Measuring Unsupported Claims
> **Working claim: ** You cannot manage a hallucination rate you do not measure, and you cannot measure it at the answer level.

Measuring hallucination means measuring unsupported claims, not asking whether a whole answer feels plausible.
Key Takeaways
- Answer-level hallucination rate hides mixtures; the useful metric is claim-level support.
- The eval dataset needs atomic claims, gold spans, source versions, answerability labels, and domain slices.
- Annotation must judge support, not plausibility, because plausible unsupported claims are the failure.
- Report confidence intervals, worst slices, abstention pairs, and CI gates instead of one average score.
Read this with AI abstention, production operations, and measuring hallucination.
**Working claim: ** You cannot manage a hallucination rate you do not measure, and you cannot measure it at the answer level. The unit of measurement is the claim, the unit of ground truth is a human label tied to a span, and the metrics that matter, faithfulness, citation precision, abstention quality, are claim-level rates with confidence intervals, sliced by query type. A team that reports "accuracy" on whole answers is flying blind on the exact failures this book is about.
What you are actually trying to measure
Before any harness, fix the target. The quantity to measure is not "is the answer correct", too coarse, hides the supported/unsupported mix, and conflates faithfulness with factuality. The quantities that drive the system are claim-level rates:
- **Faithfulness: ** fraction of generated claims entailed by the provided/current evidence (RAGAS). The core hallucination metric for grounded systems.
- **Factual precision: ** fraction of generated atomic facts supported by a reliable source (FActScore). The core metric where there is no single provided context. The TruthfulQA benchmark is the canonical adversarial probe for this axis, testing specifically on questions where the model's training distribution pushes toward false confident answers.
- **Citation precision / recall: ** of cited claims, the fraction actually entailed; of claims requiring citation, the fraction that carry one (Chapter 7).
- **Abstention quality: ** on the unanswerable slice, the fraction correctly abstained; on the answerable slice, the fraction not over-refused (Chapter 13).
- Answer correctness, does the answer match the gold answer (where one exists), kept, but understood as a downstream metric whose movement you explain via the claim-level ones.
The relationship matters: faithfulness and answer-correctness can diverge, and the divergence is diagnostic. A faithful answer that is wrong means the corpus is wrong (an Authority failure). A correct answer that is unfaithful means the model got lucky from its prior despite weak retrieval, fragile, and it will not hold. Measuring both, per claim, is what lets you tell these apart.
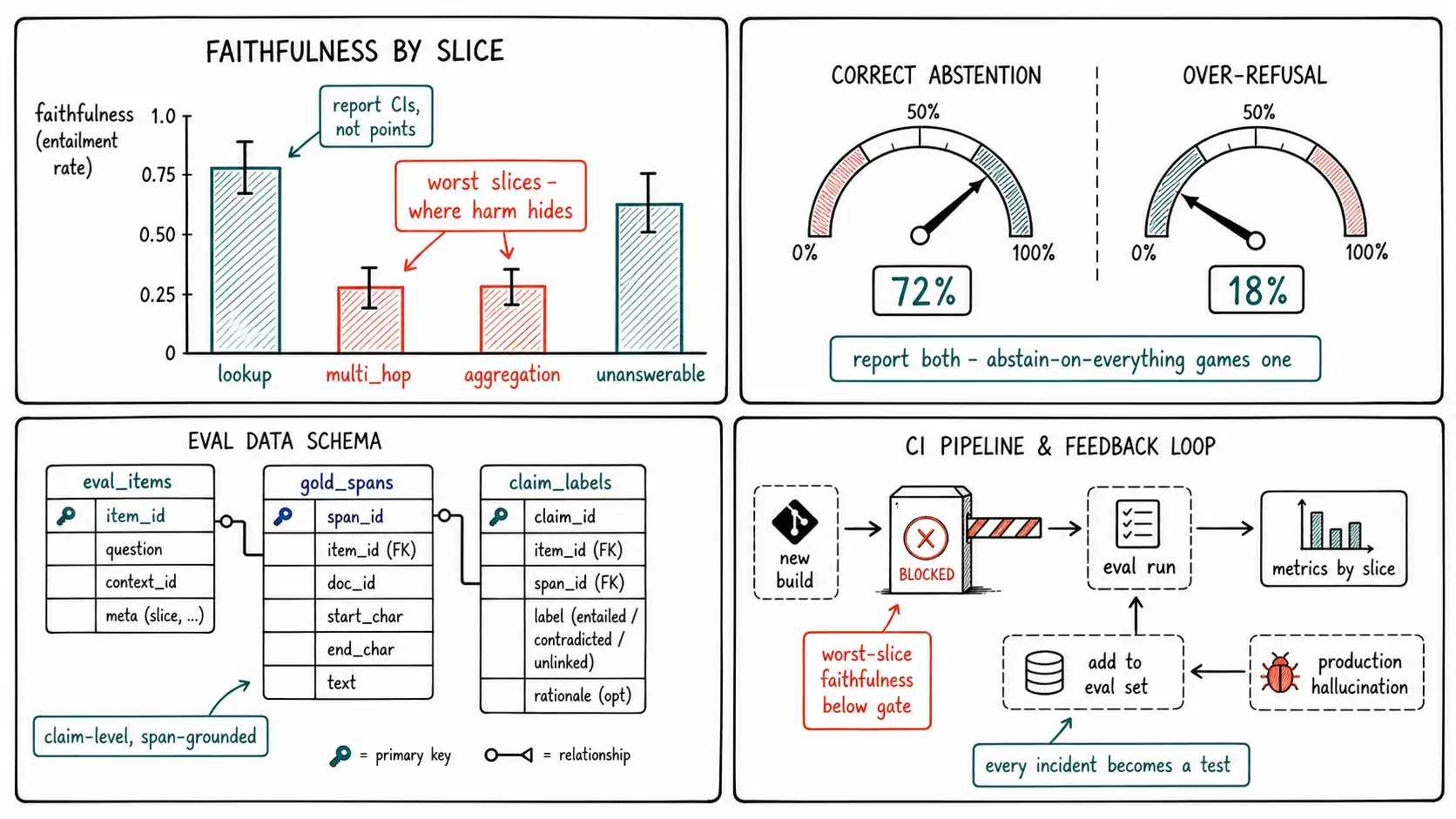
The evaluation dataset schema
The golden set is the asset the whole measurement program rests on, and its schema must support claim-level, span-grounded judgment, not just question/answer pairs. A question/answer golden set cannot measure faithfulness, because faithfulness is about which spans support which claims, and that information has to be in the data.
