A Taxonomy of Generated Data: and Why We Reach for It
> **Working claim: ** "Synthetic data" is not one thing.

Key Takeaways
- A Taxonomy of Generated Data: and Why We Reach for It treats synthetic data as a governed artifact, not a free replacement for reality.
- The safe use depends on the cell: training, evaluation, red-team, demo, privacy, or lineage all need different gates.
- Generated data earns its keep only when a real anchor, verifier, and owner survive after generation.
**Working claim: ** "Synthetic data" is not one thing. The risk of a generated example depends almost entirely on what it will be used for, and the same generated row can be harmless as a demo, useful as training augmentation, and disqualifying as an evaluation case. You cannot reason about synthetic data safely until you classify both what you generated and what you will do with it.
Why a taxonomy is not pedantry
The previous chapter's team made a mistake that a taxonomy would have prevented: they let one act, "generate tickets", produce data that they then used for two incompatible purposes, training and evaluation, without noticing the purposes had opposite requirements. This is the most common structural error in synthetic-data work, and it is not a knowledge gap. The engineers knew the difference between a training set and a test set. They simply did not have a habit of tagging each generated artifact with what it was and what it was for, so the categories blurred in a shared folder of .jsonl files.
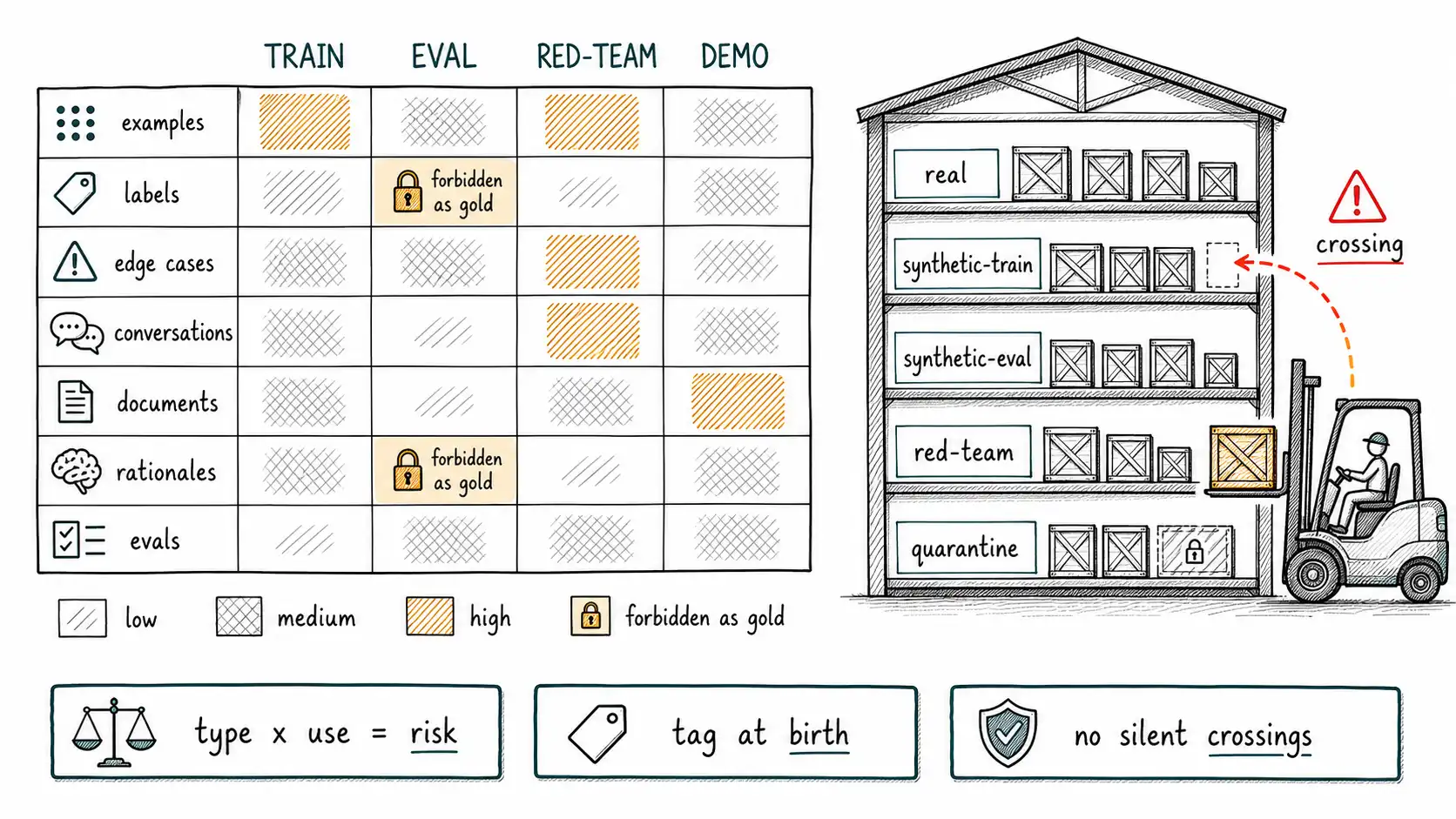
A taxonomy gives you those tags. It is the difference between a warehouse with labeled shelves and a pile in the corner. Two questions organize everything in this book: what did you generate (the artifact type) and what will you do with it (the use). The artifact type tells you the likely fingerprints. The use tells you which fingerprints are disqualifying. Cross the two and you get a risk profile, and the risk profile tells you how hard your gates need to be.
