Poisoning, Approvals, and the Governance of Generation
> **Working claim: ** A synthetic-data pipeline is an attack surface and a control surface at once.

Key Takeaways
- Poisoning, Approvals, and the Governance of Generation treats synthetic data as a governed artifact, not a free replacement for reality.
- The safe use depends on the cell: training, evaluation, red-team, demo, privacy, or lineage all need different gates.
- Generated data earns its keep only when a real anchor, verifier, and owner survive after generation.
**Working claim: ** A synthetic-data pipeline is an attack surface and a control surface at once. Generation jobs run with privileged access to seed data and write directly into training sets, so they must be governed like any other privileged system: scoped access, dataset approvals, poisoning defenses, audit evidence, and a quarantine state that is the default, not the exception.
The pipeline is privileged
Most discussions of synthetic data treat the pipeline as a neutral utility: data goes in, data comes out, nobody thinks about who can run it or what it can touch. That framing is a security gap. A generation pipeline reads seed data (often the most sensitive data you have), invokes models, and writes examples that flow into training sets that shape production models. That is a privileged path from sensitive input to production behavior, and privileged paths get governed or they get exploited.
The OWASP LLM Top 10 names data and model poisoning as a top risk for exactly this reason, and the poisoning-web-scale-datasets work showed that injecting malicious examples into training data is practical and cheap at scale. A synthetic-data pipeline is a concentrated version of that risk: instead of an attacker poisoning a public web crawl, the poison can enter through your own generation step, a compromised prompt template, a tampered seed set, a manipulated generator, or simply an insider who can write to the training set without review. This chapter governs that surface.
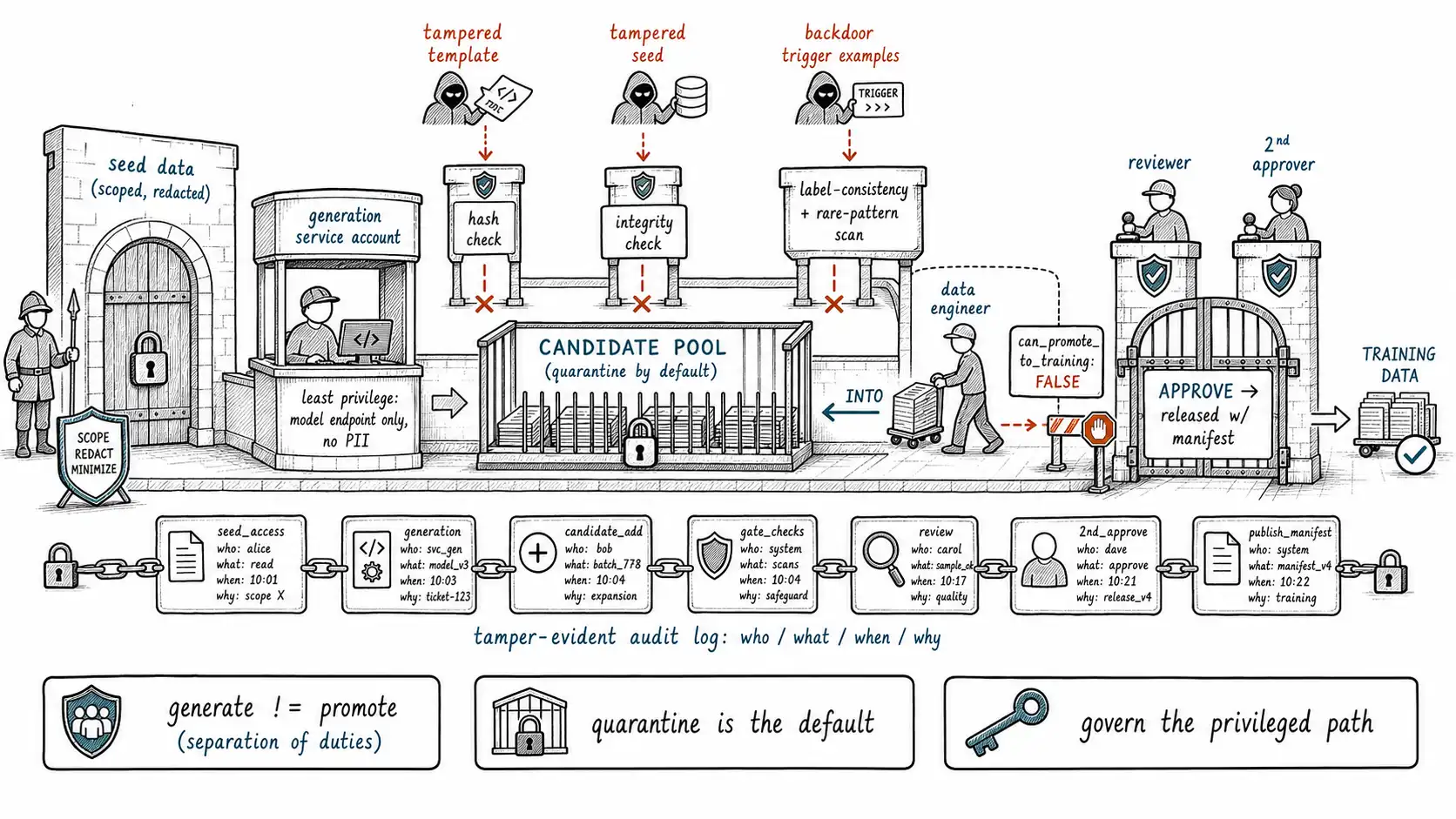
Poisoning through the synthetic pipeline
Poisoning in a synthetic pipeline has its own routes, distinct from the public-web threat model, and naming them is the first defense.
