The Privacy Myth and What Generated Data Actually Leaks
> **Working claim: ** "Synthetic data is private" is the most over-trusted sentence in this field.

Key Takeaways
- The Privacy Myth and What Generated Data Actually Leaks treats synthetic data as a governed artifact, not a free replacement for reality.
- The safe use depends on the cell: training, evaluation, red-team, demo, privacy, or lineage all need different gates.
- Generated data earns its keep only when a real anchor, verifier, and owner survive after generation.
**Working claim: ** "Synthetic data is private" is the most over-trusted sentence in this field. Generated data is not automatically anonymous; a generator can reproduce the sensitive facts it was prompted with or trained on, and "synthetic" is a description of how the data was made, not a guarantee of what it does not contain. Privacy is a reason to be more careful, not a reason to relax.
The sentence that ends due diligence
There is a moment in many projects where someone says "we'll use synthetic data so we don't have privacy concerns, " and the room relaxes. The privacy review gets shortened, the legal sign-off gets waved through, the data handling controls get loosened, all on the strength of the word synthetic. That relaxation is the danger. The word describes provenance (a model made it), not content (it contains nothing sensitive), and the gap between those two is where real people's data leaks into systems that believe themselves clean.
The reject-set alarm from Chapter 7, pii_detected: 18, was a preview. Eighteen "synthetic" tickets contained real PII because the generation prompt fed real seed tickets to the model and the model echoed names, account numbers, and addresses back into its output. Those eighteen examples are synthetic by provenance and a privacy incident by content. Without the PII gate, they would have entered a dataset labeled "synthetic, no privacy concerns" and propagated everywhere that label opened a door.
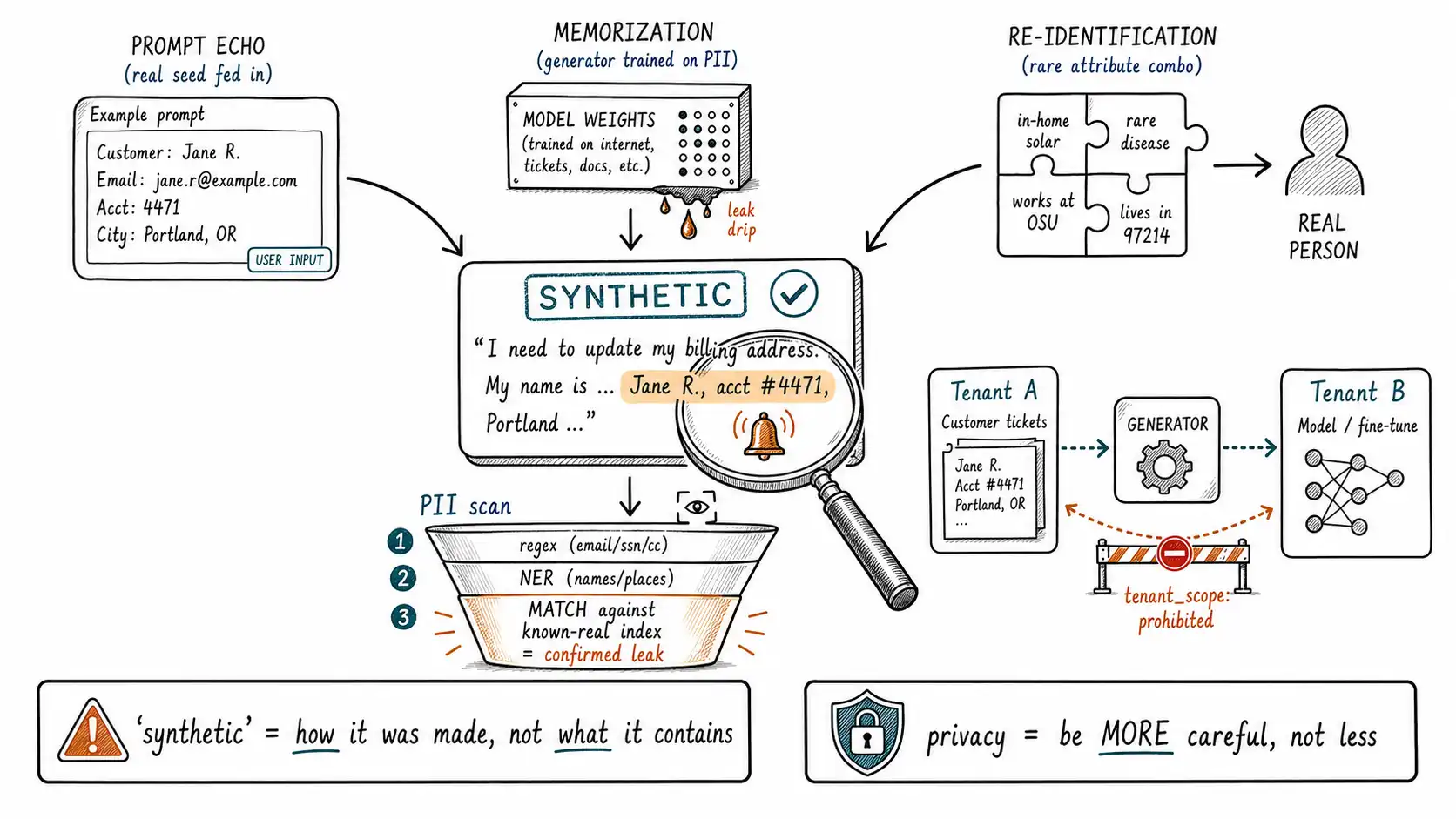
Three distinct ways generated data leaks
The privacy risks in synthetic data are not one risk; they are three mechanisms with different causes and different controls. Conflating them is part of how the myth survives.
