The Compression Press
> **Working claim: ** Summarization and transformation feel safer than open-domain question answering because the source is right there, but the source's presence creates a false sense of grounding.

Summarization hallucination is a compression failure: the source is present, but the output adds, smooths, or strengthens claims the source never made.
Key Takeaways
- Summarization feels safer than open-ended answering because the source is visible; that comfort is false without span checks.
- Named slots like decisions and action items pull content into existence when the meeting never made that decision.
- Dropped qualifiers, number drift, entity swaps, and multi-document conflation need claim-level verification and numeric gates.
- Domain stakes change the threshold and consequence, not the core verification method.
Read this with citation hallucination, hallucinated actions, and human-in-the-loop evaluation.
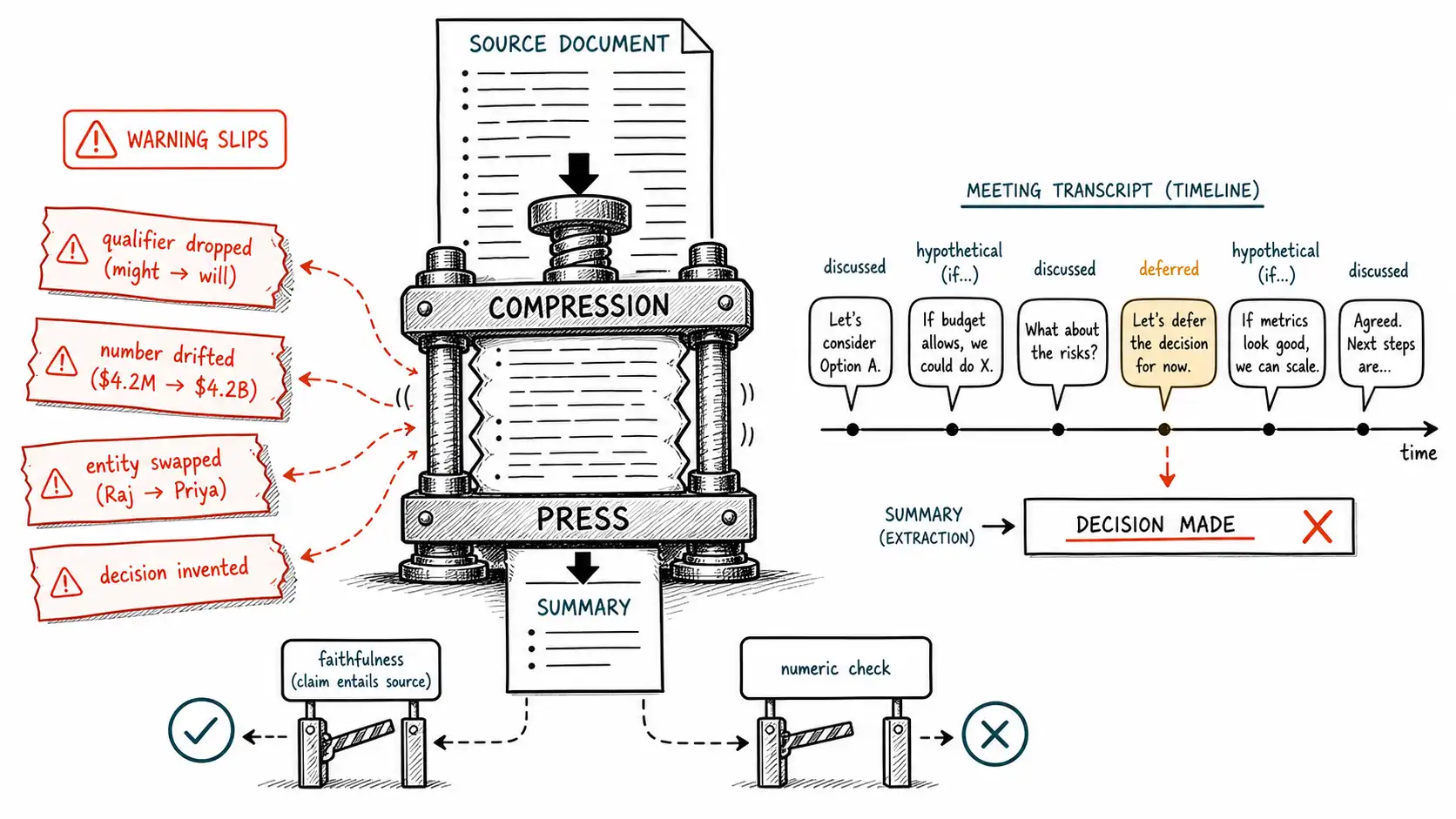
**Working claim: ** Summarization and transformation feel safer than open-domain question answering because the source is right there, but the source's presence creates a false sense of grounding. Compression is where qualifiers die, numbers drift, entities swap, and decisions get invented. The dangerous summary is not the one that obviously fabricates; it is the one that is 95% faithful and silently drops the word that changes the meaning.
