The Confident Wrong Answer
> **Working claim: ** "The model hallucinated" is not a diagnosis.

The confident wrong answer is not one bug; it is the visible end of a chain that usually failed before the final sentence appeared.
Key Takeaways
- A wrong answer can contain a real case, a plausible citation, and an invented holding at the same time.
- The useful postmortem separates query transformation, retrieval, synthesis, attribution, and verification.
- Citation laundering is worse than a fake source because the source exists but does not support the claim.
- The evidence-binding chain is the chapter artifact: claim to span to citation to verification.
Read this with the opening litigation failure, the working taxonomy, and measuring hallucination.
**Working claim: ** "The model hallucinated" is not a diagnosis. A single fluent, wrong sentence is almost always the end of a chain of distinct, nameable failures, query handling, retrieval, synthesis, attribution, and the missing verification that should have caught it. Until you trace the chain and localize the fault, every fix is a guess.
One sentence, five failures
Return to the litigation assistant from the introduction and slow the failure down to single frames. The associate asked whether any court in the circuit had held that a force-majeure clause covers a government-ordered shutdown. The system produced a sentence of roughly this shape:
In Harbor Freight Logistics v. Coastal Mutual*, 412 F.3d 884 (4th Cir. 2019), the court held that a force-majeure clause encompassed losses arising from a government-mandated closure. *
Every visible property of that sentence is correct except the one that matters. The case is real. The citation format is impeccable. The reporter volume and the court are plausible and, let us say, even accurate. The holding, the actual proposition the sentence asserts, is invented. The opinion in Harbor Freight said no such thing.
If you stop at "the model hallucinated, " you have one fact: the output was wrong. If you trace the sentence backward through the system, you get five facts, and each one points at a different fix.
**Failure one: query transformation narrowed the question. ** The user's query contained the load-bearing phrase government-ordered shutdown. The rewrite step, a small model turning natural language into a database query, produced a search for force majeure clause coverage, dropping the specific trigger. This is not a model-fabrication failure at all. It is an information-loss failure upstream of the language model, and no amount of "be truthful" prompting downstream can recover a constraint that was discarded before retrieval ran.
**Failure two: retrieval returned related-but-insufficient material. ** The narrowed query pulled back genuine force-majeure opinions. They were relevant in the loose sense, same doctrine, and irrelevant in the strict sense, none addressed government-ordered closures. The retrieval system did its job against the query it was given. It returned plausible neighbors of the right answer. Plausible neighbors are the most dangerous possible input to a fluent model, because they make a confident synthesis feel grounded.
**Failure three: the model synthesized past the evidence. ** Handed a question and a stack of cases that almost but did not answer it, the model generated the continuation that best fit the pattern of the prompt. A legal-research prompt is supposed to end in a holding, so the model produced a holding. It is shaped exactly like the holdings in its training data. It is the kind of sentence that would answer the question, which is a different thing from the sentence the cited case actually contains. This is unsupported synthesis, the model inferring beyond what the source supports, and it is the failure mode that retrieval, by itself, cannot fix.
**Failure four: attribution was decorative, not bound. ** The system attached the synthesized holding to the most prominent retrieved case and formatted a citation. Formatting a citation is a text-shaping task; the model is excellent at text-shaping. At no point did anything check that the *text of the cited opinion entailed the parenthetical. * The citation was generated alongside the claim, not derived from the evidence. This is citation laundering: a real source attached to a claim it does not support, which is in some ways worse than a fabricated citation, because the real source survives a spot-check of "does this case exist?"
**Failure five: nothing verified entailment. ** There was no evaluation, online or offline, that asked the only question that mattered: does the cited text support the asserted holding? The pipeline checked citation format. It did not check citation truth. The failure was allowed to reach a partner's desk because the system had no station whose job was to catch it.
Five failures, five fixes, and only one of them, failure three, is what people usually mean by "hallucination." The other four are query handling, retrieval relevance, attribution binding, and missing evaluation. A temperature change touches none of them.
