Operating Synthetic Data with CAREFUL
> **Working claim: ** Everything in this book reduces to a single operating discipline: a synthetic dataset is a data *product* with a lifecycle, and a mature team can answer the CAREFUL questions for any dataset it ships, from purpose through retirement.

Key Takeaways
- Operating Synthetic Data with CAREFUL treats synthetic data as a governed artifact, not a free replacement for reality.
- The safe use depends on the cell: training, evaluation, red-team, demo, privacy, or lineage all need different gates.
- Generated data earns its keep only when a real anchor, verifier, and owner survive after generation.
**Working claim: ** Everything in this book reduces to a single operating discipline: a synthetic dataset is a data product with a lifecycle, and a mature team can answer the CAREFUL questions for any dataset it ships, from purpose through retirement. The change this book is trying to install is a reflex, from "can we generate more?" to "what reality anchors this, and what damage could it do if we are wrong?"
The whole book as a lifecycle
The introduction promised an organization around the lifecycle of generated data: purpose → generation → filtering → labeling → evaluation → training → monitoring → retirement. This final chapter closes the loop by walking a single dataset through that lifecycle one more time, with each stage's controls in place, and showing how CAREFUL is the question set that gates each transition. It is not a new technique; it is the synthesis, the thing a team should be able to do fluently after the previous fifteen chapters, and it is the same map-measure-manage-govern lifecycle the NIST AI Risk Management Framework asks of any AI data asset.
Return to the support-intent dataset that opened the book, but this time, operated carefully. Watching the correct version run is the most useful summary the book can offer, because every control appears in its place and the Chapter 1 failure becomes impossible at each step where it originally happened.
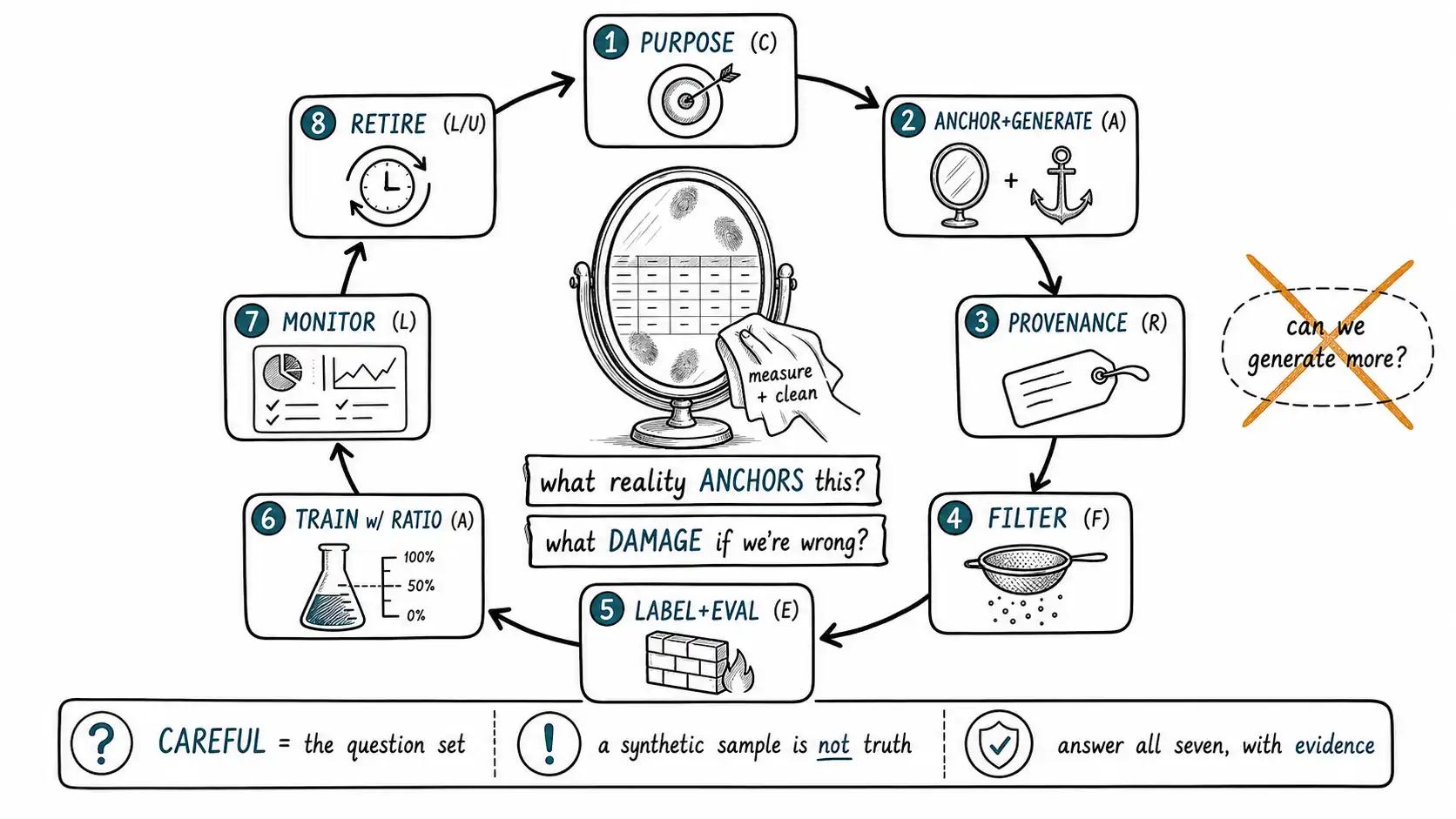
Stage 1: Purpose (CAREFUL: C)
The team needs more examples of rare compliance intents. Before any prompt is written, they fill the purpose worksheet (Chapter 1): the gap is named (intents with < 40 real examples), the reason real data won't suffice is stated (compliance intents are rare by nature), and the success criterion is defined as per-class recall on real, held-aside rare tickets, not aggregate accuracy on a mixed pool. Legal review happens here (Chapter 13), confirming the seed tickets can be used to generate. The Clear purpose question is answered, and one red flag from Chapter 1, measuring success on a contaminated split, is eliminated before it can occur.
