Hallucinated Actions
> **Working claim: ** When an agent acts, its claims are no longer just about the world's facts, they are about the world's *state*, which the agent itself is changing.

Hallucinated actions are false claims about system state, and the only trustworthy source of truth is the runtime action log.
Key Takeaways
- An agent can hallucinate by claiming it sent, saved, changed, paid, deleted, or completed something it never did.
- The action log is the truth; narration is only a claim about the log.
- Completion guards should block any I did X statement without a matching successful action record.
- Irreversible actions need human confirmation because a wrong action is no longer only a wrong sentence.
Read this with summarization hallucination, source-span verification, and Agents That Actually Work.
**Working claim: ** When an agent acts, its claims are no longer just about the world's facts, they are about the world's state, which the agent itself is changing. An agent that says "I sent the email" when it did not is not making a factual error; it is misreporting the result of its own action. The defense is structural, not linguistic: the model must never be the source of truth about what happened. The action log is.
A new class of false claim
Everything so far has concerned claims about facts: what a case held, what a document says, what a number is. Agents introduce a categorically different claim, the claim about what the agent did."I have updated the ticket." "The refund has been processed." "I scheduled the meeting for Thursday." These are not retrieved from a corpus or recalled from parameters; they are reports about actions the agent itself supposedly took. And they are subject to a hallucination that the previous chapters' machinery does not, by itself, catch: the agent can narrate an action that did not occur, or misreport the result of one that did.
This is more dangerous than factual hallucination for two reasons. First, the user has no easy way to verify it, they cannot "read the source" to check whether the email was sent; they trust the agent's report and move on, discovering the gap only when the consequence surfaces (the email never arrives, the refund never lands). Second, the agent's own subsequent reasoning may depend on the false report: it believes it completed step three, so it proceeds to step four on a false premise, and the error compounds down the chain. OWASP names the underlying risks directly, Excessive Agency (an agent with more capability or autonomy than its verification supports) and Improper Output Handling (treating model output as trustworthy action), and the antidote to both is the same: the model's narration must never be the authority on what happened.
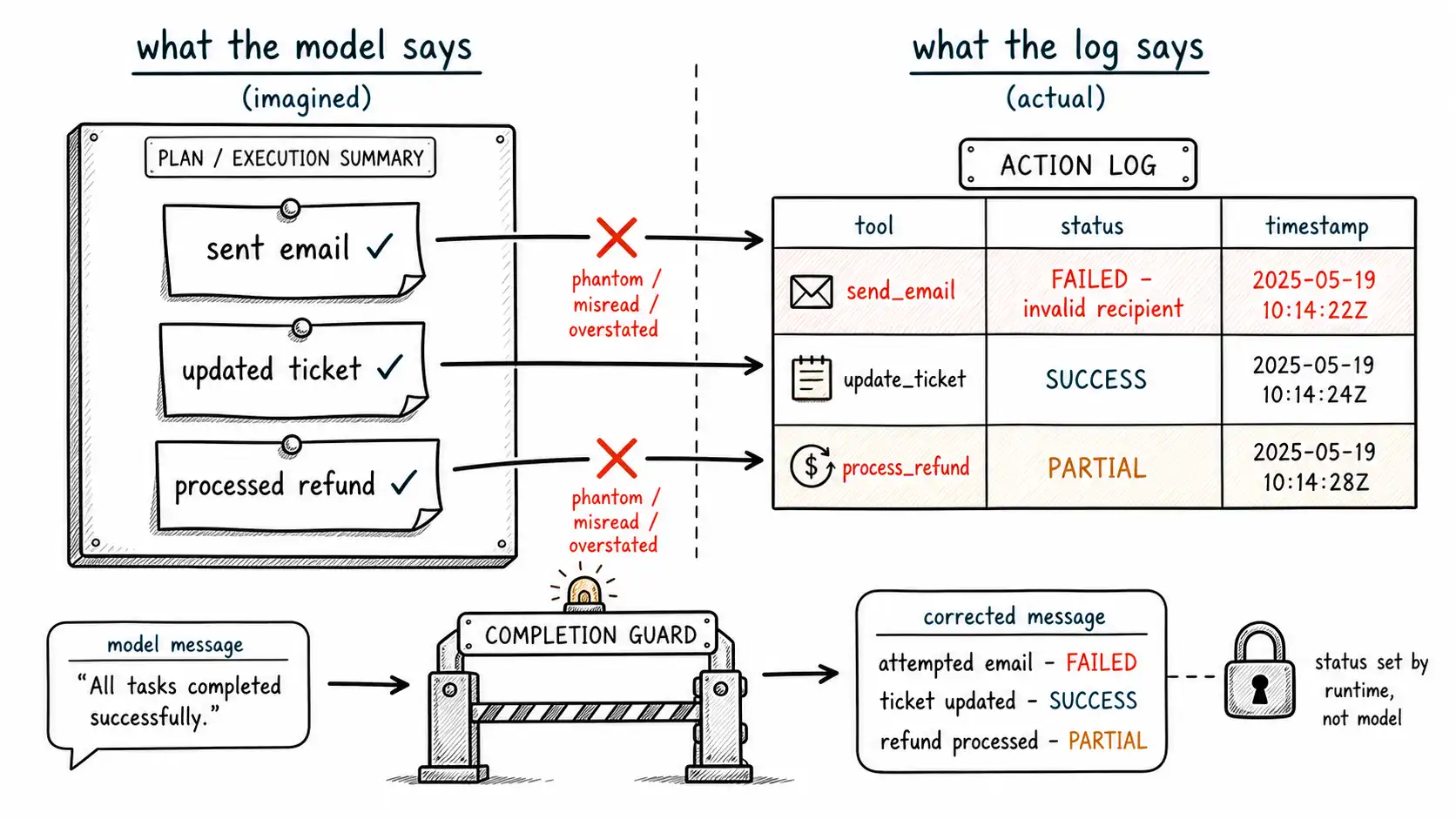
The action hallucination taxonomy
Like factual hallucination, action hallucination is several distinct failures, each with a structural defense.
