What Models Know About What They Know
> **Working claim: ** Models carry a real, usable signal about their own correctness, but it is fragile, format-dependent, and degraded by the very tuning that makes them helpful.

Model calibration is the gate between a model producing a claim and a system trusting that claim enough to answer.
Key Takeaways
- A calibrated confidence means claims made at probability p are correct about p of the time.
- Models carry useful self-knowledge, but alignment tuning, verbalized confidence, and surface form can distort it.
- Reliability diagrams and expected calibration error must be measured on the shipped task, not assumed from a benchmark.
- The point of calibration is abstention: set a threshold that reflects the real cost of being wrong.
Read this with fluency is not evidence, saying I do not know, and llm evaluation metrics.
**Working claim: ** Models carry a real, usable signal about their own correctness, but it is fragile, format-dependent, and degraded by the very tuning that makes them helpful. Calibration is the bridge between "the model produced a claim" and "the system should trust it." A well-calibrated confidence is the precondition for principled abstention. An overconfident one is a hallucination amplifier.
A definition worth getting right
Calibration is a precise idea that gets used loosely, so pin it down before using it. A model is calibrated if, among all the predictions it makes with stated confidence p, a fraction p of them are correct. If you collect every answer the model gave 80% confidence to, and 80% of those answers are right, the model is calibrated at that confidence level. If only 55% are right, the model is overconfident; if 95% are right, it is underconfident. Calibration is not about being right, a model can be poorly accurate but well calibrated (it knows it is often wrong) or highly accurate but badly calibrated (it is right often but claims certainty even when wrong).
For an anti-hallucination system this is the whole ballgame, because the mitigation step in CLAIM (answer / revise / ask / abstain / escalate) needs a threshold. You answer when confidence is high enough and abstain when it is not. That decision is only sound if the confidence number means what it says. A confidence of 0.9 that is correct 60% of the time will route 40% of confident fabrications straight to the user. **Calibration is what makes a confidence threshold safe. **
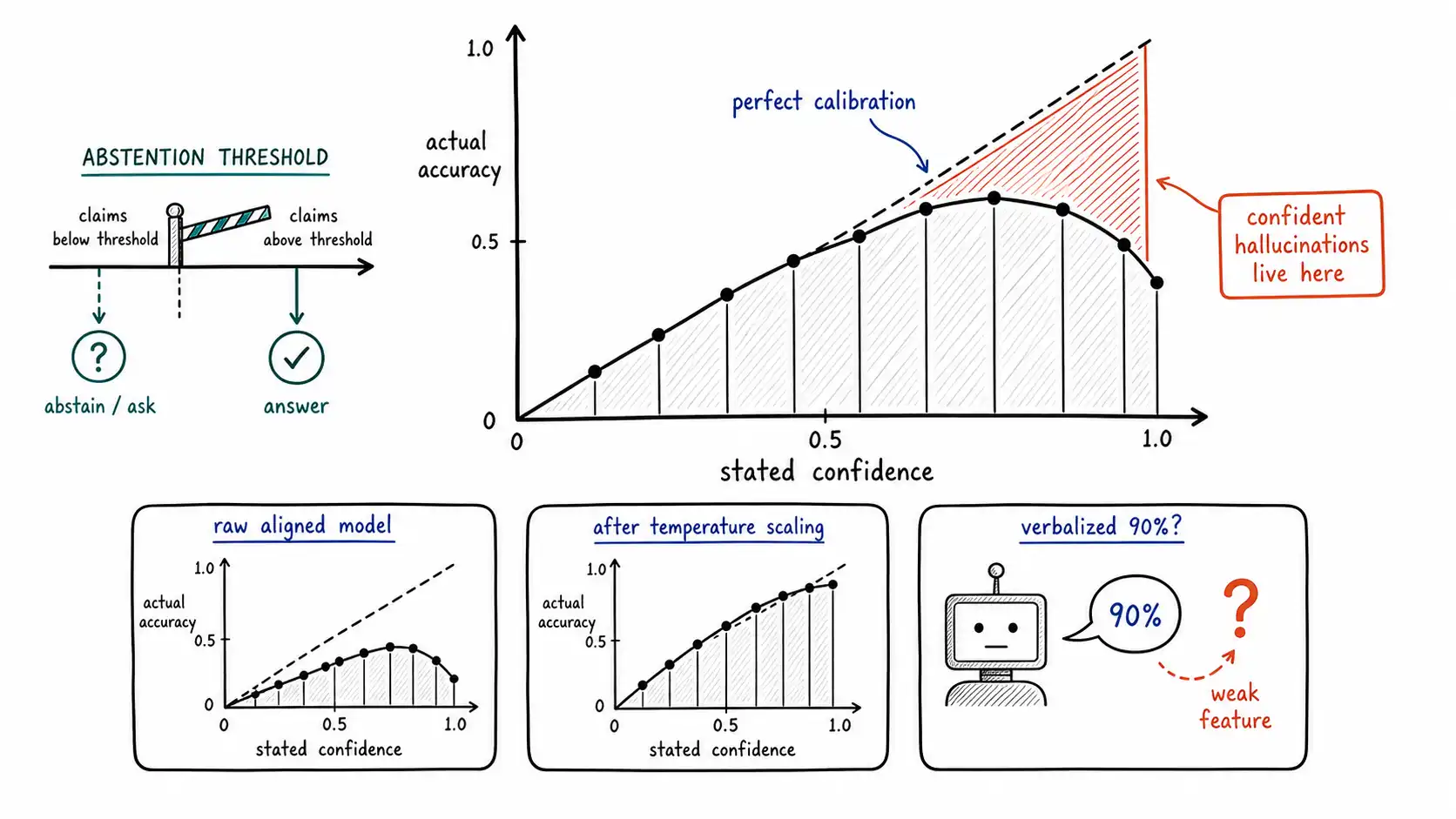
The encouraging result, stated carefully
The hopeful finding is that models do carry self-knowledge. Language Models (Mostly) Know What They Know showed that large models can produce a probability that their own answer is correct (the paper calls it P(True)), and that this self-evaluation is reasonably calibrated on many tasks, the model's expressed confidence tracks its actual accuracy better than chance, and improves with scale. Relatedly, the probability the model assigns to a multiple-choice answer is often well calibrated: when it puts 70% mass on option C, option C is right about 70% of the time. The word doing the heavy lifting in the title is mostly. There is signal. It is exploitable. It is not a guarantee.