CREATE TABLE eval_items (
item_id TEXT PRIMARY KEY,
query TEXT NOT NULL,
query_type TEXT NOT NULL, -- 'lookup','multi_hop','aggregation','unanswerable','ambiguous'
answerable BOOLEAN NOT NULL, -- false items test ABSTENTION
stakes TEXT NOT NULL, -- 'low','medium','high'
gold_answer TEXT, -- nullable; null for unanswerable
source_corpus_ver TEXT NOT NULL -- which corpus snapshot; for drift tracking
);
-- the spans that SHOULD support a correct answer; enables context-recall scoring
CREATE TABLE gold_spans (
item_id TEXT REFERENCES eval_items(item_id),
source_id TEXT NOT NULL,
span_text TEXT NOT NULL,
required BOOLEAN NOT NULL -- is this span necessary for a complete answer?
);
-- human (or verifier) judgments at the CLAIM level for each generated answer
CREATE TABLE claim_labels (
run_id TEXT NOT NULL,
item_id TEXT REFERENCES eval_items(item_id),
claim_text TEXT NOT NULL,
claim_type TEXT NOT NULL,
verdict TEXT NOT NULL, -- 'supported','unlinked','overreach','contradicted','stale'
supporting_span TEXT, -- the span the labeler used, if any
source_id TEXT,
labeler TEXT NOT NULL, -- human id or 'verifier:v3'
labeled_at TIMESTAMP NOT NULL
);Two design choices carry weight. First, answerable = false items are first-class, a hallucination eval that only tests questions the corpus can answer never measures abstention, and abstention is half the system. You deliberately include questions whose answers are not in the corpus, and the correct behavior is to abstain. Second, source_corpus_ver ties every item to a corpus snapshot, so that when the corpus changes, you can tell whether a metric moved because the system changed or because the evidence did (the drift problem, Chapter 15).
The annotation guide
Human labels are the ground truth, and humans disagree unless the guide is precise. The annotation guide is itself an engineering artifact, and its central instruction is the one labelers resist: *judge support, not plausibility. * A claim that is true in the world but not supported by the provided evidence is unlinked for a faithfulness label, even though the labeler "knows" it is true. Separating these is the whole point.
**Annotation guide (core rules). **
- Work claim by claim, on the atomic claims provided. Do not judge the answer as a whole.
- For each claim, find a span in the provided sources that entails it, that, if true, makes the claim true. Topic overlap is not entailment.
- Label
supportedonly if you found such a span. Paste the span.- Label
contradictedif a span asserts the opposite.- Label
unlinkedif no span supports or contradicts it, even if you personally believe it is true. This is the extrinsic-hallucination label.- Label
overreachif a span supports part of the claim but the claim asserts more.- Label
staleif a span supports it but the span is from a superseded/expired source.- For action claims, the "span" is the action-log entry; no entry means
unlinked.- When unsure between
unlinkedandoverreach, chooseoverreachonly if there is a real partial span; otherwiseunlinked.
You measure inter-annotator agreement (Cohen's or Fleiss' kappa) on a shared subset, and a low kappa means the guide is ambiguous, not that the labelers are bad, fix the guide. This labeled data then becomes the calibration set for your automated verifier (Chapter 10): you measure the verifier's agreement with human labels and only trust the verifier where it agrees.