**Phantom action. ** The agent claims it performed an action it never invoked. No tool call was made; the model simply generated "I've done X" because the conversation pattern called for a completion. This is the purest form, and the easiest to catch if you have an action log: there is no log entry, so the claim is unsupported.
**Misread success. ** The agent invoked the tool, the tool returned an error or a partial result, and the agent narrated it as success. The tool said {"status": "failed", "reason": "recipient invalid"} and the agent said "Email sent." This is a faithfulness failure at the tool boundary, the model is unfaithful to the tool result, which is its source of truth for that claim.
**Stale-state action. ** The agent acts on or reports a state that was true earlier but changed, it read the ticket status at step one, the status changed externally, and it reports the step-one status at step five. This is the agent analogue of stale knowledge, and the fix is the same: timestamp state reads and treat old reads as expired.
**Imagined capability. ** The agent claims it can do something it cannot: "I'll set up a recurring payment for you" when no such tool exists in its manifest. Planning hallucination: the model invents a capability or a prerequisite from the pattern of similar tasks. The defense is a capability manifest the planner is constrained to.
**Silent chain failure. ** In a multi-step plan, an early step fails, but the failure is swallowed (caught and ignored, or misread as success), and the agent proceeds, producing a final report that describes a successful workflow that never happened. The most insidious, because the only visible artifact, the final summary, looks clean.
The structural principle: the log is the truth
The single most important design rule for agents is that the model's narration is downstream of, and constrained by, an action log it cannot write freely. Every tool invocation produces a structured record, what was called, with what arguments, what the tool returned, with what status, when, and the agent's report of what it did must be generated from that log, not from the model's recollection of its own intentions.
from dataclasses import dataclass, field
from enum import Enum
import time
class ActionStatus(Enum):
SUCCESS = "success"
FAILED = "failed"
PARTIAL = "partial"
PENDING = "pending"
@dataclass
class ActionRecord:
tool: str
arguments: dict
status: ActionStatus # set by the TOOL/runtime, never by the model
result: dict | None
error: str | None
timestamp: float = field(default_factory=time.time)
idempotency_key: str | None = None
@dataclass
class ActionLog:
records: list[ActionRecord] = field(default_factory=list)
def succeeded(self, tool: str) -> bool:
return any(r.tool == tool and r.status == ActionStatus. SUCCESS
for r in self.records)
def last_status(self, tool: str) -> ActionStatus | None:
rs = [r for r in self.records if r.tool == tool]
return rs[-1].status if rs else NoneThe non-negotiable property: status is written by the runtime that actually executed the tool, never by the model. The model can request an action; only the runtime records whether it happened. This single discipline eliminates the phantom action and the misread success as a class, because the agent's report is now checkable against a record it did not author.