Stage 2: Anchor and Generate (CAREFUL: A)
The team holds 38 real rare tickets as a permanent anchor, flagged never_train_on and eval_exclusion so they can never be generated over or leaked into a metric. They characterize the real distribution (terse, hostile, multi-channel, long tail) and simulate toward it rather than fabricating toward the generator's defaults, the simulation-vs-fabrication distinction of Chapter 1. Diversity is forced during generation across length, tone, channel, and difficulty (Chapter 6), the same generate-then-filter-for-novelty discipline that made Self-Instruct work. The Anchored reality question is answered: there is a named real anchor, and generation aims at a measured target.
Stage 3: Record Provenance (CAREFUL: R)
Every generated example is written to the lineage table (Chapter 3) in the same operation that produces it, generator and version, prompt hash, seed example, sampling params, intended use, eval_exclusion=true. The synthetic-has-provenance constraint refuses any row that cannot name its generator and prompt. The prompt templates are promoted out of the notebook into the versioned template store. The Recorded provenance question is answered: there will be no 2 a.m. problem, because traceability is structural, not aspirational, the Datasheets for Datasets discipline made an enforced property of every row rather than a document someone is supposed to maintain.
Stage 4: Filter (CAREFUL: F)
The candidate pool runs the ordered gate cascade (Chapter 7): format, exact dedup, early PII/toxicity scan (Chapter 12's Layer-3 known-real-identifier match catches any echoed seed PII), near-duplicate clustering, the realism classifier (targeting low AUC for this training use), and label consistency. Multiple judges score the survivors; disagreement routes to humans, and a calibration sample of auto-decided cases spot-checks for shared blind spots (Chapter 8). Everything rejected goes to the audit reject set with its reason. The Filtering gates question is answered, and the assumed-label failure of Chapter 1 is caught by the label-consistency gate.
Stage 5: Label and Evaluate (CAREFUL: E)
Labels are verified, not assumed, the human-reviewed sample produces the label-accuracy metric (Chapter 6) that goes in the manifest. Critically, evaluation is isolated by construction (Chapter 9): the eval set is the real, human-labeled holdout (the 38 anchor tickets plus additional real ones, never synthetic), the training loader's guard query aborts if any eval_exclusion row appears in training, and the generator-provenance check confirms no eval item came from the system's training lineage (the contamination failure mode catalogued in the data-contamination survey). The Evaluation isolation question is answered, and the single fatal Chapter 1 defect, eval sharing the generator's fingerprints, is now structurally impossible.
Stage 6: Train with a Ratio (CAREFUL: A again, as a maintained anchor)
The training mix respects the manifest's max_synthetic_ratio (Chapter 11), enforced at build time with diversity-preserving downsampling and a logged actual ratio. The real anchor is included as the real tail. This keeps the dataset out of the collapse regime (Chapter 10): one generation, filtered, anchored, ratio-capped, the Phi-line conditions, not the recursive-unanchored-unfiltered danger quadrant.
Stage 7: Monitor (CAREFUL: L)
The model ships with slice monitoring defined before training (Chapter 11): rare intents, hard difficulty, under-covered channels, long inputs, each watched in production against the real baseline. A production-vs-training coverage drift monitor watches for live traffic landing in regions the synthetic-heavy training under-covered. The collapse signature, a slice degrading while aggregate holds, would now trigger investigation instead of becoming the silent incident it was in Chapter 1. The Lifecycle monitoring question is answered.