**1. Prompt echo. ** The generator is given real sensitive data as a seed, few-shot example, or context, and reproduces it, verbatim or lightly transformed, in its output. This is the most common and most preventable leak. The fix is to never feed raw PII into a generation prompt, and to scan outputs regardless because models paraphrase identifiers in ways regex misses ("the customer in Portland whose order shipped late" can still be identifying).
**2. Memorization. ** The generator was trained on sensitive data and emits it without being prompted, because the model memorized it. This is not hypothetical. Extracting Training Data from Large Language Models demonstrated that large models can be made to regurgitate verbatim training examples including personal information, and The Secret Sharer showed earlier that models memorize and can leak rare sequences (like credit card or social security numbers) present even a handful of times in training. If you fine-tuned a generator on your customer data and then use it to "generate synthetic customers, " it can emit real ones. The synthetic label is actively misleading here, because the leak comes from the model's weights, not from your prompt (the same training-data-bleed dynamic the data-contamination survey tracks from the evaluation side).
**3. Inference / re-identification. ** The generated data contains no verbatim PII but preserves enough structure to re-identify individuals when combined with other data. A synthetic record that matches a real person on a rare combination of attributes (a specific job title in a small town with a specific rare condition) can be re-identifying even though every field was "generated." This is the membership-inference family of risks at a conceptual level: the question is not "is this exact person in the data" but "can this data reveal whether a person was in the source." Synthetic data reduces but does not eliminate this, and the reduction depends entirely on how the data was generated.
| Leak mechanism | Cause | Primary control |
|---|---|---|
| Prompt echo | Raw PII in the generation prompt | Redact seeds before generation; scan outputs |
| Memorization | Generator trained on sensitive data | Don't fine-tune generators on un-scrubbed PII; output scanning; treat as high-risk |
| Inference / re-identification | Generated structure preserves rare attribute combinations | k-anonymity-style checks on rare combinations; access control on outputs |
A PII scan that does not trust the word "synthetic"
Because the leak can come from prompt, weights, or structure, the only reliable control is to scan generated output as if it might contain real data, because it might. The scan runs as the early, safety-critical gate of Chapter 7, and its report format is part of the manifest.
import re
# Layer 1: deterministic detectors for structured identifiers.
PATTERNS = {
"email": re.compile(r"[\w.+-]+@[\w-]+\.[\w.-]+"),
"ssn": re.compile(r"\b\d{3}-\d{2}-\d{4}\b"),
"credit": re.compile(r"\b(?:\d[ -]*?){13,16}\b"),
"phone": re.compile(r"\b(?:\+?\d{1,2}[\s-]?)?\(?\d{3}\)?[\s-]?\d{3}[\s-]?\d{4}\b"),}
def scan_example(text: str, real_pii_index=None) -> dict:
findings = {k: p.findall(text) for k, p in PATTERNS.items()}
findings = {k: v for k, v in findings.items() if v}
# Layer 2: NER for names/orgs/locations (model paraphrases past regex).
findings_ner = ner_detect(text, types=["PERSON", "GPE", "ORG"])
# Layer 3: the critical check - does any token MATCH a known real identifier?
# This catches prompt echo and memorization that "looks synthetic".
matched_real = []
if real_pii_index is not None:
matched_real = [tok for tok in extract_candidates(text)
if real_pii_index.contains(tok)]
return {
"structured": findings,
"named_entities": findings_ner,
"matched_known_real_pii": matched_real, # ANY hit = confirmed leak, not maybe
"verdict": "BLOCK" if (findings or matched_real) else "review_ner",}
# Manifest PII report format:
# pii_scan:
# tool: pii-scan v2
# examples_scanned: 12480
# structured_findings: 0
# matched_known_real_pii: 18 <- the alarm: real customer data in "synthetic" output
# action: "18 quarantined; generation prompt redaction added; regenerated"Layer 3 is the one most teams skip and the one that closes the myth. Maintaining an index of known real identifiers from your source data and checking generated output against it converts "this looks synthetic" into "this contains a confirmed real identifier." That is how you catch prompt echo and memorization, which by definition produce output that looks synthetic because a model produced it. The 18-example alarm is a Layer-3 hit.