Hallucination is a category, not a bug
The research literature reached this conclusion before the field's casual vocabulary did. The Survey of Hallucination in Natural Language Generation, written for tasks like summarization, dialogue, and data-to-text generation, draws the distinction this book leans on throughout: intrinsic hallucination, where the output contradicts the provided source, versus extrinsic hallucination, where the output adds content the source neither supports nor contradicts. These are different bugs with different detectors. An intrinsic error can be caught by checking the output against the source for contradiction. An extrinsic error survives that check, there is no contradiction to find, and requires asking the harder question: is this claim supported by anything we were given?
The later Survey on Hallucination in Large Language Models extends the taxonomy to open-ended generation, where there is often no single "source" to contradict, and splits hallucination into factuality hallucination (the claim conflicts with real-world facts) and faithfulness hallucination (the output conflicts with the user's instruction or the provided context). The two require different evaluation entirely: factuality needs a world model or an external knowledge source to check against; faithfulness needs only the input and the output. A system can be perfectly faithful to a context that is itself wrong, and perfectly factual while ignoring the instruction it was given. Conflating them is how teams "fix" the wrong axis.
TruthfulQA added a third, uncomfortable dimension: some falsehoods are learned. The benchmark assembles questions where common human misconceptions are well represented in text, and found that larger models could be less truthful on these, because they more faithfully imitate the popular-but-wrong answer. This is a crucial early warning against the "bigger model" reflex: scale improves fluency and broad capability, and on imitative-falsehood questions can make the model a more confident parrot of a common error.
A first taxonomy
We build the full failure taxonomy in Chapter 2, but the chain above already exposes the major families. It helps to see them as a table, because the value of the taxonomy is operational: each row has a different detector and a different mitigation.
| Failure family | What it is | Intrinsic / extrinsic / factual | First-line detector |
|---|---|---|---|
| Fabricated entity | A person, product, API, or case that does not exist | Extrinsic / factual | Existence check against a registry or source |
| Fabricated citation | A reference that does not exist | Extrinsic / factual | Resolve the citation against the source store |
| Wrong attribution | A real source attached to a claim it does not support | Extrinsic | Entailment check: source span ⊨ claim |
| Unsupported synthesis | A claim inferred beyond the provided evidence | Extrinsic | Claim-to-evidence coverage check |
| Contradicted answer | Output conflicts with the provided source | Intrinsic | Contradiction / NLI check vs. context |
| Stale fact | A claim that was true once and is not now | Factual | Currency check against dated source |
| Invented tool result | The system narrates an action or result that did not occur | Faithfulness | Compare claim to tool log / action record |
| Misplaced certainty | A guess delivered in the register of a fact | Calibration | Confidence vs. evidence-coverage gate |
The litigation failure touches four of these rows: the narrowed query produced an information gap, retrieval returned related-but-insufficient material, the model committed unsupported synthesis, and it expressed the result with misplaced certainty while laundering it through a real citation (wrong attribution). No single row is "the" bug. The output is the superposition of several.
