Claim Extraction and Source-Span Verification
> **Working claim: ** Detection is a pipeline, not a verdict. To find unsupported claims you must first *extract* them, then *link* each to a candidate span, then *classify* the link as entailment, contradiction, or neither, then *decide* per claim.

Source span verification turns hallucination detection into a pipeline: extract the claim, find a candidate span, classify entailment, then decide.
Key Takeaways
- Detection is a pipeline, not a verdict, and each stage can fail independently.
- Claim extraction must preserve qualifiers, numbers, dates, and action claims because those are where support often breaks.
- Similarity is not enough; the verifier needs entailment, contradiction, or neither for each linked span.
- Answer-level faithfulness should be rolled up from per-claim verdicts, then routed into mitigation.
Read this with hallucinated actions, self-consistency and judges, and llm evaluation framework.
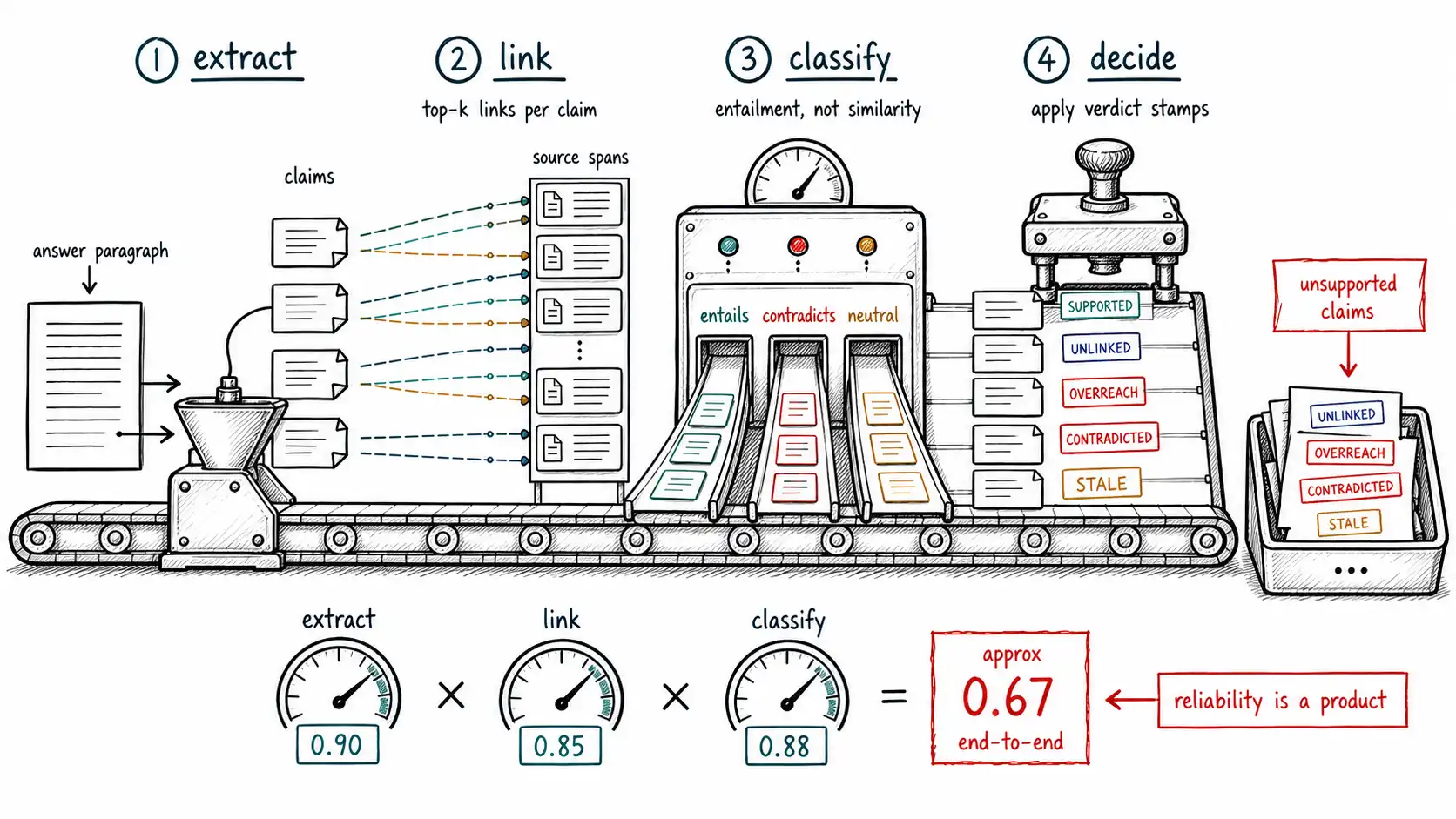
**Working claim: ** Detection is a pipeline, not a verdict. To find unsupported claims you must first extract them, then link each to a candidate span, then classify the link as entailment, contradiction, or neither, then decide per claim. Each stage has its own error rate, and the pipeline's overall reliability is the product of them. A "hallucination detector" that skips extraction and judges whole answers is measuring almost nothing (see Survey of Hallucination in Natural Language Generation (Ji et al.) for the taxonomy of failure types this pipeline must cover).
The four-stage verification pipeline
The CLAIM framework named the checks; this chapter builds them as running code, because the gap between "we should verify claims" and a working verifier is where most teams stall. The verifier is a four-stage pipeline, and seeing it as stages, each independently improvable, each independently fallible, is what makes it tractable.
answer → [1] EXTRACT → atomic claims
→ [2] LINK → (claim, candidate span)
→ [3] CLASSIFY → entails | contradicts | neutral
