Playbooks by Domain
> **Working claim: ** The machinery is constant, CLAIM, the taxonomy, verification, abstention, monitoring, but the *settings* are not.

Hallucination playbooks keep the machinery constant while changing thresholds, detectors, and escalation rules by domain risk.
Key Takeaways
- CLAIM, verification, abstention, and monitoring stay constant; the settings change by domain.
- Legal, healthcare, and finance require tighter authority, citation, and escalation thresholds than low-stakes internal search.
- Support bots and meeting summarizers fail differently: one over-promises policy, the other invents decisions and action items.
- Workflow agents need the action log and permission boundary because the failure can change state, not just text.
Read this with production operations, the appendix checklist, and AI agent evals.
**Working claim: ** The machinery is constant, CLAIM, the taxonomy, verification, abstention, monitoring, but the settings are not. Each domain has a characteristic hallucination profile, a different evidence requirement, and a different cost of being wrong, and those determine the abstention threshold, the escalation rule, and how much verification you can afford. A playbook is the machinery instantiated against a domain's specific failure profile and stakes.
How to read a playbook
Each playbook below answers the same six questions, because those six are what differ across domains while the machinery stays the same: the characteristic hallucination types (which taxonomy rows dominate, per the Huang et al. survey), the evidence requirement (what a claim must be bound to), the retrieval and eval strategy (including RAGAS-style faithfulness scoring), the mitigation stack (which interventions from Chapter 12, in what order), the monitoring focus (which of the four rates matters most), and the escalation rule (when M defaults to a human). Think of them as pre-tuned configurations, not as new techniques. The skill the book has been building is reading a new domain into these six slots.
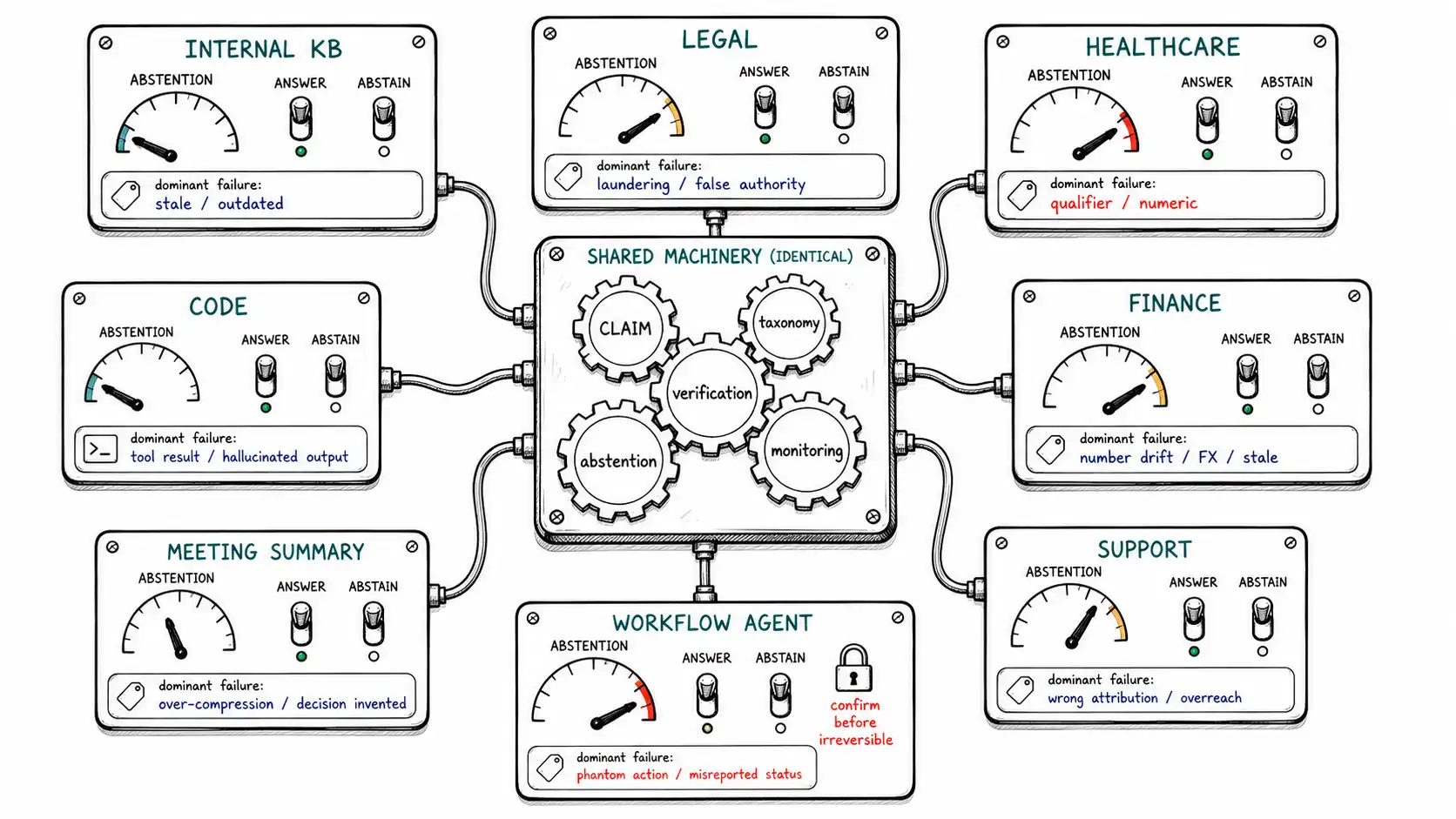
Internal knowledge assistant
The friendly base case, and the one most teams build first. An employee asks about policy, process, or product internals; the answer lives in a corpus of wikis, docs, and tickets.
- **Characteristic types: ** stale facts (internal docs rot fast), retrieval miss (jargon/vocabulary mismatch), unsupported synthesis across docs.
- **Evidence requirement: ** every claim bound to a current internal source span; show the span.
- **Retrieval/eval: ** hybrid retrieval (acronyms and codes need lexical); golden set heavy on
