Interventions and Their Limits
> **Working claim: ** Every popular hallucination cure works on *some* failure mode and is useless or harmful on others.

Hallucination interventions work only when they target the specific failure mode in front of the system.
Key Takeaways
- No popular cure covers every failure mode; each intervention has a target and a boundary.
- RAG, structured outputs, lower temperature, self-consistency, judges, and fine-tuning solve different problems.
- Claim extraction, source-span verification, and abstention are the interventions that directly act on unsupported claims.
- Product design is part of mitigation because user-visible uncertainty, source display, and escalation shape the harm.
Read this with self-consistency and judge limits, saying I do not know, and AI observability and monitoring.
**Working claim: ** Every popular hallucination cure works on some failure mode and is useless or harmful on others. The skill is not knowing the interventions, everyone knows them, but matching each to the failure it actually addresses, and refusing to apply it to the failure it does not. An intervention applied to the wrong failure mode does not just waste effort; it manufactures false confidence that the problem is handled.
The mitigation matrix
The whole chapter hangs on one table, because the chapter's argument is the table: interventions are not good or bad, they are matched or mismatched to failure modes. Read down a column to see which intervention helps a given failure; read across a row to see what a given intervention can and cannot do.
| Intervention → / Failure ↓ | Better prompt / "be truthful" | Lower temperature | RAG | Hybrid search + rerank | Source-aware prompt + forced citation | Structured outputs | Tool use | Fine-tune / preference tune | Verification loop | Abstention | Human review |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Missing knowledge | ✗ | ✗ | ✓✓ | ✓ | ○ | ✗ | ✓ | ○ | ○ | ✓✓ | ○ |
| Stale knowledge | ✗ | ✗ | ✓✓ (current corpus) | ✓ | ○ | ✗ | ✓ | ✗ | ○ | ✓ | ○ |
| Learned falsehood | ○ | ✗ | ✓ (authority) | ✓ | ○ | ✗ | ○ | ○ | ✓ | ○ | ✓✓ |
| Retrieval miss | ✗ | ✗ | - | ✓✓ | ✗ | ✗ | ○ | ✗ | ✓ (detects) | ○ | ○ |
| Retrieval noise | ✗ | ✗ | - | ✓✓ | ○ | ✗ | ✗ | ✗ | ✓ (detects) | ○ | ○ |
| Ignored evidence | ○ | ✗ | - | ○ | ✓✓ | ○ | ✗ | ○ | ✓ | ○ | ○ |
| Unsupported synthesis | ○ | ✗ | ✗ | ✗ | ○ | ○ | ✗ | ○ | ✓✓ | ✓ | ✓ |
| Citation laundering | ✗ | ✗ | ✗ | ✗ | ○ | ✓ (bind) | ✗ | ✗ | ✓✓ | ○ | ✓ |
| Number/date drift | ○ | ✗ | ○ | ○ | ○ | ✓ | ✓ (compute) | ✗ | ✓✓ | ○ | ○ |
| Dropped qualifier | ○ | ✗ | ✗ | ✗ | ○ | ○ | ✗ | ✓ | ✓✓ | ○ | ✓ |
| Invented tool result | ✗ | ✗ | ✗ | ✗ | ✗ | ✓✓ (status) | - | ✗ | ✓✓ (log) | ○ | ✓ |
| Ambiguous query | ✓ (ask) | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ○ | ○ | ✓ | ○ |
| Misplaced certainty | ○ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ (calibration) | ✓ | ✓✓ | ✓ |
Legend: ✓✓ strong fit, ✓ helps, ○ marginal/conditional, ✗ does not address, not applicable.
Three patterns jump out, and they are the chapter's thesis. First, the most popular interventions, better prompt and lower temperature, are almost entirely ✗ and ○. They are the reflexive cures, and the matrix shows they address almost nothing directly. Second, verification loop and abstention are the densest columns of ✓✓, because they are the interventions that act on the claim rather than the generation, they catch or refuse unsupported output regardless of why it was unsupported. Third, several failures (citation laundering, invented tool result, number drift) are only truly addressed by structural interventions, binding, status fields, computation, not by anything you can prompt. The rest of the chapter walks the interventions that need the most honest treatment.