The mechanism behind this is intuitive once you accept Chapter 4. If the model has seen a fact represented consistently in training, the probability mass on the right token is concentrated; if the fact is rare or contested, the mass is spread out. That spread is uncertainty, encoded in the logits. The model "knows it is guessing" in the limited sense that its distribution over next tokens is flatter when it is guessing. The art of calibration is extracting that signal and turning it into a usable number.
The discouraging results, stated just as carefully
Three findings keep this from being a happy ending, and a system that ignores them will trust confidence numbers it should not.
**Calibration degrades with alignment tuning. ** The same RLHF that makes a model helpful and well-mannered tends to hurt calibration on the raw probability sense. A base model's token probabilities are often better calibrated than the same model after instruction tuning, because preference optimization pushes outputs toward confident, fluent, rater-pleasing phrasings, and confidence in phrasing leaks into confidence in probability. InstructGPT and subsequent work document this trade: you get a more helpful assistant and a less calibrated probability. The practical consequence is that you cannot assume the polished, aligned model you ship with is as calibrated as the benchmark numbers from a base model suggest.
**Verbalized confidence is unreliable. ** Asking the model "how confident are you, 0 to 100%?", verbalized uncertainty, is attractive because it needs no logit access. Teaching Models to Express Their Uncertainty in Words showed this can be trained to be reasonably calibrated, but out of the box it is shaky: models gravitate to round, high numbers (90%, 95%), show poor resolution (everything is "pretty confident"), and can be calibrated on one task and miscalibrated on the next. Treat a model's stated confidence as a weak feature, not as a probability, unless you have measured its calibration on your task.
**Surface form confuses confidence. ** A model can give the same answer two ways, "Paris" and "The capital is Paris, of course", and the token probabilities differ even though the meaning is identical. Naive confidence (probability of the exact tokens) conflates uncertainty about wording with uncertainty about facts. Semantic Uncertainty addresses this by clustering multiple samples into meaning groups and measuring entropy over meanings rather than over token strings, the model is uncertain about a fact only if its samples spread across different answers, not merely different phrasings. This is the cleanest available notion of "is the model unsure about the substance, " and it connects directly to self-consistency in Chapter 11.
Measuring calibration on your own system
As with everything in this book, the only calibration number that matters is the one for your model, your prompt format, and your task distribution. The instrument is a reliability diagram and its summary statistic, Expected Calibration Error (ECE), formalized for neural networks in Guo et al.. You bin predictions by stated confidence, compute accuracy within each bin, and measure the gap between confidence and accuracy.
import numpy as np
def expected_calibration_error(confidences, correct, n_bins=10):
"""ECE: average gap between confidence and accuracy across confidence bins.
confidences: model's stated/derived P(correct) per item, in [0,1]
correct: 1 if the item was actually correct, else 0
"""
confidences = np.asarray(confidences)
correct = np.asarray(correct, dtype=float)
bins = np.linspace(0.0, 1.0, n_bins + 1)
ece = 0.0
for lo, hi in zip(bins[:-1], bins[1:]):
mask = (confidences > lo) & (confidences <= hi)
if mask.sum() == 0:
continue
bin_conf = confidences[mask].mean()
bin_acc = correct[mask].mean()
ece += (mask.mean()) * abs(bin_conf - bin_acc) # weighted by bin size
return ece
def reliability_table(confidences, correct, n_bins=10):
"""Return per-bin (confidence, accuracy, count) for a reliability diagram."""
