A Working Taxonomy of Hallucination
> **Working claim: ** A taxonomy is only useful if each category implies a *different detector and a different fix*. The categories that matter are not the ones that sound distinct in a paper, they are the ones that route to different engineering.

A hallucination taxonomy is useful only when the category tells an engineering team which detector to run and which station to repair.
Key Takeaways
- The taxonomy has two routing axes: what the claim contradicts and where support was lost.
- Intrinsic, extrinsic, faithfulness, and factuality are not vocabulary games; they choose different checks.
- Atomic claims are the unit of diagnosis because a paragraph is usually a mixture of supported and unsupported facts.
- The diagnostic ladder turns classification into a habit: decompose, type, seek support, seek contradiction, check authority, check boundary, check certainty.
Read this with the confident wrong answer, the CLAIM Framework, and A Field Guide to Evals.
**Working claim: ** A taxonomy is only useful if each category implies a different detector and a different fix. The categories that matter are not the ones that sound distinct in a paper, they are the ones that route to different engineering. This chapter builds a taxonomy along two axes that route work: what the claim contradicts, and where in the system the support was lost.
Why most taxonomies are useless
Open any survey and you will find a hallucination taxonomy. Most of them are organized for describing failures, not for acting on them. They sort by surface symptom, "factual error, " "logical inconsistency, " "irrelevance", which feels orderly and turns out to be operationally inert, because two failures in the same surface bucket can need opposite fixes, and two failures in different buckets can need the same one. A taxonomy earns its place in an engineering book only if the act of classifying a failure tells you what to build.
So we organize along two axes that route work directly.
The first axis is what the claim contradicts, which the literature already gives us. The NLG hallucination survey draws the intrinsic / extrinsic line: intrinsic hallucinations contradict the provided source; extrinsic ones add content the source neither supports nor contradicts. The LLM hallucination survey adds the faithfulness / factuality line: faithfulness is consistency with the input (instruction and context); factuality is consistency with the real world. These are not competing taxonomies; they are two questions you ask about every claim. Does it contradict what I gave it? (intrinsic vs. extrinsic.) Is it true of the world? (factual vs. not.) A claim can be faithful and false, or unfaithful and true.