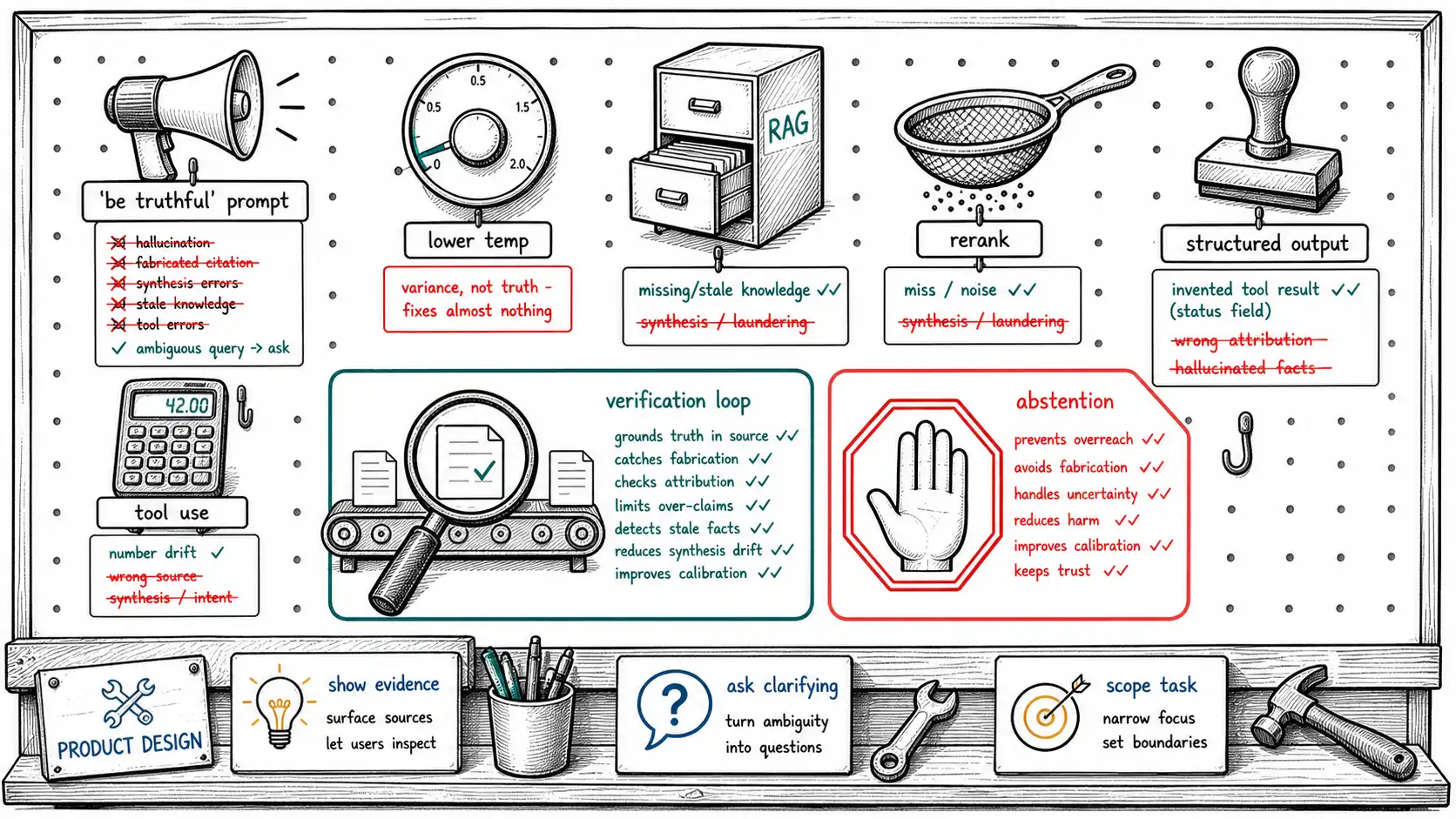
The interventions that mostly disappoint
"Be truthful" prompting is ✗ or ○ across the board because, per Chapter 4, it restyles the output without grounding it. Its one genuine ✓ is on ambiguous queries, a prompt that instructs "if the question is ambiguous, ask a clarifying question" can convert a guess into a question, which is real value. But as a hallucination cure it is the weakest intervention that feels like the strongest, and its danger is the false confidence it creates: a team adds it, the demo looks careful, and the structural work goes undone.