→ [4] DECIDE → per-claim verdictThe decomposition matters because each stage fails differently. Extraction can split badly, merging two facts or dropping a qualifier. Linking can retrieve the wrong span, so classification judges the wrong pair. Classification can misjudge entailment. And the decision policy can set the wrong bar. Treating the verifier as one black box ("is this hallucinated?") hides which stage is failing and makes it unimprovable. The FEVER task, extract a claim, retrieve evidence, classify as Supported / Refuted / NotEnoughInfo, is the canonical formalization of exactly this pipeline, and its three-way label (note the NotEnoughInfo) is the one your verifier needs, because "neither supported nor refuted" is where extrinsic hallucination lives.
Stage 1: claim extraction
Extraction turns fluent prose into atomic, independently checkable claims. FActScore established the methodology and showed it matters: paragraph-level judgment hides the supported/unsupported mix. The extractor is usually an LLM under a strict instruction, and the instruction quality determines everything downstream.
EXTRACTION_PROMPT = """Decompose the text into atomic factual claims.
Rules:
- Each claim must be a single, minimal, independently verifiable statement.
- Split conjunctions: "approved in 2019 for adults" -> TWO claims.
- Preserve qualifiers AS SEPARATE CLAIMS: "effective for adults" yields a
claim "the indication is adults" -- never drop scope, conditions, or hedges.
- Do not add information not present in the text.
- Mark each claim's type: existence | attribute | numeric | relation | qualifier | action.
Return JSON: [{"text": ..., "type": ...}]
"""
def extract_claims(answer: str, llm) -> list[AtomicClaim]:
raw = llm.json(EXTRACTION_PROMPT, answer)
return [AtomicClaim(text=c["text"], claim_type=ClaimType(c["type"])) for c in raw]Two failure modes to guard against in extraction itself. First, under-splitting: leaving a compound claim intact so a partly-supported sentence passes as supported. Second, the one teams miss, the extractor itself can hallucinate, adding a claim the text did not make, or paraphrasing a claim into something subtly different. The guard is to require that each extracted claim be grounded in the answer text (you can run a quick entailment of claim against the original answer), so the extractor cannot invent claims to verify. The verifier verifying a hallucinated claim is a real and embarrassing failure.