The second axis is where the support was lost, the station in the system, the chain from Chapter 1. This axis is the book's contribution to the taxonomy, because it is the axis that names the fix. A claim with no supporting span lost its support at synthesis. A claim contradicted by the context lost it at generation against context. A claim about an action that did not happen lost it at the tool boundary. Same surface symptom, a confident wrong sentence, different station, different repair.
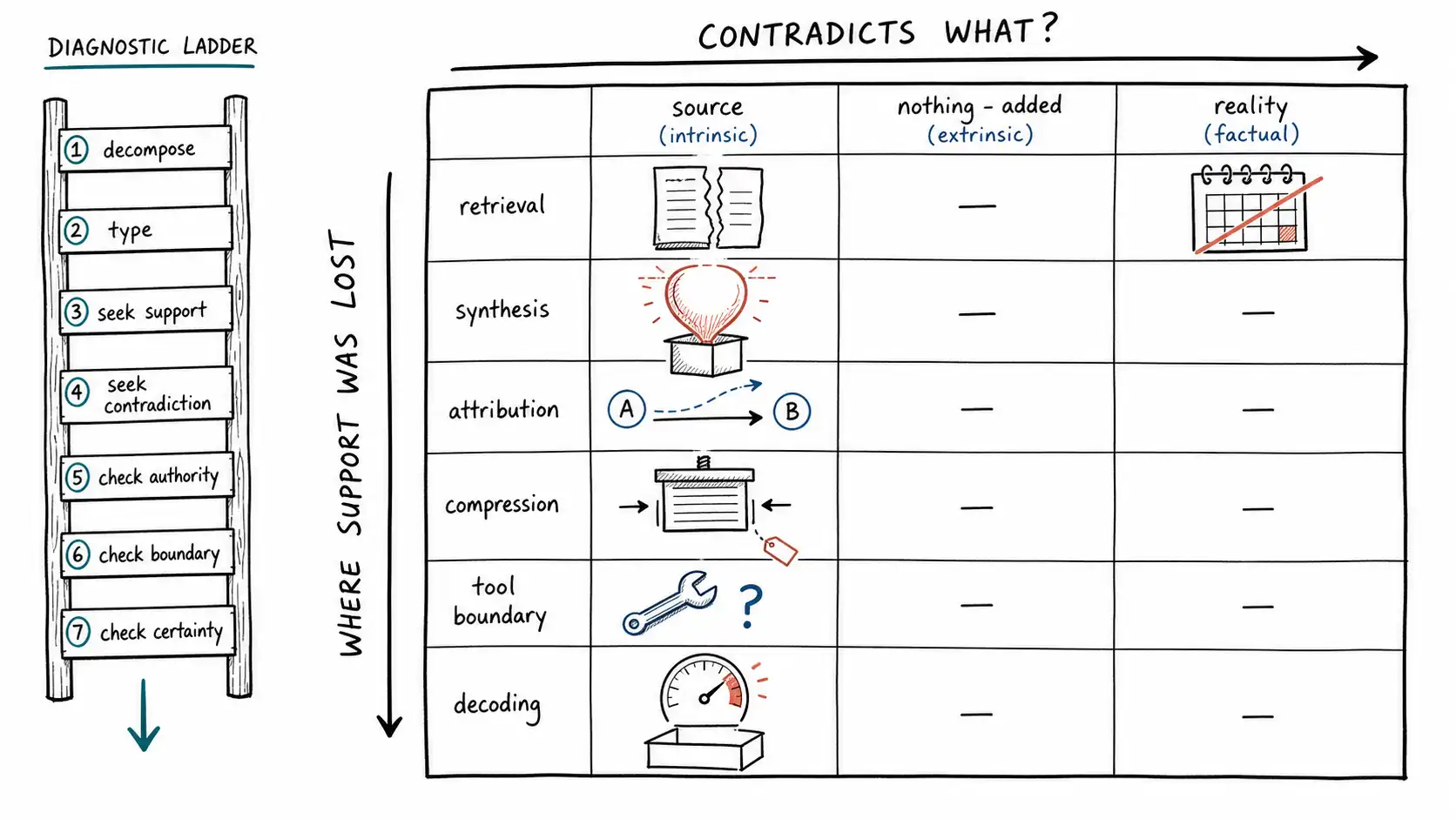
The two-axis matrix
Cross the axes and the failure modes fall out in a way that maps to chapters and to detectors.
| Failure mode | Contradicts what? | Lost support at | Detector | Covered in |
|---|---|---|---|---|
| Fabricated entity | Reality (extrinsic/factual) | Synthesis | Existence check vs. registry/source | Ch. 4, 10 |
| Fabricated citation | Reality (extrinsic/factual) | Attribution | Resolve reference against source store | Ch. 7 |
| Wrong attribution / citation laundering | Source (extrinsic) | Attribution binding | Entailment: span ⊨ claim | Ch. 7, 10 |
| Unsupported synthesis | Source (extrinsic) | Synthesis | Claim-to-evidence coverage | Ch. 6, 10 |
| Contradicted answer | Source (intrinsic) | Generation vs. context | NLI contradiction vs. context | Ch. 6, 10 |
| Stale fact | Reality (factual) | Retrieval / parametric memory | Currency check vs. dated source | Ch. 6 |
| Conflated / merged facts | Source (intrinsic) | Multi-doc synthesis | Per-source attribution check | Ch. 8 |
| Number / date / unit error | Source (intrinsic) | Transformation | Numeric extraction + comparison | Ch. 8 |
| Dropped qualifier | Source (intrinsic) | Compression | Hedge/scope preservation check | Ch. 8 |
| Invented tool result | Action record (faithfulness) | Tool boundary | Compare claim to action log | Ch. 9 |
| Misinterpreted tool failure | Action record (faithfulness) | Tool boundary | Status-field gating | Ch. 9 |
| Misplaced certainty | Calibration | Decoding / no abstention | Confidence vs. coverage gate | Ch. 5, 13 |
| Learned falsehood | Reality (factual) | Parametric memory | External fact check | Ch. 4 |
Read this table not as a list to memorize but as a router. When a failure arrives, you place it in a row, and the row tells you which detector should have caught it and which chapter explains the fix. The litigation failure occupied four rows at once. Most real failures occupy two or three. The skill is decomposition: most "hallucinations" are a few atomic failures braided together, and you cannot fix a braid, only its strands.