Axis one: what did you generate?
Generated data is not monolithic, and the type strongly predicts where it goes wrong.
| Artifact type | What it is | Where the fingerprints hide |
|---|---|---|
| Synthetic examples | New inputs in your domain (tickets, queries, images, rows) | Style, length, vocabulary, class balance, flattened toward the generator's defaults |
| Synthetic labels | A model annotates real or synthetic inputs | The generator's systematic errors become "ground truth"; rare-but-correct labels get smoothed away |
| Synthetic edge cases | Deliberately unusual inputs to stress a system | Often the only good use of fabrication, but easy to make unrealistic edge cases that test nothing real |
| Synthetic conversations | Multi-turn dialogues, often for tool-use or agent flows | Turn structure too clean; users too cooperative; tool errors under-represented |
| Synthetic documents | Long-form content for extraction or RAG tests | Format too regular; the answer is too findable; real document chaos is absent |
| Synthetic rationales | Step-by-step reasoning or explanations | The reasoning can be fluent and wrong; plausibility is not verification, the most dangerous type |
| Synthetic evals | Generated questions and/or expected answers | Encodes the generator's assumptions about what is askable and answerable; contamination risk is highest |
Two rows deserve a flag now and a chapter later. Synthetic rationales are the most dangerous artifact type because a generated chain of reasoning reads as if it were verified when it is merely fluent, a model can produce a confident, well-structured derivation of a wrong answer, and if you train on it, you are teaching the model to imitate confident wrongness. Self-Instruct and the instruction-tuning literature lean heavily on generated rationales precisely because they are useful, and the Self-Instruct filtering is in large part a defense against this. We return to rationales in Chapter 5. Synthetic evals carry the highest contamination risk, surveyed in depth in the data-contamination literature; Chapter 9 is devoted to them.
Axis two: what will you do with it?
The same generated example has a wildly different risk depending on its use. This is the axis teams skip, because the use often gets decided after generation, when the data is already sitting in a folder and the path of least resistance is "just use it everywhere."
| Use | Tolerance for generator fingerprints | The disqualifying defect |
|---|---|---|
| Training data | Moderate, diversity matters; some style bleed is survivable if anchored | Style monoculture; flattened tails; assumed labels |
| Evaluation data | Near zero, the eval must be a clean ruler | Any leakage from the generator that the system was trained on; shared style |
| Safety / red-team data | Generation is often the point, you want adversarial inputs | Coverage gaps the generator can't imagine; sanitized attacks that don't probe real failures |
| Demo data | High, nobody trains or evaluates on it | Accidentally leaking it into training or eval; using fake names that look real |
| Synthetic documentation | High, it illustrates, it doesn't measure | Being mistaken for ground truth later; carrying into training |
Read the table as a compatibility matrix. The most expensive errors are crossings: data generated for one use, repurposed for another with a stricter tolerance. Demo data that drifts into the training set. Training augmentation that gets sampled into an eval. Red-team prompts that leak into a benchmark and inflate safety scores. Each crossing is a quiet act, usually a copy-paste or a glob pattern that matched too much, and each one converts a harmless artifact into a contaminating one.
The risk matrix: type × use
Cross the two axes and you get an operational risk grid. The cell value is how hard your gates must be before the data is allowed into that use.
| Type \ Use | Training | Evaluation | Red-team | Demo |
|---|---|---|---|---|
| Examples | Medium (dedup, diversity, label check) | High (isolation proof required) | Low-Med | Low |
| Labels | High (verify against sample of truth) | Forbidden as gold (use human labels) | n/a | Low |
| Edge cases | Medium | High (don't let edges leak to train) | Low (this is their home) | Low |
| Conversations | Medium-High | High | Medium | Low |
| Documents | Medium | High | Medium | Low |
| Rationales | High (verify or don't train) | Forbidden as gold | Medium | Low |
| Evals | n/a | Highest (human acceptance gate) | Medium | Low |
The two "Forbidden" cells are the load-bearing ones. A model's labels must never be your evaluation gold, because then you are scoring a model against another model's opinion and calling it accuracy. A model's rationales must never be your evaluation gold for the same reason, with the added hazard that fluent reasoning hides its wrongness. You can use generated labels and rationales in training if you verify them against a real anchor, which is the subject of Chapters 5 and 8. You cannot use them as the ruler you measure by.