The metrics, in SQL
With claim labels in a table, the metrics are queries, which is the point, because it means anyone can compute them, they are reproducible, and they slice trivially. Faithfulness as a per-run, per-slice rate:
-- Faithfulness by query_type and stakes for one run
SELECT e.query_type, e.stakes,
COUNT(*) AS total_claims,
SUM(CASE WHEN c.verdict = 'supported' THEN 1 END) AS supported,
ROUND(AVG(CASE WHEN c.verdict = 'supported' THEN 1.0 ELSE 0 END), 3)
AS faithfulness
FROM claim_labels c
JOIN eval_items e ON e.item_id = c.item_id
WHERE c.run_id =:run_id
GROUP BY e.query_type, e.stakes
ORDER BY faithfulness ASC; -- worst slices firstThe ORDER BY faithfulness ASC is deliberate: the average hides the failure. A system at 0.94 overall faithfulness can be at 0.71 on the multi_hop slice and 0.55 on aggregation, and those slices are where the harm concentrates. Slice metrics are not optional decoration; they are how you find the failure the average buried. Abstention quality is a query over the answerable flag:
-- Abstention: correct refusal on unanswerable; over-refusal on answerable
SELECT
ROUND(AVG(CASE WHEN NOT e.answerable AND r.action = 'abstain' THEN 1.0
WHEN NOT e.answerable THEN 0 END), 3) AS correct_abstention_rate,
ROUND(AVG(CASE WHEN e.answerable AND r.action = 'abstain' THEN 1.0
WHEN e.answerable THEN 0 END), 3) AS over_refusal_rate
FROM run_actions r
JOIN eval_items e ON e.item_id = r.item_id
WHERE r.run_id =:run_id;Reporting these two together prevents the classic gaming: a system that abstains on everything scores perfectly on correct-abstention and terribly on over-refusal. The pair is the honest picture.
Confidence intervals and regression gates
Two rigor requirements that separate a real eval from a vanity dashboard. First, **report intervals, not points. ** A faithfulness of 0.91 on a 200-claim slice has a meaningful confidence interval; a 3-point movement between runs may be noise. Bootstrap the metric over items (not claims, which are correlated within an item) and report the interval, so you do not chase noise or miss a real regression.
import numpy as np
def bootstrap_faithfulness(per_item_rates, n=2000, alpha=0.05):
"""CI over items -- items are independent; claims within an item are not."""
rates = np.asarray(per_item_rates)
boot = [np.mean(np.random.choice(rates, len(rates), replace=True)) for _ in range(n)]
return (round(np.mean(rates), 3),
round(np.percentile(boot, 100*alpha/2), 3),
round(np.percentile(boot, 100*(1-alpha/2)), 3))Second, **wire the eval into CI as a gate. ** Every production hallucination becomes a new eval item (OpenAI evals is built for exactly this loop), so the golden set grows toward your real failure distribution. A model, prompt, or retrieval change that drops worst-slice faithfulness below its gate, or pushes over-refusal above its gate, fails the build. This is what turns measurement from a report into a control, the same posture the NIST AI RMF prescribes for ongoing measurement and management of AI risk: measure continuously, set thresholds tied to impact, and treat a threshold breach as an event, not a footnote.
Reference-free evaluation, and its place
Not every production answer has a gold label, so part of your measurement is reference-free: run the automated verifier (Chapter 10) and the consistency/judge instruments (Chapter 11) on unlabeled production traffic to estimate faithfulness at scale. This is essential for coverage but must be kept in its place: a reference-free estimate is a model's estimate, calibrated against the human-labeled golden set, with its own error bars. The healthy arrangement is a two-tier program, a small, expensive, human-labeled golden set that is the ground truth and the calibration anchor, and a large, cheap, automated estimate over production traffic that is calibrated to the golden set and trusted only as far as that calibration holds. Reporting an automated faithfulness number without its agreement-with-humans number is reporting a measurement without its instrument's accuracy.
Chapter summary
You cannot manage an unmeasured hallucination rate, and you cannot measure it at the answer level, the unit is the claim, the ground truth is a human label tied to a span, and the metrics that drive the system are claim-level rates: faithfulness (RAGAS), factual precision (FActScore), citation precision/recall, and abstention quality, with answer-correctness kept as a downstream metric whose movement the claim-level rates explain (faithful-but-wrong indicts the corpus; correct-but-unfaithful is fragile luck). The golden-set schema must be claim-level and span-grounded, must include answerable = false items so abstention is measured, and must tie items to a corpus version so you can separate system drift from evidence drift. The annotation guide's core rule, judge support, not plausibility, is what makes unlinked (extrinsic hallucination) labelable, and inter-annotator kappa diagnoses guide ambiguity. Metrics are SQL queries so they are reproducible and sliceable, ordered worst-slice-first because the average buries the failure, and abstention metrics are reported in pairs so abstain-on-everything cannot game them. Rigor requires confidence intervals bootstrapped over items, and the eval wired into CI as a gate where every production hallucination becomes a new test (the OpenAI-evals/NIST-RMF loop). Reference-free estimation extends coverage to unlabeled traffic but is a model's estimate calibrated to the human golden set, trusted only as far as that calibration holds. The prior chapter, Teaching a System to Say "I Don't Know", established the abstention policy that feeds the abstention quality metric here. The final chapter of this movement turns the measurement program into a running production system: monitoring, drift, feedback, and the incident runbook.