Atomic claims: the unit that makes the taxonomy work
The taxonomy operates on claims, not on answers, and this is the single most important methodological move in the book. An answer is a paragraph; a paragraph is not true or false, it is a mixture. FActScore made this concrete and measurable: it decomposes a generated biography into atomic facts, minimal, independently checkable statements, and scores the fraction of atomic facts supported by a reliable source. The headline insight is that a single generation can be, say, 80% supported and 20% fabricated, and a paragraph-level "is it hallucinated?" judgment throws that structure away.
Atomic decomposition is what lets the taxonomy route. Consider one sentence:
*The drug was approved in 2019 by the FDA for treating moderate-to-severe plaque psoriasis in adults, reducing symptoms in 73% of patients. *
That is not one claim. It is at least five:
- The drug was approved by the FDA.
- The approval was in 2019.
- The indication is moderate-to-severe plaque psoriasis.
- The indication is for adults.
- It reduced symptoms in 73% of patients.
Each routes differently. Claim 1 is an existence/event claim, checkable against a regulatory registry. Claim 2 is a date, a common stale-fact and number-error site. Claims 3 and 4 are scope qualifiers, exactly the kind compression silently drops (Chapter 8). Claim 5 is a numeric claim, which needs the specific source span and a unit/figure comparison. A paragraph-level grade, "looks plausible, ship it", sees none of this. Five claims, five detectors. Here is the decomposition as the data structure the rest of the book uses:
from dataclasses import dataclass
from enum import Enum
class ClaimType(Enum):
EXISTENCE = "existence" # entity/event exists
ATTRIBUTE = "attribute" # property of an entity
NUMERIC = "numeric" # number/date/unit
RELATION = "relation" # link between entities
QUALIFIER = "qualifier" # scope/condition/hedge
ACTION = "action" # the system did something
@dataclass
class AtomicClaim:
text: str
claim_type: ClaimType
# filled in by the verification pipeline (Chapter 10):
supporting_span: str | None = None
source_id: str | None = None
supported: bool | None = None # span ⊨ claim?
contradicted: bool | None = None # span ⊥ claim? (intrinsic)
label: str | None = None # taxonomy row, e.g."unsupported_synthesis"The discipline this enforces: a verifier never asks "is the answer hallucinated?" It asks, for each AtomicClaim, "is there a span that supports it, a span that contradicts it, or neither?" Three outcomes, and the third, neither, is where extrinsic hallucination lives and where most systems are blind, because they only check for contradiction.
Intrinsic and extrinsic, made concrete
The intrinsic/extrinsic distinction is abstract until you see it cost something. Take a source paragraph:
*Acme reported Q3 revenue of $4.2M, up 12% year over year. The company did not provide guidance for Q4. *
**Intrinsic hallucination: ** the output contradicts the source:
*Acme reported Q3 revenue of $4.2M, down 12% year over year. *
The number is right; the direction is inverted. This is catchable by a contradiction check against the source, because the source says the opposite. A natural-language-inference (NLI) model, or a careful LLM-as-judge prompted to find contradictions, will flag it.
**Extrinsic hallucination: ** the output adds content the source neither supports nor contradicts:
*Acme reported Q3 revenue of $4.2M, up 12% year over year, and expects continued growth in Q4. *
The source explicitly declined to give Q4 guidance. The model supplied it anyway, plausibly. There is nothing in the source to contradict, so a contradiction-only check passes it. This is the trap: most lightweight "faithfulness" checks look for contradiction, and extrinsic hallucination is invisible to them by construction. The only detector that catches it is a coverage check: every claim in the output must be entailed by some span in the source, and "expects continued growth in Q4" is entailed by nothing. Extrinsic hallucination is the more common and more dangerous failure precisely because the cheap detector misses it.