Lower temperature is ✗ almost everywhere because, per Chapter 4, it controls variance, not grounding. It does not even get the ambiguous-query ✓, because a low-temperature model answers the ambiguous question more consistently, not more wisely. Its legitimate use is reducing noise on tasks where the greedy answer is correct, and as the engine of the self-consistency detector, which needs the opposite (higher temperature) to expose uncertainty. As a mitigation, it is near-inert.
RAG is ✓✓ exactly where the failure is missing or stale knowledge and ✗ where the failure is synthesis or laundering, the asymmetry Chapter 6 established. The matrix row for unsupported synthesis shows RAG as ✗: putting more evidence in front of a model that is going to over-read it does not stop the over-reading. This is the single most important calibration of expectations in the book: RAG is a knowledge intervention, not a grounding-discipline intervention.
The interventions that work: and their seams
Source-aware prompting with forced citation earns its ✓✓ against ignored evidence: instructing the model to answer only from the provided context and to attach a citation to every claim genuinely raises the rate at which it uses the retrieved passage instead of its prior. The seam is that "forced citation" without binding (Chapter 7) produces citation laundering, the model dutifully attaches citations it did not derive. So this intervention is ✓✓ on ignored evidence and only ○ on laundering, because it creates the conditions for laundering unless paired with verification.
Structured outputs (OpenAI structured outputs) earn ✓✓ against invented tool results (the status field the model cannot manufacture, Chapter 9) and ✓ against citation laundering and number drift (a schema that demands a source_span and a value field forces the model to populate them from somewhere checkable). The seam: a schema constrains the shape of the output, not its truth. A model can put a fabricated value in a well-typed revenue: float field. Structured outputs make verification possible and cheap, you have typed fields to check, but they are not verification themselves.
Tool use earns ✓ to ✓✓ for the failures where a tool can compute or look up the truth: a calculator for arithmetic (eliminating number drift on computed values), a database query for current state (eliminating staleness), a code interpreter for data analysis. The principle is to move the claim out of the model's generative path and into a deterministic computation. The seam is the tool boundary from Chapter 9, the model can still misreport the tool's result, which is why tool use pairs with the action log.
Fine-tuning and preference tuning (InstructGPT) earn scattered ✓/○: they genuinely improve calibration-adjacent behaviors (appropriate hedging, refusal, qualifier preservation) and can teach a domain model to abstain rather than guess in its specialty. The seams are real and Chapter 5's: preference tuning can degrade probability calibration, induce sycophancy, and cause over-refusal; it optimizes for what raters liked, not for truth. Fine-tuning is a distribution-shaping tool, not a fact-installation tool, it cannot teach the model facts it must instead retrieve, and a fine-tune that appears to reduce hallucination by making the model refuse more has traded one failure (fabrication) for another (unhelpfulness) that your eval must also measure.
The interventions that actually act on claims
Verification loops earn the densest ✓✓ column because they are the only interventions that operate on the output claim rather than the generation process (see RAGAS for the eval framework that measures how well a loop holds faithfulness on a real corpus). A verification loop runs the Chapter 10 pipeline on the draft answer, and on a failed check, revises (drop or hedge unsupported claims and regenerate), abstains, or escalates. Self-RAG folds a version of this into generation; an external loop bolts it on. Either way, the loop catches unsupported synthesis, laundering, number drift, and invented tool results regardless of why they occurred, because it checks the claim against evidence rather than trying to fix the model. Its cost is latency and spend (you generate, verify, possibly regenerate), which is why it is reserved for stakes that justify it. Its limit is the verifier's own reliability (Chapter 10's product-of-stages caveat), a verification loop is as good as its verifier, and a confident consistent falsehood can pass both.