| Route | How it works | Control |
|---|---|---|
| Prompt-template tampering | Altered template biases or backdoors all examples it produces | Version + review templates (Ch. 4); hash in manifest |
| Seed-set tampering | Poisoned seeds propagate into generated variants | Provenance + integrity check on seed sources |
| Generator manipulation | A compromised or swapped generator emits crafted examples | Pin generator version; record in manifest; anomaly-scan output |
| Unreviewed direct write | Anyone can append to the training set without a gate | Approval workflow; no human writes to train without review |
| Trigger/backdoor injection | Rare trigger phrases mapped to a malicious label | Label-consistency gate; rare-pattern scan on the reject set |
The last route is the subtle one. A backdoor is a small set of examples that teach the model to behave anomalously on a rare trigger, for instance, examples that map a specific unusual phrase to a wrong-but-attacker-chosen label. Because the trigger is rare, it does not move aggregate metrics and survives normal evaluation. The defenses are the gates this book already built, pointed at this threat: the label-consistency check (Chapter 7) catches trigger-to-wrong-label mappings, and the reject set (Chapter 7) is where you scan for suspicious rare patterns, because a backdoor often shows up as a cluster of near-identical odd examples that a near-duplicate scan flags. Provenance (Chapter 3) is what lets you trace a discovered backdoor back to the prompt, seed, or generator that produced it and purge the whole batch.
Access control for generation jobs
A generation job should run with the least privilege required, like any other job touching sensitive data, the OpenAI safety-best-practices deployment-controls posture applied to data generation. The principle is that the ability to generate data and the ability to promote it into a training set are different privileges held by different roles.
# Access policy for synthetic-data generation jobs.
roles:
data_engineer:
can_run_generation: true
seed_access: ["scoped_to_assigned_project"] # not all seed data, only theirs
can_write_to: ["candidate_pool"] # candidates, NOT training set
can_promote_to_training: false # separation of duties
data_reviewer:
can_run_generation: false
can_review: true
can_promote_to_training: true # only via approved dataset
requires: ["second_approver_for_high_risk"]
generation_service_account:
seed_access: ["redacted_only"] # service never sees raw PII (Ch.12)
network: ["model_endpoint_only"] # no exfiltration path
output_to: ["candidate_pool_with_provenance"] # must write lineage (Ch.3)
guardrails:
raw_pii_to_generation_prompt: "DENY" # enforced at the prompt-build layer
write_to_training_without_manifest: "DENY" # Ch.4 enforcement
generation_without_recorded_provenance: "DENY" # Ch.3 constraintThe load-bearing line is can_promote_to_training: false on the role that generates. Separation of duties means the person who produces synthetic data cannot, alone, push it into a model. That single boundary defeats the most common poisoning route (unreviewed direct write) and the most common honest mistake (a debugging dataset that drifts into training), because both require crossing a role boundary that the system enforces.
The dataset approval workflow
Promotion from candidate pool to training set runs through an approval workflow whose states are the warehouse shelves of Chapter 2 made into a lifecycle. The default state is quarantine, data is guilty until reviewed, which inverts the dangerous default where data is usable until someone objects.
[generated] --> [candidate_pool] --> (gates: dedup, PII, realism, label, judges) -->
| |
v v
[rejected: audit set] [needs_review: human queue]
|
human + (2nd approver if high-risk)
|
approve --> [released w/ manifest]
reject --> [quarantined: audit]Two states deserve emphasis. Quarantine is a real state, not a folder name, quarantined data is access-controlled, retained for audit, and cannot be loaded by any training job (the manifest status check of Chapter 4). And high-risk datasets require a second approver, where "high-risk" is defined by the type×use grid of Chapter 2: anything destined for eval, anything seeded by sensitive or multi-tenant data, anything in a cautious domain (Chapter 15). The second approver is the human control that the NIST AI RMF "manage" function calls for on consequential decisions, applied to the specific consequential decision of admitting generated data into a model.