A decision that was never made
A product team shipped an internal meeting-summarizer: drop in a transcript, get back a tidy summary with a "decisions" and "action items" section. It was beloved for a quarter. Then a manager acted on a summary that read: "Decision: migrate the billing service to the new vendor by end of Q2. Action item: Priya to begin vendor onboarding." Priya had not agreed to anything. The transcript, read back, showed the team discussing the migration, raising concerns about timeline, and explicitly deferring the decision to the next meeting. Someone had said, "if we did this, Priya would probably own onboarding", a hypothetical. The summary converted a hypothetical into a decision and a speculation into an assignment.
No source was missing. No retrieval failed. The entire transcript was in the context. This is the lesson of the chapter: **having the source does not prevent hallucination; it just changes which kind you get. ** Summarization hallucination is overwhelmingly a transformation failure, the model, asked to compress, fills the expected slots ("decisions, " "action items") whether or not the source supports them, and smooths hedged, conditional, messy human speech into clean, confident prose. The smoothing is the hallucination.
The summarization failure family
The NLG hallucination survey was written largely around summarization and data-to-text generation, and its intrinsic/extrinsic distinction is sharpest here because the source is fixed and present.
Intrinsic summarization errors contradict the source. The transcript says the decision was deferred; the summary says it was made. The source contains the refutation, which makes these detectable by a contradiction check, and yet they routinely ship, because the check is rarely run.
Extrinsic summarization errors add content the source does not contain. The summary mentions a vendor name, a dollar figure, or a deadline that appears nowhere in the transcript. There is nothing to contradict, so a contradiction check passes them; only a coverage check, is every claim in the summary entailed by the source?, catches them. Extrinsic errors are the more common in fluent modern models, because the model is good at not directly contradicting the source and bad at not embellishing it.
Within these two families, specific, recurring micro-failures deserve names because each has a targeted check:
- **Entity swap. ** Two people, products, or dates in the source get crossed in the summary: "Priya will do X" when the source had Raj doing X. Catchable by checking that each entity-action pair in the summary matches a pair in the source.
- **Number, date, and unit drift. ** "$4.2M" becomes "$4.2B"; "12%" becomes "20%"; "by end of Q2" becomes "by June 2." Numbers are uniquely dangerous because they are specific and consequential and the model treats them as ordinary tokens. Catchable by extracting every number from source and summary and checking each summary number against the source.
- **Dropped qualifier. ** The deadliest micro-failure. The source says "we might migrate if the contract allows"; the summary says "we will migrate." The hedge, the condition, the scope, all stripped. This is how a hypothetical becomes a decision. Catchable only by a check that treats qualifiers as first-class claims (Chapter 3's decomposition discipline; FActScore quantifies the cost of skipping this step).
- **Overcompression collapse. ** Compressing too aggressively forces the model to merge distinct points, and the merge invents a relationship the source did not assert. Two separate facts become one false causal claim.
- **Multi-document conflation. ** Summarizing several sources, the model attributes a fact from document A to document B, or merges contradictory figures into a single smoothed number. This is the summarization analogue of retrieval conflict.
Why the "decisions" section is structurally dangerous
The meeting-summarizer failure was not bad luck; it was a structural trap that every slot-filling summarizer falls into. When you ask for a "decisions" section, you create a slot the model is strongly biased to fill, because in its training data, "decisions" sections contain decisions. An empty decisions section is a rare and low-probability output. So when a meeting reaches no decision, the model faces a conflict between the source (no decision) and the format prior (decisions sections have content), and the format prior frequently wins. The same trap governs "action items, " "key takeaways, " and "next steps", any named slot pulls content into existence.
The mitigation is partly prompt design and partly verification. On the prompt side, the format must explicitly license emptiness: "If no decision was reached, write 'No decisions were finalized.' Do not infer decisions from discussion." On the verification side, every item in a decisions/action-items section must be traceable to a span where someone committed, not merely discussed, which is an entailment check with a specific bar: the span must support not just the content but the modality (decided, not considered; assigned, not suggested).