Stage 2: linking to candidate spans
Linking finds, for each claim, the span most likely to support or refute it. This is a retrieval problem inside the verifier, and it inherits all of Chapter 6's retrieval failures in miniature: if linking retrieves the wrong span, classification judges the wrong pair and the verdict is meaningless. Use hybrid retrieval (lexical + dense) over the evidence, and, critically, retrieve multiple candidate spans per claim, because the single best lexical match is often not the one that entails.
def link_spans(claim: AtomicClaim, evidence_spans: list["Span"],
retriever, top_k: int = 3) -> list["Span"]:
"""Return the top-k candidate spans for a claim (hybrid retrieval).
Multiple candidates because the best lexical match often is NOT the entailing one."""
return retriever.search(claim.text, evidence_spans, k=top_k, mode="hybrid")A claim that retrieves no candidate span above a relevance floor is already a signal, it is the FEVER NotEnoughInfo case, and you can short-circuit to an UNLINKED verdict without running classification. This both saves cost and correctly handles extrinsic hallucination, where the whole point is that no span exists.
There is a tempting shortcut to avoid here: linking by embedding similarity alone and stopping. Embedding similarity is the right retrieval signal for finding candidates, but it is the wrong verdict signal, because two passages can be near in embedding space and stand in any logical relation, entailment, contradiction, or mere topicality. The litigation opinion and the invented holding are embedding-near (same doctrine, same vocabulary) and entailment-far. So linking deliberately stops at candidate generation and hands the candidates to classification; collapsing the two stages is how a similarity score gets mistaken for a support score, and it is the most common way a home-grown verifier silently passes citation laundering.
Stage 3: classification (entailment, not similarity)
Classification is the heart, and the place where the chapter's central distinction lives: you need entailment, not similarity. Similarity asks "are these about the same thing?"; entailment asks "if the span is true, must the claim be true?" Citation laundering and over-extension score high on similarity and fail entailment, which is exactly why a similarity threshold (cosine over embeddings) is a bad hallucination detector and a frequent source of false confidence.
def classify_claim(claim: AtomicClaim, candidates: list["Span"], nli) -> dict:
"""Classify the claim against its best candidate spans.
Return the strongest relation found across candidates."""
best = {"relation": "neutral", "span": None, "score": 0.0}
for span in candidates:
rel, score = nli.predict(premise=span.text, hypothesis=claim.text)
# rel in {"entailment", "contradiction", "neutral"}
if rel == "contradiction":
return {"relation": "contradiction", "span": span, "score": score}
if rel == "entailment" and score > best["score"]:
best = {"relation": "entailment", "span": span, "score": score}
return bestThe SummaC lesson governs the granularity: run the NLI model at the claim-to-span level, not answer-to-document, because long premises wash out the entailment signal, a contradiction buried in a long document is invisible to a document-level judgment and clear to a sentence-level one. Note also the precedence: a contradiction anywhere short-circuits to CONTRADICTED (intrinsic, the most serious), and otherwise you take the strongest entailment found. The classifier can be a specialized NLI model (cheaper, faster, narrower) or an LLM prompted to judge entailment (more flexible, more expensive, and, Chapter 11, fallible in its own ways). The choice is a cost/accuracy trade you measure, not assume.
Stage 4: per-claim decision and answer-level rollup
The decision maps relations to verdicts and rolls them up into an answer-level metric and an action.
def decide_claim(classification: dict, claim: AtomicClaim,
authority, link_floor: float = 0.5) -> str:
if classification["span"] is None or classification["score"] < link_floor:
return "UNLINKED" # extrinsic / NotEnoughInfo
if classification["relation"] == "contradiction":
return "CONTRADICTED" # intrinsic
if classification["relation"] == "entailment":
if not authority.is_current(classification["span"].source_id):
return "STALE" # supported but obsolete
return "SUPPORTED"
return "OVERREACH" # on-topic, not entailed
def answer_faithfulness(verdicts: list[str]) -> float:
"""Fraction of checkable claims that are SUPPORTED. The headline number."""
checkable = [v for v in verdicts if v!= "TRIVIAL"]
if not checkable:
return 1.0
return sum(v == "SUPPORTED" for v in checkable) / len(checkable)This rollup is RAGAS's faithfulness made explicit and extended with currency: faithfulness is the fraction of claims entailed by current, authoritative context. The per-claim verdicts feed CLAIM's M-step, a handful of UNLINKED claims in a low-stakes answer triggers revise (drop them); a single CONTRADICTED claim in a high-stakes one triggers escalate.