Stage 8: Retire (CAREFUL: L completes, U enforced throughout)
The manifest's expires_at and prohibited_use are live constraints (Chapter 4): the dataset cannot be loaded for a prohibited use, and when the real distribution shifts enough that the synthetic data no longer reflects it, the dataset is regenerated (a reviewable diff, Chapter 4) or retired, not silently reused. The Use limits question is answered continuously, and retirement closes the lifecycle.
CAREFUL as the question set, mapped to the book
The framework is not decoration; it is the index of the book's controls. Here is the full mapping, which doubles as a navigation aid.
| Letter | Question | Primary chapters | The control |
|---|---|---|---|
| C | Why generate this? | 1, 2, 13 | Purpose worksheet; type×use grid; early legal review |
| A | What anchors it in reality? | 1, 6, 10, 11, 15 | Real anchor held aside; diversity measured vs. real; ratio cap; the verifier |
| R | Can every example be traced? | 3, 4 | Lineage schema; manifest; reproducible diff |
| E | Is eval isolated from training? | 9 | Never-train-on flag; leakage scans; generator-provenance check |
| F | What gates decide inclusion? | 7, 8 | Ordered gate cascade; judge disagreement; retained reject set |
| U | What is it forbidden to do? | 2, 4, 12, 13 | Prohibited-use enforcement; tenant scope; approval workflow |
| L | How are failures caught and the dataset retired? | 11, 14, 15 | Slice monitoring; drift detection; expiry and retirement |
A team that can answer all seven for a dataset, with evidence and not intention, is operating synthetic data carefully. A team that can answer none of them is the Chapter 1 team, and a team that can answer some is somewhere on the road between, which is most teams, and the honest place to start.
The reflex, finally
The book opened with a sentence that should make you nervous, "we don't have enough data, so we'll generate some", and a promise to replace one question with a better pair. Here is the replacement, earned.
The instinctive question, can we generate more?, is useless because the answer is always yes; generation is cheap, and cheapness is precisely why the question carries no information. The two questions that carry all the information are:
**What reality anchors this data? ** **What damage could it do if we are wrong? **
The first question is CAREFUL's spine, A, with R and E as its enforcement, and it is the question the Chapter 1 team never asked. They had a real anchor (38 tickets) and never used it; they had a real distribution and never characterized it; they had a clean evaluation available (real labeled tickets) and contaminated it instead. The second question is the risk lens, the blast radius, the reversibility, the cost of confident wrongness, and it is what calibrates how careful to be, which Chapters 14 and 15 showed swings from "lean hard on synthetic" (code, cheap verifier, low harm) to "barely at all" (cautious domains, no verifier, high harm).
The mirror metaphor that runs through the book makes the same point in a sentence. **Synthetic data is a mirror with fingerprints. ** The mirror is useful, it shows you gaps, edge cases, rare classes you could not otherwise see. But the fingerprints, the generator's style, its flattened tails, its confident errors, its blind spots, are on the glass whether or not you look for them, and they stay there until you measure and wipe them off. A team that holds the mirror up and believes the reflection ships the Chapter 1 classifier. A team that holds the mirror up, names the fingerprints, measures them against reality, and cleans the glass before believing what it shows, that team uses synthetic data carefully, which is the only way it is worth using at all.
Chapter summary
Everything in the book reduces to one discipline: a synthetic dataset is a data product with a lifecycle (purpose → generation → filtering → labeling → evaluation → training → monitoring → retirement), and CAREFUL is the question set that gates each transition. Walking the Chapter 1 support dataset through the lifecycle done correctly makes the original failure impossible at each step: a named purpose with success defined as per-class recall on real held-aside tickets (C); a protected real anchor with simulation toward a measured, diversity-forced target (A); structural provenance written in the same operation that generates each example (R); an ordered gate cascade with judge disagreement and a retained reject set (F); evaluation isolated by construction with leakage and generator-provenance checks (E); a ratio-capped, anchored, single-generation training mix that stays in the Phi regime rather than the collapse quadrant; pre-defined slice and drift monitoring that would surface the collapse signature instead of letting it become a silent incident (L); and live prohibited-use and expiry constraints that enforce use limits and retirement (U/L). The CAREFUL table indexes the book's controls to their chapters. The reflex the book installs replaces the useless "can we generate more?" (always yes, hence uninformative) with the two informative questions: "what reality anchors this data?" and "what damage could it do if we are wrong?", the first being CAREFUL's spine and the second calibrating how careful to be. The mirror-with-fingerprints metaphor closes it: synthetic data reflects real gaps but carries the generator's fingerprints on the glass until measured and wiped off, and a team that cleans the glass before believing the reflection is the only kind that uses synthetic data carefully, the only way it is worth using.