Claim extraction and source-span alignment for summaries
The verification machinery is the same CLAIM pipeline, specialized for the summary-against-source case where the "retrieval" is trivial (the source is the whole document). The pipeline: extract atomic claims from the summary, align each to a source span, classify the relationship, and report coverage and faithfulness.
def verify_summary(summary: str, source: str, extractor, aligner, entailer):
"""Return per-claim verdicts for a summary against its source."""
claims = extractor.decompose(summary) # atomic claims incl. qualifiers
report = []
for claim in claims:
span = aligner.best_span(claim, source) # may be None
if span is None:
verdict = "EXTRINSIC" # added; source has no such span
else:
rel = entailer.classify(span, claim)
verdict = {"entails": "SUPPORTED",
"contradicts": "INTRINSIC", # source says otherwise
"neutral": "EXTRINSIC"}[rel] # span on-topic, doesn't entail
report.append({"claim": claim, "span": span, "verdict": verdict})
return report
def faithfulness_score(report) -> float:
"""RAGAS-style faithfulness: fraction of claims SUPPORTED by the source."""
if not report:
return 1.0
return sum(r["verdict"] == "SUPPORTED" for r in report) / len(report)This is exactly RAGAS's faithfulness metric, the fraction of generated claims entailed by the provided context, applied to summarization, and it is the single most useful number for a summarizer. The SummaC line of work shows that NLI models, applied at the right granularity (sentence-to-sentence rather than document-to-document, which washes out the signal), are effective inconsistency detectors for summaries, which is the practical basis for the entailer above. The granularity lesson from SummaC is important: run entailment at the claim-to-span level, not summary-to-document, or the signal drowns.
Numeric consistency as a separate gate
Numbers deserve their own check, because they are high-consequence and because entailment models handle them poorly, an NLI model may rate "$4.2M" and "$4.2B" as entailing because they are lexically near. A dedicated numeric gate extracts and compares figures directly.
import re
def numeric_consistency(summary: str, source: str) -> list[dict]:
"""Flag any number in the summary not matched (within tolerance) in the source."""
num_re = re.compile(r"\$?\d[\d,]*\.?\d*\s?(?:%|million|billion|M|B|bn|k)?", re. I)
src_nums = {normalize(m.group()) for m in num_re.finditer(source)}
flags = []
for m in num_re.finditer(summary):
val = normalize(m.group())
if val not in src_nums and not any(close(val, s) for s in src_nums):
flags.append({"summary_number": m.group(), "status": "UNSOURCED"})
return flagsA summarizer for finance, healthcare, or legal use should run this gate and block or flag any unsourced number before the summary is shown. The cost of a $4.2M → $4.2B drift in a financial summary is not hypothetical, and no amount of general faithfulness scoring reliably catches a single transposed magnitude.
Domain stakes change the bar, not the method
The method is constant; the threshold and the consequence scale with the domain, and a summarizer that ignores this ships the same faithfulness bar to a chat-log digest and a discharge summary.
- A meeting or chat summarizer can tolerate occasional extrinsic smoothing in a low-stakes recap, but must never invent decisions or action items, those become commitments people act on. License emptiness explicitly; verify decision/action modality.
- A medical summarizer (visit notes, discharge instructions) cannot tolerate dropped qualifiers ("take as needed" vs."take daily"), entity swaps (medication names), or numeric drift (dosages). Every clinical claim needs span-level support and a numeric gate, and the system should abstain or escalate rather than guess.
- A legal or financial summarizer faces the same numeric and qualifier sensitivity, plus a specific danger around materiality: dropping a qualifier can change a hedged forward-looking statement into an assertion with regulatory consequences. Faithfulness must be near-perfect, and conclusions must be flagged as inference, not stated as source content.
The unifying point: the verification machinery, decompose, align, classify, numeric-check, is the same everywhere. What changes is the abstention threshold (Chapter 13) and whether a failed check blocks, flags, or escalates. A summarizer without these gates is not "lower quality"; it is uninspected, and the difference shows up exactly when the stakes are highest.
Chapter summary
Summarization and transformation feel safe because the source is present, but the source's presence only changes which hallucination you get, it does not prevent it. The dominant failure is transformation-driven: the model fills expected slots ("decisions, " "action items") whether the source supports them and smooths hedged human speech into confident prose, converting hypotheticals into decisions and speculation into assignments. The failure family splits into intrinsic (contradicts the source, catchable by contradiction checks) and extrinsic (adds unsupported content, catchable only by coverage checks), with named micro-failures: entity swap, number/date/unit drift, the deadly dropped qualifier, overcompression collapse, and multi-document conflation. Named output slots are structurally dangerous because the format prior pulls content into existence against an empty source; the fix is to license emptiness explicitly and verify the modality of decision/action claims. The verification machinery is CLAIM specialized for the source-present case: decompose into atomic claims (including qualifiers), align each to a span, classify with claim-to-span NLI (the SummaC granularity lesson), and report RAGAS-style faithfulness, plus a separate numeric gate because entailment models handle magnitudes poorly. The method is constant across domains; the abstention threshold and the cost of failure scale with the stakes. For open-ended settings without a fixed source, SelfCheckGPT offers a complementary zero-resource consistency check across samples. The next movement raises the stakes again: agents that do not just describe the world but act on it, and the hallucination that invents actions, the natural successor to a citation that is not proof.