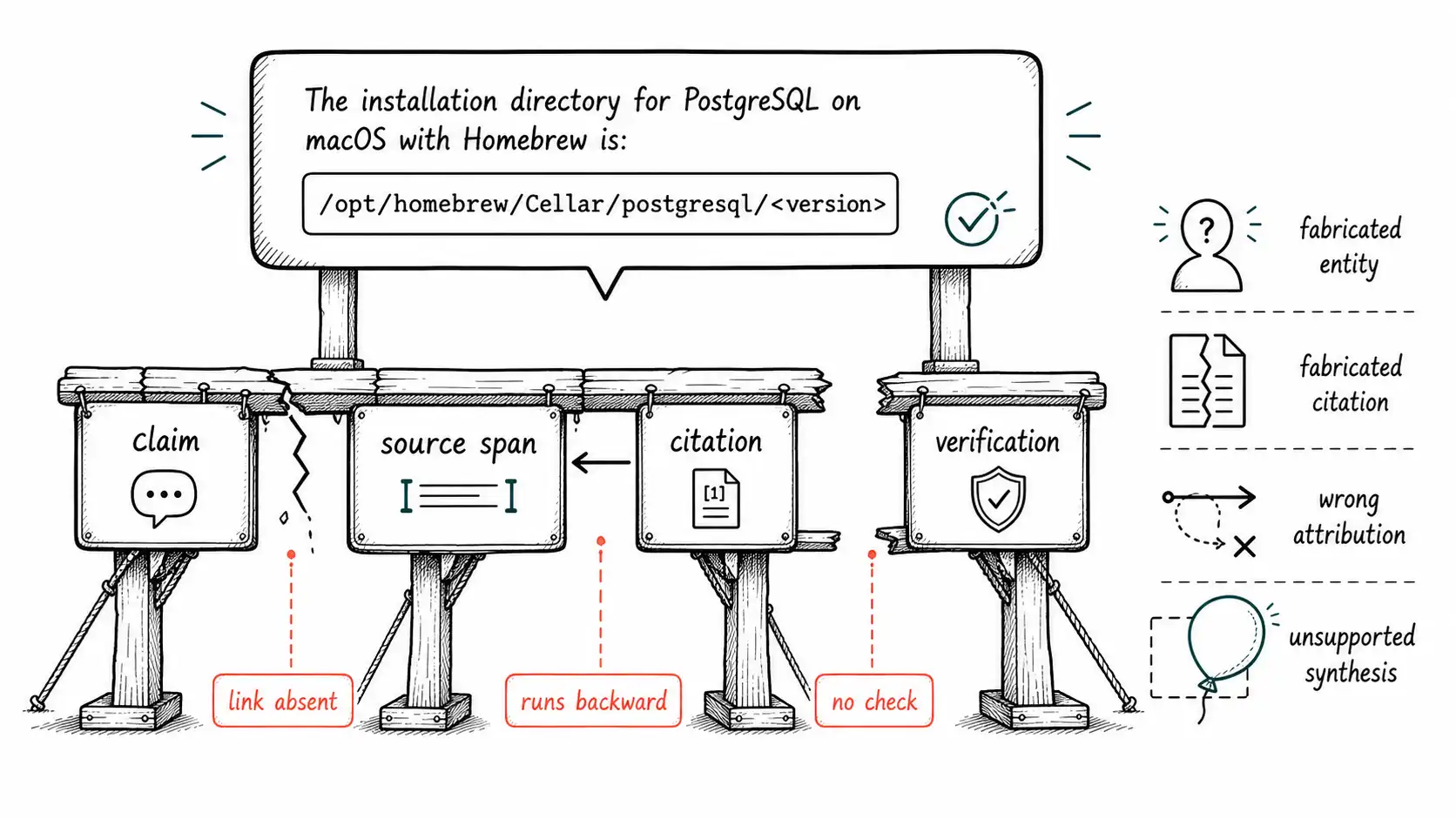
The evidence-binding chain
Underneath the taxonomy is a single structural idea that the rest of the book returns to constantly. Every factual claim a system emits should be traceable along a chain:
claim → source span → citation → verificationRead left to right, this is what a grounded answer looks like: the system makes a claim, that claim is bound to a specific span of a specific source, the citation the user sees points at that span, and a verification step has confirmed the span actually supports the claim. Read where the litigation system broke, and you can see the chain snap at each joint:
- claim → source span never connected. The holding was synthesized; no span supported it. The link was absent.
- source span → citation was inverted. The citation was generated from the claim, not the span. The link ran backward.
- citation → verification was missing. Nothing closed the loop.
A useful way to think about this: the citation is supposed to be a consequence of the evidence binding, not a cosmetic sibling of the claim. In a sound system, you cannot produce the citation without first producing the span that justifies it. In the litigation system, and in most deployed systems today, the citation is a free-floating string the model writes because the format demands one. That inversion is the difference between a citation that is proof and a citation that is decoration, and Chapter 7 is devoted entirely to it.