confidences, correct = np.asarray(confidences), np.asarray(correct, dtype=float)
bins = np.linspace(0.0, 1.0, n_bins + 1)
rows = []
for lo, hi in zip(bins[:-1], bins[1:]):
mask = (confidences > lo) & (confidences <= hi)
if mask.sum():
rows.append((round(confidences[mask].mean(), 3),
round(correct[mask].mean(), 3),
int(mask.sum())))
return rowsA typical reliability table for an aligned model on an open-ended factual task looks discouraging: [(0.72, 0.61,140), (0.88, 0.70,410), (0.97, 0.82,380)]. Read the last row, the model says 0.97 and is right 0.82 of the time. That 15-point gap at the top of the confidence range is where your confident hallucinations live, and it is exactly the range a naive "answer if confidence > 0.9" threshold trusts most. ECE collapses this into a single number you can track in CI and watch for regression when you change models or prompts.
Recalibration: cheap fixes that genuinely help
A miscalibrated model is not a dead end, because calibration can be repaired post hoc without retraining. The cheapest and most effective is temperature scaling (in the calibration sense, distinct from decoding temperature) from Guo et al.: fit a single scalar that divides the logits before the softmax, chosen on a held-out set to minimize calibration error. It cannot change which answer is most likely (so it does not change accuracy), but it can stretch or compress the confidence distribution to match observed accuracy.
from scipy.optimize import minimize_scalar
import numpy as np
def fit_temperature(logits, labels):
"""Fit one scalar T to minimize NLL; T>1 softens overconfidence."""
logits = np.asarray(logits) # shape (n, n_classes)
labels = np.asarray(labels) # int class index per row
def nll(T):
z = logits / T
z = z - z.max(axis=1, keepdims=True)
logp = z - np.log(np.exp(z).sum(axis=1, keepdims=True))
return -logp[np.arange(len(labels)), labels].mean()
res = minimize_scalar(nll, bounds=(0.05, 10.0), method="bounded")
return res.xFor systems without logit access, most hosted APIs in open-ended mode, recalibration shifts to the score you derive from sampling: self-consistency agreement rates, semantic-entropy buckets, or a trained verifier's probability. The recalibration target is the same: make the score you threshold on actually predict correctness. The lesson is that you almost never threshold on a model's raw stated confidence; you threshold on a calibrated score you built and measured.
A calibration warning box
Because this chapter is the one teams most want to over-trust, a boxed warning, stated plainly:
**Do not treat a model's confidence as a probability until you have measured its calibration on your task. ** Confidence numbers, token probabilities, P(True), verbalized percentages, are features, not ground truth. They are degraded by alignment tuning, confounded by surface form, and miscalibrated out of distribution. A confidence threshold built on an unmeasured score is a hallucination gate that leaks at exactly the high-confidence end you trust most. Measure ECE on a golden set, recalibrate, re-measure on a slice that matches production, and re-check whenever the model or prompt changes. An uncalibrated confidence is worse than no confidence, because it feels like a safeguard.
From confidence to abstention
Calibration is not an end in itself; it exists to enable the M-step. Once you have a measured, recalibrated confidence score, whether from logits, semantic entropy, or a trained verifier, you can set a threshold appropriate to the stakes: high-stakes domains demand high confidence to answer and abstain readily; low-stakes tools can answer at lower confidence and accept more noise. The threshold is a product decision informed by the cost matrix (the cost of a wrong answer versus the cost of an unhelpful abstention), and calibration is what makes that decision honest, it ties the threshold to a real probability of being wrong. Chapter 13 builds the abstention machinery on top of exactly this. For now, the load-bearing idea is the bridge: a model has some self-knowledge, that self-knowledge is fragile and must be measured, and a measured, recalibrated confidence is the input that lets a system choose between answering and admitting it does not know.
Chapter summary
Calibration, the property that claims made with confidence p are correct a fraction p of the time, is the bridge between a model producing a claim and a system trusting it, because CLAIM's mitigation step needs a threshold and a threshold is only safe on a calibrated score. The encouraging result is that models mostly know what they know: scale improves self-evaluation (P(True)) and multiple-choice probabilities are often reasonably calibrated. The discouraging results constrain the optimism: alignment tuning degrades probability calibration even as it improves helpfulness; verbalized confidence is an unreliable, round-number-prone feature out of the box; and naive token-probability confidence conflates uncertainty about wording with uncertainty about facts, which semantic uncertainty fixes by measuring entropy over meanings. Measure calibration on your own system with reliability diagrams and ECE, watch the high-confidence end where confident hallucinations concentrate, and recalibrate cheaply with temperature scaling (or, without logits, by calibrating a sampling-derived score). The boxed rule: never threshold on an unmeasured confidence. Calibration's purpose is abstention, a measured, recalibrated confidence is what lets a system honestly choose between answering and saying "I don't know, " scaled to stakes. The next movement turns from the model to the system around it, by way of fluency as the disguise that lets miscalibrated confidence reach users, and then to the failure teams most often misdiagnose: when retrieval fails before generation begins.