Faithfulness versus factuality, and why you usually want faithfulness
For grounded systems, RAG assistants, summarizers, support bots, you almost always want to optimize faithfulness first, even though factuality is what the user ultimately cares about. The reason is mechanical: faithfulness is checkable with the inputs you already have (the context and the output), while factuality requires an external world model you may not have and cannot fully trust. A system that is faithful to a curated, current, authoritative corpus is factual as a consequence, and you have moved the truth problem to where you can govern it: the corpus. This is why so much of the book's machinery, claim-to-span verification, citation binding, abstention when coverage fails, targets faithfulness. You make the corpus the source of truth, and then you enforce that the model says only what the corpus supports.
The catch, named here and revisited in Chapter 6, is that faithfulness to a wrong or stale source produces a confidently faithful falsehood. Faithfulness is necessary, not sufficient. The A in CLAIM: Authority: is the source current and authoritative?, is the bridge from faithfulness back to factuality.
The diagnostic ladder
The taxonomy is a router; the ladder is the routine you run to use it. For any suspect output, descend until a rung catches the failure:
- **Decompose. ** Break the output into atomic claims. (Skipping this is the most common mistake; you cannot classify a paragraph.)
- **Type each claim. ** Existence, attribute, numeric, relation, qualifier, action.
- **Seek support. ** For each claim, is there a span that entails it? If no, extrinsic; flag unsupported synthesis or fabrication.
- **Seek contradiction. ** Does any span contradict it? If yes, intrinsic; flag contradicted answer.
- **Check authority. ** If supported, is the source current and authoritative? If stale, flag stale fact.
- **Check the boundary. ** For action claims, does the action log confirm it? If no, flag invented tool result.
- **Check certainty. ** Was a low-coverage claim delivered as fact? Flag misplaced certainty (see TruthfulQA for a benchmark that systematically probes this failure across domains where models are most likely to assert false beliefs confidently).
What the taxonomy is not
Two honest caveats. First, the categories are not mutually exclusive, and they are not meant to be. Real failures braid. A single sentence can be an unsupported synthesis built on a stale retrieval expressed with misplaced certainty. The taxonomy's job is to let you name each strand so you can assign each fix, not to put the whole sentence in one box.
Second, classification itself is fallible, because the detectors are fallible. An NLI model can miss a subtle contradiction; an LLM judge can hallucinate while judging hallucination (SelfCheckGPT exists partly because reference-free detection is hard and probabilistic). The taxonomy does not make detection perfect. It makes detection targeted, it tells you which imperfect detector to point at which claim, which is strictly better than pointing one blunt "looks plausible?" judgment at the whole paragraph. Chapters 10 and 11 are honest about how good those detectors actually are.
Chapter summary
A hallucination taxonomy earns its place only if classifying a failure tells you what to build. This chapter organizes failures along two routing axes: what the claim contradicts (intrinsic vs. extrinsic from the NLG survey; faithfulness vs. factuality from the LLM survey) and where the support was lost (the station in the system). Crossing them yields a matrix where each cell maps to a specific detector and a specific chapter. The unit of analysis is the atomic claim, not the answer, the move FActScore made measurable, because a paragraph is a mixture of supported and unsupported claims, and only decomposition lets the taxonomy route. The most important practical distinction: contradiction-only "faithfulness" checks are blind to extrinsic hallucination by construction, since added-but-unsupported content contradicts nothing; catching it requires a coverage check that demands every claim be entailed by some span. For grounded systems, optimize faithfulness first because it is checkable with inputs you have, then use authority checks to bridge back to factuality. The diagnostic ladder, decompose, type, seek support, seek contradiction, check authority, check boundary, check certainty, is the routine that turns the taxonomy from a chart into a habit. This chapter builds on the opening analysis of The Confident Wrong Answer, which established why confident fluency is not evidence. The next chapter turns the taxonomy into the framework the rest of the book runs on: CLAIM.