This grid is also the answer to the question "how careful do I have to be?" The careful answer is: it depends on the cell. A synthetic demo conversation needs almost no gates. A synthetic evaluation set needs the strictest gates in the entire book. Treating all synthetic data with one policy, either "always fine" or "always dangerous", guarantees you over-spend on the harmless and under-protect against the catastrophic.
Why teams actually reach for synthetic data
The taxonomy explains what you have; this section explains why you wanted it, because the motivation predicts the trap. Teams reach for generation for a handful of recurring reasons, and each has a characteristic failure.
**Data scarcity. ** "We don't have enough examples." This is the support team's motivation and the most common one. The trap is mistaking volume for coverage, generating ten thousand examples that all sit in the same dense region you already had, while the tail you actually needed stays empty. Volume is cheap; coverage is the hard part, and Chapter 6 is about measuring it.
**Class imbalance. ** "We have plenty of data but the rare class is rare." Generation to balance minority classes is legitimate and often genuinely helps. The trap is that the rare class is rare for a reason, it lives in an unusual part of the distribution, and a generator asked to produce more of it tends to produce a tidy, central version of an inherently weird thing. You balance the count and flatten the shape.
**Privacy. ** "We can't use the real data, so we'll generate a synthetic stand-in." This is the most over-trusted motivation. Synthetic data is not automatically private, a generator trained or prompted on sensitive data can reproduce it, and "synthetic" is not a magic word that strips liability. Chapter 12 is the whole argument; for now, treat privacy as a reason to be more careful, not a reason to relax.
**Edge cases and testing. ** "We need inputs our logs never captured." This is generation's best use, because fabrication is appropriate here, you want the unusual case, and you are testing behavior, not measuring a distribution. The trap is fabricating edges that are weird in a way the system already handles, while missing the edges that actually break it.
**Cost and speed of labeling. ** "Human labeling is slow and expensive; let a model label." Legitimate as assistance, a model proposing labels for humans to confirm, and dangerous as replacement. The data-contamination survey and the broader evaluation literature keep finding the same thing: model-generated labels carry the model's systematic biases, and if those become your ground truth, you have laundered the model's errors into your metrics.
The honest version of all five motivations is the same sentence: *generation can fill a specific, named gap, and it cannot replace the reality it is standing in for. * The successes, Self-Instruct, the Textbooks/Phi line, all generated toward a named gap with heavy filtering. The failures generated toward "more data" and trained on the pile.
A first-contact decision tree
Before generation, run the artifact through this tree. It is the operational compression of this chapter.
1. What am I generating? (example / label / edge / convo / doc / rationale / eval)
2. What will it be USED for? (train / eval / red-team / demo)
3. Look up the risk cell in the type×use grid.
- "Forbidden as gold"? -> STOP. Use humans/real data for this slot.
- "Highest" / "High"? -> Proceed only with isolation proof + human gate.
- "Medium"? -> Proceed with dedup, diversity, and label verification.
- "Low"? -> Proceed; tag it so it never silently crosses into a stricter use.
4. Will it ever cross into a stricter use later? (almost always "yes" unless you prevent it)
- Tag every example with source_type and intended_use NOW.
- Set eval_exclusion=true on anything generated by a model the system trains on.Step 4 is the one that prevents the crossings. The reason demo data ends up in training and red-team prompts end up in benchmarks is that nobody tagged them at birth, so months later a glob pattern swept them up. The NIST AI RMF frames this as a mapping and governance function, knowing what your data assets are and what they are approved for, and the Datasheets for Datasets work makes the same point from the documentation side: a dataset without a record of what it is and what it's for will be misused, not maliciously, just by default. The next two chapters turn that tag into a real provenance system.
Chapter summary
"Synthetic data" is not one substance. Two axes organize it: what you generated (examples, labels, edge cases, conversations, documents, rationales, evals) and what you will use it for (training, evaluation, red-team, demo). The artifact type predicts the fingerprints; the use determines which fingerprints are disqualifying. Crossing the two yields a risk matrix whose two non-negotiable cells are that model-generated labels and model-generated rationales must never serve as evaluation gold, using them as the ruler launders the model's errors into your metrics. The most expensive real-world errors are crossings: data generated for a lenient use (demo) that silently migrates into a strict one (training, eval), usually because nobody tagged it at birth. Teams reach for generation to fix scarcity, imbalance, privacy, testing, and labeling cost; each motivation has a signature trap, and the honest framing of all five is identical, generation fills a named gap and cannot replace the reality it stands in for. The defense is to tag every artifact with its type and intended use at creation, set eval-exclusion flags immediately, and let the risk cell dictate how hard the downstream gates must be.