The pipeline's reliability is a product
The honest, load-bearing caveat of this chapter: the verifier is itself a stack of imperfect models, and its overall reliability is roughly the product of its stages' reliabilities. If extraction is 90% faithful, linking finds the right span 85% of the time, and classification is 88% accurate, the end-to-end per-claim reliability is around 0.90 × 0.85 × 0.88 ≈ 0.67 before you even account for correlated errors. This is not a reason to skip verification, an imperfect verifier that catches two-thirds of unsupported claims is enormously better than none, but it is a reason to (a) measure each stage separately so you know where the loss is, (b) tune the highest-use stage rather than guess, and (c) never present the verifier's output as ground truth. The verifier produces a signal, calibrated like any other (Chapter 5), and a sound system treats a "supported" verdict as evidence for trust, not proof of it.
def verify(answer, evidence, llm, retriever, nli, authority) -> dict:
claims = extract_claims(answer, llm)
verdicts = []
for claim in claims:
candidates = link_spans(claim, evidence, retriever)
cls = classify_claim(claim, candidates, nli)
verdict = decide_claim(cls, claim, authority)
claim.label, claim.supporting_span = verdict, (cls["span"].text if cls["span"] else None)
verdicts.append(verdict)
return {"faithfulness": answer_faithfulness(verdicts),
"claims": claims,
"unsupported": [c for c in claims if c.label in ("UNLINKED", "OVERREACH", "CONTRADICTED", "STALE")]}Reference-based versus reference-free
A framing that organizes the detection landscape. Reference-based verification checks the answer against a provided source, the RAG context, the summary's source document, a gold answer in an eval set. This is what the pipeline above does, and it is the most reliable kind, because the ground truth is concrete and the question is faithfulness. Reference-free verification has no provided source, open-domain generation, where you must check against the world. Here you either retrieve a source on the fly (turning it into reference-based, the FEVER pattern) or fall back on consistency signals (Chapter 11). The practical guidance: design your system so verification is reference-based whenever possible, give it a corpus to be faithful to, because reference-free detection is strictly harder and weaker. The architecture decision (RAG with a governed corpus) and the detectability of hallucination are the same decision.
Chapter summary
Detection is a four-stage pipeline, extract atomic claims, link each to candidate spans, classify the relation as entailment/contradiction/neutral, decide per claim, and seeing it as stages is what makes it improvable, because each stage fails differently and the verifier's end-to-end reliability is roughly the product of its stages'. Extraction (FActScore's discipline) must split compounds, preserve qualifiers as separate claims, and guard against the extractor itself hallucinating. Linking is retrieval-inside-the-verifier: retrieve multiple candidates, because the best lexical match often is not the entailing one, and treat "no candidate" as the FEVER NotEnoughInfo case where extrinsic hallucination lives. Classification must use entailment, not similarity, the distinction that catches citation laundering, at SummaC's claim-to-span granularity, with contradiction short-circuiting to the most serious verdict. The decision rolls verdicts into RAGAS-style faithfulness extended with currency, feeding CLAIM's M-step. The load-bearing caveat: the verifier is a stack of imperfect models producing a signal, not proof; measure each stage, tune the weakest, and never present "supported" as ground truth. Finally, design for reference-based verification, give the system a corpus to be faithful to, because reference-free detection is strictly harder. The chapter before this one, Hallucinated Actions, established why agent-produced action claims need the same verification treatment. The next chapter examines the consistency-based and judge-based methods you fall back on when no reference is available, and their real limits.