Why the chain matters more than the model
There is a comforting story in which hallucination is a property of the model, a defect that the next release will reduce, that a better base model will mostly cure. There is truth in it: models do improve, and we will look at where scale and tuning genuinely help. But the litigation failure is mostly not in the model. The model did the most predictable thing in the world when handed a question and almost-relevant evidence: it produced the fluent continuation that fit the pattern. The failures that made that continuation dangerous were system failures, a lossy query rewrite, a retrieval layer that returned neighbors, an attribution step with no binding, and the absence of a verification station.
This reframing is the practical center of the book. If hallucination is a property of the model, your only lever is to wait for a better model. If hallucination is, mostly, the visible symptom of a system making unsupported claims, then you have many levers, and most of them are within your control: how you handle ambiguous queries, what you retrieve and whether it is sufficient, whether you bind claims to spans, whether you verify entailment, and, the lever the field most neglects, whether the system is allowed to say I don't know when the chain cannot be completed. Retrieval-augmented generation gave the field a way to put evidence in front of the model; the RAGAS line of work gave it a way to measure whether the answer actually used that evidence faithfully. Neither is a cure on its own. Both are stations in a chain that you, not the model vendor, are responsible for assembling.
A test you can run on your own failure
Before the next chapter formalizes the taxonomy, here is the practice this chapter is really teaching, expressed as a routine. The next time your system produces a confident wrong answer, do not file it as "hallucination." Trace it.
from dataclasses import dataclass, field
@dataclass
class FailureTrace:
"""A localized post-mortem of one wrong answer. One row per station."""
user_query: str
rewritten_query: str | None # did query handling change the question?
retrieved_ids: list[str] # what came back?
gold_was_retrievable: bool # did the right evidence exist and get found?
claim: str # the atomic claim that was wrong
supporting_span: str | None # is there ANY span that supports it?
citation_shown: str | None # what citation did the user see?
citation_supports_claim: bool # does that citation actually entail the claim?
verification_ran: bool # was there a check that should have caught this?
notes: list[str] = field(default_factory=list)
def localize(trace: FailureTrace) -> str:
"""Assign the failure to a station so the fix is not a guess."""
if trace.rewritten_query and trace.rewritten_query!= trace.user_query:
if "dropped" in " ".join(trace.notes):
return "QUERY_TRANSFORMATION: constraint lost before retrieval"
if not trace.gold_was_retrievable:
return "RETRIEVAL_MISS: right evidence never reached the model"
if trace.supporting_span is None:
return "UNSUPPORTED_SYNTHESIS: no span supports the claim"
if trace.citation_shown and not trace.citation_supports_claim:
return "CITATION_LAUNDERING: real source, wrong claim"
if not trace.verification_ran:
return "MISSING_VERIFICATION: no station checked entailment"
return "REVIEW: failure not localized; add instrumentation"The point of localize is not the code, it is the discipline. Each branch is a different chapter of this book and a different repair. Running this on ten real failures will teach a team more about its own hallucination profile than any benchmark, because it forces the question the word "hallucination" lets you avoid: which station failed?
Chapter summary
A single confident wrong answer is rarely a single failure. The litigation assistant's invented holding was the visible end of a five-link chain: a query rewrite that dropped the load-bearing constraint, retrieval that returned related-but-insufficient material, a model that synthesized past the evidence, an attribution step that laundered the claim through a real citation, and the absence of any verification that checked entailment. Only one of those is "hallucination" in the usual sense. The research literature already distinguishes intrinsic from extrinsic errors, factuality from faithfulness, and learned falsehoods (TruthfulQA) from invented ones, distinctions that matter because each has a different detector and a different fix. Underneath the taxonomy lies one structural idea: every factual claim should trace a chain from claim to source span to citation to verification, and a citation should be a consequence of the binding, not a cosmetic sibling of the claim. The reframing that follows is the heart of the book: hallucination is mostly the symptom of a system making unsupported claims, which means most of the levers are yours, not the model vendor's. If you need context for how the litigation failure that opens Introduction: The Holding That Never Was maps to the failure chain above, that chapter is the right reset. The next chapter turns the families sketched here into a working taxonomy of hallucination precise enough to drive detection and mitigation.