpretation, and answers it confidently, as if the ambiguity did not exist. Mitigation: detect ambiguity and ask (the M-step's "ask" branch) rather than guessing which question to answer.
**Conflicting context. ** The prompt contains contradictory evidence (the stale exclusion clause and the current addendum). Multiple continuations are now consistent with parts of the context, and the model resolves the conflict by some opaque mixture of recency, position, length, and confidence of phrasing, not by a principled currency rule. Mitigation: resolve conflicts in code before generation; never hand the model two contradictory facts and hope.
This catalog is the mechanistic backbone of the whole book. Every later chapter is, in effect, a mitigation aimed at one or more of these six divergence points, which is why The CLAIM Framework organizes the mitigations along exactly this causal chain.
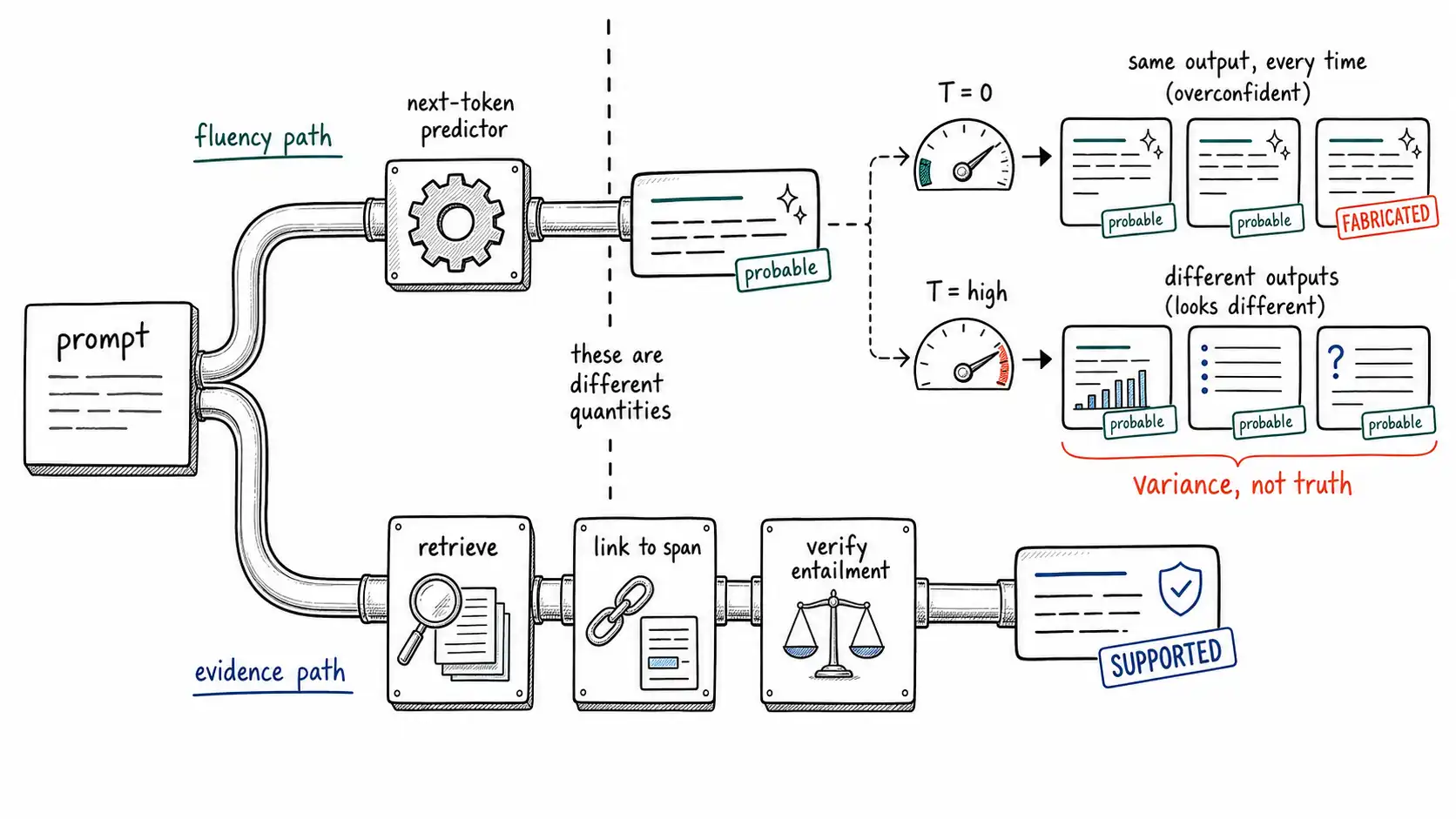
Decoding changes the variance, not the grounding
A persistent misconception deserves direct refutation, because it drives a popular non-fix: *lowering the temperature reduces hallucination. * It does not, except in a narrow and easily-misread sense.