unanswerableitems (employees ask about things not documented); track context recall. - **Mitigation stack: ** RAG + rerank → source-aware prompt with shown evidence → verification loop (light, internal stakes) → abstain when uncovered.
- **Monitoring: ** abstention rate (a drop signals stale-doc over-answering); user-correction rate.
- **Escalation: ** low, route to the doc owner or "ask a human" link; the cost of a wrong internal answer is usually a corrected Slack message, so coverage can be high.
Legal research assistant
The book's opening failure, and a domain where the cost of a confident wrong answer is severe and the laundering risk is structural.
- **Characteristic types: ** citation laundering (the holding that never was), wrong attribution, over-extension, stale fact (superseded precedent), unsupported synthesis (an inferred holding).
- **Evidence requirement: ** every legal proposition bound to a verbatim span of a current, authoritative source, with the modality checked, held vs. argued vs. dicta is a distinction the model erases (Chapter 8's qualifier drop, in legal dress).
- **Retrieval/eval: ** authority-tiered corpus (binding vs. persuasive vs. secondary); currency filtering on overruled/superseded cases; eval for entailment of the holding, not topic match: the exact check the opening team lacked.
- **Mitigation stack: ** evidence-bound citations (Chapter 7) are mandatory, not optional → verification loop with entailment, not similarity → flag conclusions as inference, cite premises → abstain readily.
- **Monitoring: ** citation precision is the headline; user-correction rate from attorneys is high-signal.
- **Escalation: ** high, the assistant drafts and cites; an attorney decides. M defaults to "answer-with-evidence-for-review, " never "answer-as-authority."
Healthcare information assistant
Where dropped qualifiers and numeric drift can cause physical harm, and abstention is not caution but duty.
- **Characteristic types: ** dropped qualifier ("as needed" vs."daily"), numeric/dosage drift, entity swap (drug-name confusion), stale fact (guidelines change), learned falsehood (popular medical misconceptions, a TruthfulQA-adjacent risk).
- **Evidence requirement: ** every clinical claim bound to a current authoritative source; numeric claims pass a dedicated numeric gate; qualifiers preserved as first-class claims.
- **Retrieval/eval: ** curated authoritative corpus only (no open web); FActScore-style atomic factual precision on a clinician-labeled golden set; numeric-consistency suite.
- **Mitigation stack: ** narrow scope (information, not diagnosis) → RAG over curated sources → numeric gate → qualifier-preservation check → abstain-or-escalate as default, answer as exception.
- **Monitoring: ** unsupported-claim rate on numeric/qualifier slices; corpus drift on guideline updates (first-class).