Audit evidence
Governance that cannot be audited is theater. The pipeline must produce evidence, automatically, as a byproduct of operation, sufficient to reconstruct, months later, what data entered which model, who approved it, and why. This is an append-only audit log, and its schema is deliberately strict.
CREATE TABLE synth_pipeline_audit (
event_id BIGSERIAL PRIMARY KEY,
event_time TIMESTAMPTZ NOT NULL DEFAULT now(),
actor TEXT NOT NULL, -- human or service account
action TEXT NOT NULL CHECK (action IN (
'generate','filter_reject','filter_keep','pii_block',
'submit_review','approve','reject','promote_to_train',
'quarantine','delete','regenerate','retire')),
dataset_id TEXT,
example_count INTEGER,
manifest_hash TEXT, -- which manifest version
reason TEXT, -- required for reject/approve/quarantine
approver TEXT, -- second approver where required
prev_event_hash TEXT NOT NULL, -- hash chain: tamper-evident
this_event_hash TEXT NOT NULL
);
-- The question this table can always answer:
-- "What synthetic data entered model training_run_42, who approved it, when, and why?"
SELECT a.event_time, a.actor, a.approver, a.dataset_id, a.example_count, a.reason
FROM synth_pipeline_audit a
WHERE a.action = 'promote_to_train'
AND a.dataset_id IN (SELECT dataset_id FROM training_run_inputs WHERE run='training_run_42')
ORDER BY a.event_time;The prev_event_hash/this_event_hash chain makes the log tamper-evident: an inserted or altered event breaks the chain, so the audit trail can be trusted as evidence rather than merely as logging. The query at the bottom is the capability the whole table exists for, the ability to answer, for any deployed model, exactly which generated data it was trained on, who approved that data, and what reason they recorded. The contamination survey keeps finding that the inability to answer this question is what lets contamination and poisoning persist undetected; the audit log is the mechanism that makes the question answerable.
Legal and policy review as a gate, not an afterthought
For consequential systems, generated data usage needs legal and policy review, and the failure mode is treating it as a final sign-off rather than a gate. By the time a dataset is generated, filtered, and ready to ship, the cost of a legal objection is enormous, the work is done. The review belongs earlier, at the purpose stage (CAREFUL's C), where the cheap questions get asked: Are we allowed to use this seed data to generate? Does the intended use comply with the consent under which the seed data was collected? Does generating from a vendor model's output comply with that vendor's terms? Are we creating data in a regulated domain that carries obligations? These are policy questions with policy answers, and answering them before generation costs a meeting; answering them after costs the dataset.
The governance principle that ties the chapter together is from the NIST AI RMF: govern, map, measure, manage. A synthetic-data pipeline maps its data assets (provenance), measures their quality (filtering, diversity), manages their risk (ratios, monitoring), and governs the whole thing through access control, approvals, audit, and review. The earlier chapters built map, measure, and manage. This chapter built govern, and the lesson is that the governance is not bureaucratic overhead bolted on at the end, it is the access boundary, the approval gate, the audit chain, and the early legal review that make a privileged, exploitable pipeline into a controlled one.
Chapter summary
A synthetic-data pipeline is a privileged path from sensitive seed data to production model behavior, making it both an attack surface and a control surface that must be governed like any privileged system. Poisoning has pipeline-specific routes, template tampering, seed tampering, generator manipulation, unreviewed direct writes, and rare-trigger backdoors, and the defenses are the book's existing gates pointed at this threat: versioned/hashed templates, seed integrity checks, pinned generators, label-consistency checks, rare-pattern scans on the reject set, and provenance to trace a discovered backdoor to its source. Access control enforces separation of duties: the role that generates data cannot promote it to training, which alone defeats the unreviewed-direct-write route and the debugging-data-drifts-into-training mistake; the generation service account runs least-privilege with redacted-only seed access and no exfiltration path. Promotion runs through an approval workflow whose default state is quarantine (data guilty until reviewed) and where high-risk datasets, eval-bound, sensitive-seeded, multi-tenant, cautious-domain, require a second approver. A tamper-evident, hash-chained audit log produces evidence as a byproduct of operation, able to answer for any model exactly which generated data it was trained on, who approved it, and why. Legal and policy review belongs at the purpose stage as a cheap gate, not as an expensive afterthought sign-off. Together these complete the NIST govern-map-measure-manage posture, with this chapter supplying the governance that turns an exploitable pipeline into a controlled one.