Decoding parameters, temperature, top-p (nucleus sampling), top-k, control how the model samples from its predicted distribution over the next token. Temperature 0 (greedy) always takes the most probable token; higher temperatures sample more adventurously from the tail. What this controls is the variance of the output: how much two generations of the same prompt differ. It does not change which facts the model has, which spans support a claim, or whether the most probable continuation is true.
def sample_diversity(prompt, model, temps=(0.0, 0.7, 1.2), n=5):
"""Show that temperature controls variation, not grounding.
At T=0 you get one answer repeatedly; at high T you get varied answers --
but a fabricated fact can be the *most probable* token and survive T=0."""
out = {}
for t in temps:
out[t] = [model.complete(prompt, temperature=t, seed=i) for i in range(n)]
return outHere is the trap, stated precisely. If the model's most probable continuation is a fabrication, because the fact is missing, stale, or a learned falsehood, then *temperature 0 produces that fabrication every single time, with maximum confidence. * Lowering temperature can make a fabrication more consistent, not less likely. What lowering temperature does help with is reducing the chance that a high-temperature sample wanders into a fabrication that the greedy decode would have avoided. So for tasks where the greedy answer is right, low temperature reduces noise around it; for tasks where the greedy answer is wrong, low temperature locks the error in. Temperature is a noise knob, not a truth knob.
This same fact is what makes self-consistency (Chapter 11) work as a detector: sampling several generations at a nonzero temperature and watching whether they agree. If the model knows the answer, the samples converge; if it is guessing, they scatter. SelfCheckGPT builds a black-box hallucination detector on exactly this principle, disagreement across stochastic samples signals unsupported content. The same temperature that cannot fix a hallucination at generation time can help expose one at detection time, which is the right division of labor.
Does scale fix this?
The most expensive non-fix is "use a bigger model." Scale genuinely helps with several of the divergence points: larger models have more knowledge, so the missing-knowledge case shrinks; they generalize better, so some overgeneralization errors fall; and combined with instruction tuning they hedge more appropriately. The LLM hallucination survey catalogs these gains honestly. But scale does not touch the structure of the problem. A bigger model still has a training cutoff, so stale knowledge persists. It still has no internal grounding channel, so it still produces confident continuations on questions it cannot support. And on learned falsehoods, TruthfulQA showed scale can hurt. The practical conclusion: a bigger model reduces the rate of some hallucination types and simultaneously makes the ones that remain harder to catch, because they are wrapped in more fluent, more authoritative prose. Reducing rate while reducing detectability is not obviously a win for a high-stakes system. It is a reason to invest in verification, not to skip it.
Chapter summary
A language model minimizes the prediction error on human text; truth is a correlate of that objective, never a term in it. The model produces the most probable continuation, and has no separate channel that fires when it crosses from recalling to guessing, so a fabricated fact arrives with the same fluency as a real one, which is why "be truthful" only restyles the output and cannot install grounding. Probable and true diverge predictably at six points: missing knowledge, stale (undated) parametric memory, overgeneralization, learned falsehoods (TruthfulQA, where scale can hurt), ambiguity, and conflicting context, and every later mitigation targets one of these. Decoding parameters control the variance of outputs, not their grounding: temperature 0 reproduces a fabrication every time if the fabrication is the most probable token, so lowering temperature is a noise knob, not a truth knob, though that same stochasticity is what makes self-consistency a useful detector. Scale shrinks some failure rates while making the survivors more fluent and harder to catch, which is an argument for verification, not against it. The next chapter asks the natural follow-up: if the model has no grounding channel, does it at least know when it is guessing? The answer, partly, fragilely, is the subject of What Models Know About What They Know.