def verified_answer(query, evidence, generator, verifier, stakes) -> dict:
"""Generate, verify, then revise/abstain/escalate. The verification loop."""
draft = generator.answer(query, evidence)
report = verifier.verify(draft, evidence) # Chapter 10 pipeline
if report["faithfulness"] >= threshold_for(stakes) and not report["contradictions"]:
return {"action": "ANSWER", "text": bind_citations(draft, report)}
unsupported = report["unsupported"]
if recoverable(unsupported) and stakes!= "high":
revised = generator.answer(query, evidence,
constraint=f"Omit unsupported: {unsupported}")
return {"action": "REVISE", "text": revised}
if stakes == "high":
return {"action": "ESCALATE", "report": report}
return {"action": "ABSTAIN", "reason": "insufficient evidence",
"missing": unsupported}Product design is an intervention
The interventions teams forget are not algorithmic at all. Showing the evidence, surfacing the cited spans next to the answer so the user can verify, converts the user into the final verification stage and is often higher-use than any model change, because it makes laundering visible. Asking clarifying questions on ambiguous queries (the ✓ that "be truthful" earns) prevents the guess at the source. Scoping the task, narrowing what the assistant will attempt, removes whole categories of failure by refusing to enter them. And setting user expectations (this tool drafts, it does not decide; verify before filing) reshapes the cost of a residual hallucination. The matrix is full of algorithmic interventions because they are codeable, but the cheapest reductions in realized harm often come from design choices that change what the system attempts and what the user does with the output.
The honest summary of limits
If the chapter has one takeaway beyond the matrix, it is this: *no intervention reduces hallucination in general, because hallucination is not one thing. * RAG cannot fix synthesis; prompting cannot fix missing knowledge; structured outputs cannot fix falsehood; fine-tuning cannot install facts. The interventions that come closest to general, verification loops and abstention, work precisely because they do not try to fix the cause and instead act on the claim, catching or refusing unsupported output whatever produced it. And even those have a floor: a confident, consistent, fluent falsehood with no available reference can pass a verification loop and survive an abstention threshold set on a miscalibrated score. The mature posture is to stack matched interventions, measure the residual rate, and bound the system's use to where that residual is acceptable, which is the subject of the production movement. The next chapter takes the single highest-use column of the matrix and builds it out: teaching a system to abstain.
Chapter summary
Every hallucination intervention is matched or mismatched to a failure mode, never universally good or bad, and the mitigation matrix is the chapter's argument. Three patterns dominate: the most popular cures ("be truthful, " lower temperature) address almost nothing directly and create false confidence; the densest ✓✓ columns are verification loops and abstention, because they act on the output claim rather than the generation process and so catch unsupported output regardless of cause; and several failures (citation laundering, invented tool results, number drift) yield only to structural interventions (binding, status fields, computation), not to prompting. RAG is a knowledge intervention (✓✓ on missing/stale knowledge, ✗ on synthesis and laundering), the most important expectation to calibrate. Source-aware prompting raises evidence use but creates laundering unless paired with binding; structured outputs make verification cheap but do not perform it; tool use moves claims into deterministic computation but inherits the tool boundary; fine-tuning shapes distribution and calibration but cannot install facts and can trade fabrication for over-refusal. Verification loops earn their density by checking the claim against evidence and then revising/abstaining/escalating, bounded only by the verifier's own reliability. The forgotten interventions are product design, show evidence, ask clarifying questions, scope the task, set expectations, often the cheapest reduction in realized harm. The honest floor: no intervention reduces hallucination in general; the mature posture stacks matched interventions, measures the residual, and bounds use accordingly. This chapter follows from Self-Consistency and the Limits of the Judge, which showed what happens when you ask the model to verify its own claims. The next chapter builds the highest-use column in full: abstention.