- **Escalation: ** very high, for anything actionable, escalate to a clinician; the cost matrix weights confident-wrong catastrophically, so the operating point is low-coverage/low-risk.
Finance research assistant
Numbers, dates, and forward-looking statements, where a dropped hedge has regulatory weight.
- **Characteristic types: ** numeric/date drift, multi-document conflation (mixing two filings' figures), dropped qualifier on forward-looking statements (turning a hedge into a claim, a materiality risk), stale fact (figures revise).
- **Evidence requirement: ** every figure bound to a specific filing span with the period and units intact; conclusions flagged as inference.
- **Retrieval/eval: ** source-and-period-aware retrieval (Q3-2025 ≠ Q3-2024); numeric-consistency gate; eval for figure-level precision and qualifier preservation.
- **Mitigation stack: ** structured outputs with typed numeric fields and source spans → numeric gate → tool use for computation (don't let the model do arithmetic) → verification loop → abstain on uncovered figures.
- **Monitoring: ** citation precision and numeric-error rate; user corrections from analysts.
- **Escalation: ** high for anything used in a decision or disclosure; the assistant summarizes and cites, humans decide.
Customer support answer bot
High volume, public-facing, where the wrong answer is both a trust and sometimes a contractual problem.
- **Characteristic types: ** stale fact (policy/price changes), retrieval miss (customer phrasing ≠ doc phrasing), over-extension (promising what the policy doesn't), confident answer to an out-of-scope question.
- **Evidence requirement: ** every customer-facing claim bound to a current policy/KB span; show a link.
- **Retrieval/eval: ** hybrid retrieval tuned to customer vocabulary; large
unanswerable/out-of-scopegolden slice; track context recall and over-refusal. - **Mitigation stack: ** RAG + rerank → source-aware prompt → verification loop → abstain-to-human-handoff on low coverage (a graceful "let me connect you" beats a wrong promise).
- **Monitoring: ** unsupported-claim rate, abstention/handoff rate (both directions, over-handoff frustrates, under-handoff misleads), citation precision.
- **Escalation: ** medium-high, handoff to a human agent is the abstention action; for commitments (refunds, account changes), the agent acts (Chapter 9's irreversible-action gate).
Meeting summarizer
Chapter 8's domain, where invented decisions become real commitments.
- **Characteristic types: ** invented decisions/action items (slot-filling), dropped qualifier (hypothetical → decision), entity/owner swap, overcompression collapse.
- **Evidence requirement: ** every decision/action bound to a transcript span proving commitment, not discussion; modality checked.
- **Retrieval/eval: ** source is the transcript (trivial retrieval); faithfulness via claim-to-span NLI; a golden set of transcripts with labeled decisions including "no decision reached" cases.
- **Mitigation stack: ** prompt that licenses empty sections explicitly → faithfulness check on each decision/action → numeric gate (dates, figures) → flag low-confidence items rather than asserting.
- **Monitoring: ** faithfulness on the decisions/actions slice; user corrections ("we didn't decide that").
- **Escalation: ** low-medium, surface uncertain items as "discussed, not confirmed" rather than escalating, but never auto-assign action items without confirmation.
Code assistant
Where hallucination wears a different costume: invented APIs, nonexistent libraries, and confidently wrong usage.
- **Characteristic types: ** fabricated entity (nonexistent function/package/flag), over-extension (real API, wrong signature), stale fact (deprecated API), learned falsehood (a common-but-wrong pattern).
- **Evidence requirement: ** API claims bound to current documentation or, better, executed: the strongest verification a code assistant has is running the code.
- **Retrieval/eval: ** retrieve from version-pinned docs; eval against compilation/execution where possible (the truth is checkable mechanically); track fabricated-symbol rate.
- **Mitigation stack: ** tool use is uniquely powerful here, execute the code, read the error (Chapter 9's tool boundary) → RAG over pinned docs → flag unverified APIs → let the failing test be the abstention signal.
- **Monitoring: ** does-it-compile / does-it-run rate; fabricated-symbol rate.
- **Escalation: ** low, the compiler and test suite are the human-equivalent gate; surface unverified suggestions as such.
Workflow agent
The highest-stakes case, combining factual and action hallucination (Chapter 9).