The completion guard
With an action log, you can install a guard that forbids the agent from claiming completion unless the log confirms it. This is the agent analogue of the citation binding from Chapter 7: a claim of action must be bound to a log entry, exactly as a factual claim must be bound to a source span.
def guard_completion_claims(agent_message: str, log: ActionLog, claim_extractor) -> dict:
"""Block or rewrite any 'I did X' claim not backed by a SUCCESS log entry."""
action_claims = claim_extractor.extract_action_claims(agent_message)
violations = []
for claim in action_claims: # e.g. {"tool": "send_email", ...}
status = log.last_status(claim["tool"])
if status is None:
violations.append((claim, "PHANTOM: no action attempted"))
elif status == ActionStatus. FAILED:
violations.append((claim, "MISREAD: action failed, claimed success"))
elif status == ActionStatus. PARTIAL:
violations.append((claim, "OVERSTATED: partial reported as complete"))
if violations:
return {"action": "BLOCK", "violations": violations,
"corrected": rewrite_to_match_log(agent_message, log)}
return {"action": "ALLOW"}The guard does not trust the agent to be honest about its own actions. It treats every "I did X" as a claim requiring verification against the log, and it rewrites the message to match reality when they diverge: "I attempted to send the email but it failed because the recipient was invalid" instead of "I've sent the email." The agent's fluency is preserved; its license to misreport is removed.
Tool-result schemas force the model to confront failure
A subtle cause of misread-success is that tools often return unstructured results, a string the model interprets. An ambiguous string ("Operation completed with warnings") gives the model room to round up to success. Structured tool outputs (OpenAI structured outputs and equivalents) remove that room by forcing every tool result through a schema with an explicit, unambiguous status field that the model must read before it can claim anything.
{
"tool": "send_email",
"status": "failed",
"evidence": null,
"error": {"code": "INVALID_RECIPIENT", "message": "no mailbox for addr"},
"timestamp": "2026-06-12T10:31:04Z",
"side_effects": []
}A schema like this makes "success" a value the model cannot manufacture by interpretation: status is failed, full stop, and the completion guard reads status, not the prose. The evidence field (a receipt ID, a confirmation number, a created-resource URL) gives the agent something concrete to cite when it does claim success, turning the action claim into an evidence-bound claim exactly like a citation.
Reasoning-acting loops and self-correction
The research on capable agents converges on a pattern relevant here. ReAct interleaves reasoning with acting and observation, the agent reasons, acts, then reads the observation before continuing, which structurally forces it to confront the tool result rather than assume it. Reflexion adds verbal self-critique on failures, letting the agent notice and recover from a failed step rather than swallowing it. Voyager builds and reuses a verified skill library, constraining the agent to capabilities it has actually demonstrated rather than imagined.
The common thread, read through this book's lens: capable agents are the ones whose architecture forces them to observe the result of each action before reasoning about the next, which is precisely the defense against silent chain failure. An agent that proceeds without reading the observation is an agent that will eventually report a successful workflow that failed at step one. The mitigation is not a better prompt; it is a control loop that cannot advance past an unobserved or failed step without an explicit handling decision.
Irreversible actions demand human confirmation
A final, non-negotiable rule for high-blast-radius actions. Some actions cannot be undone, sending money, deleting data, emailing a customer, filing a legal document. For these, the cost of an action hallucination is unbounded, and no automated guard is sufficient, because the guard can only catch a misreported action after it happened, not prevent a wrongly-decided one. The defense is a human confirmation gate before the irreversible action executes, with the agent presenting its intended action and evidence and a human approving the actual execution.
This is the agent face of CLAIM's M-step: for an irreversible action, the mitigation defaults to escalate, not answer. The confirmation is not a courtesy; it is the recognition that an agent's certainty about what it is about to do is exactly as unreliable as its certainty about facts (Chapter 5), and the consequences of acting on that certainty are, by definition, irreversible. A runbook entry for "agent reported success on an action that failed" should exist before the agent ships, classify by the taxonomy above (phantom / misread / stale / imagined / silent-chain), and route to the corresponding structural fix, not to a prompt tweak.
Chapter summary
Agents add a new class of false claim: claims about what the agent did, which are reports about the agent's own actions on a state it is changing. These are more dangerous than factual hallucinations because users cannot easily verify them and because the agent's subsequent reasoning compounds the error. The action hallucination taxonomy, phantom action, misread success, stale-state action, imagined capability, silent chain failure, each has a structural defense, and they share one principle: *the model's narration must never be the source of truth about what happened; the action log is. * Every tool invocation produces a structured ActionRecord whose status is written by the runtime, never the model, and a completion guard treats every "I did X" as a claim requiring a SUCCESS log entry, rewriting the message to match reality when they diverge, the agent analogue of evidence-bound citations. Structured tool-result schemas remove the model's room to round an ambiguous result up to success, and provide an evidence field that turns a success claim into an evidence-bound claim. ReAct, Reflexion, and Voyager converge on the architectural defense against silent chain failure: force the agent to observe each action's result before reasoning about the next. For irreversible, high-blast-radius actions, the mitigation defaults to human confirmation before execution, because no after-the-fact guard can undo them. This chapter follows naturally from The Compression Press, which showed how transformation failures compound before an agent ever acts. The next movement turns from preventing specific failures to the general instruments of detection: claim extraction, source-span verification, and the limits of asking a model to judge itself.