Tenant isolation: the leak that crosses customers
For multi-tenant systems, there is a privacy failure specific to synthetic data that the myth obscures entirely: **generating with one tenant's data and using the output for another tenant. ** A team builds a "synthetic data generator" seeded on aggregate customer data, generates examples to improve a shared model, and inadvertently moves tenant A's patterns, sometimes tenant A's actual facts, into a model serving tenant B. The data is synthetic, the leak is real, and the blast radius is a cross-customer confidentiality breach, which is among the most severe failures a B2B system can have.
The control is provenance plus access scope, which the NIST AI RMF frames as knowing your data's origin and governing its use, and which OWASP's sensitive-information-disclosure category names directly as a top LLM risk. Concretely: generation jobs must record which tenant's data seeded them (seed_source and a tenant_scope field), and a dataset seeded by one tenant's data must carry a prohibited_use that forbids training models serving other tenants, enforced by the same load-time check as Chapter 4. Synthetic does not dissolve tenant boundaries; it can quietly cross them if provenance does not track the seed's origin.
What "synthetic for privacy" can and cannot do
The chapter is not an argument that synthetic data is useless for privacy. Used carefully, it genuinely helps, it can reduce the volume of real PII flowing through systems, enable sharing of data shapes without sharing records, and limit exposure in demos and tests. The point is to state precisely what it does and does not buy you.
| Claim | Reality |
|---|---|
| "Synthetic data contains no real PII." | False by default. It contains whatever the prompt fed it or the weights memorized; only scanning and redaction make it true. |
| "Synthetic data eliminates re-identification risk." | False. Preserved rare attribute combinations can re-identify; reduction depends on generation method. |
| "Synthetic data needs no privacy review." | False, and dangerous. It needs review for the three leak mechanisms, which collected data does not. |
| "Synthetic data can reduce PII exposure in tests/demos." | True, if generated without real seeds and scanned, a real and good use. |
| "Synthetic data can let us share data shapes without records." | True, with re-identification checks on rare combinations. |
The two "true" rows are the legitimate privacy uses, and they share a precondition: the generation did not ingest raw sensitive data and the output was scanned. The three "false" rows are the myth. The careful framing, privacy is a reason to be more careful, not less, flows directly from this table: the very fact that you reached for synthetic data because of a privacy concern means the source data is sensitive, which means the prompt-echo and memorization risks are elevated, not eliminated. You are generating from exactly the kind of data that leaks.
Retention, deletion, and the right to be forgotten
A final privacy obligation the myth obscures: erasure. When a real person requests deletion of their data, you must be able to honor it, and if their data seeded a generation job, the synthetic outputs that echoed or memorized their information are also their data. This is impossible without the provenance of Chapter 3: seed_example_id and seed_source are what let you trace from a deletion request back to the generated examples that ingested that person's data, so you can delete or regenerate them. A team that cannot answer "which synthetic examples were seeded by this customer's data" cannot honor an erasure request, which is a compliance failure dressed as a data-engineering gap. The synthetic dataset's manifest must therefore record its seed lineage well enough to support deletion, and the retention policy must include synthetic outputs derived from real data, not just the real data itself.
Chapter summary
"Synthetic data is private" is the field's most over-trusted sentence; the word describes how the data was made, not what it contains, and the relaxation it triggers is the danger. Generated data leaks through three distinct mechanisms: prompt echo (raw PII fed into the generation prompt and reproduced), memorization (a generator trained on sensitive data emitting it unprompted, demonstrated by the training-data-extraction and Secret Sharer work), and inference/re-identification (generated structure preserving rare attribute combinations). The only reliable control is to scan generated output as if it might contain real data, with a three-layer scan whose critical Layer 3 matches output against an index of known real identifiers, converting "looks synthetic" into "confirmed real PII", the source of Chapter 7's 18-example alarm. Multi-tenant systems face a synthetic-specific leak: generating with one tenant's data and using it for another, controlled only by recording seed origin and enforcing a tenant-scoped prohibited-use. Synthetic data does have legitimate privacy uses, reducing PII exposure in tests and sharing data shapes, but only when generated without raw sensitive seeds and scanned; the reason you reached for it (sensitive source data) is precisely what elevates the leak risk. Finally, erasure obligations extend to synthetic outputs seeded by a person's data, which is impossible to honor without the seed-lineage provenance of Chapter 3.