- **Characteristic types: ** phantom action, misread success, stale-state action, imagined capability, silent chain failure, on top of all the factual types.
- **Evidence requirement: ** every "I did X" bound to a SUCCESS action-log entry; every factual claim bound to current state.
- **Retrieval/eval: ** action-log-grounded reporting; eval with injected tool failures (does it misread them as success?); capability-manifest constraint.
- **Mitigation stack: ** structured tool outputs with explicit status → completion guard (block "I did X" without a log entry) → observe-before-proceed control loop → human confirmation for irreversible actions.
- **Monitoring: ** action-claim/log-mismatch rate; tool-failure-misread rate; silent-chain-failure rate.
- **Escalation: ** very high for irreversible actions: confirmation before execution is the default, per Chapter 9 and OWASP Excessive Agency.
The cross-domain configuration table
The playbooks compress into one table that is the chapter's deliverable: the same machinery, six settings, tuned by stakes.
| Domain | Dominant types | Evidence bound to | Abstention bar | Escalation default |
|---|---|---|---|---|
| Internal KB | stale, miss, synthesis | current internal span | low | doc owner / ask human |
| Legal | laundering, stale, over-reach | verbatim current authority | high | attorney review |
| Healthcare | qualifier, numeric, learned-false | current authoritative span + numeric gate | very high | clinician |
| Finance | numeric, conflation, qualifier | filing span + period/units | high | analyst |
| Support | stale, miss, over-extension | current policy/KB span | medium-high | human agent handoff |
| Meeting summary | invented decision, qualifier | commitment span (modality) | low-medium | confirm, don't assert |
| Code | fabricated API, stale | docs or execution | low | compiler / tests |
| Workflow agent | phantom/misread action | SUCCESS log entry | very high | confirm before irreversible |
The closing argument
The book began with a sentence that sounded certain and was wrong, and a team that called it "hallucination" and learned nothing. It ends with a table of eight domains where the same five-step discipline, decompose the claim, link it to evidence, check the evidence's authority, judge whether inference exceeded it, and choose to answer, revise, ask, abstain, or escalate, is tuned to eight different cost structures. That is the whole movement of the book: from a single undifferentiated word to a configurable engineering discipline.
The chapter before this one, Operating Against Hallucination in Production, built the monitoring infrastructure these playbooks trigger when a rate rises. Appendix A contains the full glossary, implementation checklist, and source register. The thesis was never that hallucination can be eliminated. A system that produces novel sentences can produce novel false ones, and the floor, a confident, consistent, fluent falsehood with no available reference, is real and will not be argued away. The thesis was that hallucination is mechanical: it has nameable causes, each with a detector and a fix; it has a measurable rate you can slice, monitor, and bound; and the highest-use move when the chain cannot be completed is not a cleverer model but an honest refusal. **Fluency is not evidence. ** The model will always sound certain. Your system's job is to be the part that checks whether anything supports the certainty, and to say so, plainly, when nothing does.
Chapter summary
The machinery is constant across domains; only six settings differ, dominant hallucination types, evidence requirement, retrieval/eval strategy, mitigation stack, monitoring focus, and escalation rule, and a playbook is the machinery instantiated against a domain's failure profile and cost structure. Eight playbooks span the range: internal knowledge assistants (stale/miss, low abstention bar, ask-a-human escalation); legal research (citation laundering and stale precedent, verbatim-current-authority binding, mandatory evidence-bound citations, attorney review); healthcare (qualifier and numeric drift plus learned falsehoods, numeric gate, very high abstention bar, clinician escalation); finance (numeric/conflation/qualifier with materiality stakes, period-aware retrieval and computation tools); support (stale and over-extension, human-handoff as abstention); meeting summarizers (invented decisions, commitment-span binding, license-emptiness prompting); code assistants (fabricated APIs, execution as the strongest verification); and workflow agents (phantom and misread actions, action-log binding, human confirmation before irreversible actions). The cross-domain table is the deliverable: identical machinery, abstention bars from low to maxed, escalation from a Slack link to mandatory pre-execution confirmation. The closing argument: hallucination is not eliminable, the floor is real, but it is mechanical: nameable causes with detectors and fixes, a measurable rate to bound, and an honest refusal as the highest-use move when the evidence chain cannot be completed. Fluency is not evidence; the system's job is to check whether anything supports the certainty, and to say so when nothing does.