Judges Disagree, and That Is the Useful Part
> **Working claim: ** Using a model to judge generated data is convenient and necessary at scale, but a single LLM judge is a single fingerprinted opinion wearing the costume of measurement.

Key Takeaways
- Judges Disagree, and That Is the Useful Part treats synthetic data as a governed artifact, not a free replacement for reality.
- The safe use depends on the cell: training, evaluation, red-team, demo, privacy, or lineage all need different gates.
- Generated data earns its keep only when a real anchor, verifier, and owner survive after generation.
**Working claim: ** Using a model to judge generated data is convenient and necessary at scale, but a single LLM judge is a single fingerprinted opinion wearing the costume of measurement. The signal you actually want is disagreement, between judges, and between judges and humans, because disagreement is where the dataset's real uncertainty lives and where human review should be spent.
The seductive shortcut
The previous chapter's gates included automated checks, and the most tempting of all is "let a strong model judge the generated examples." It scales beautifully: a judge model can score ten thousand examples for a few dollars while a human can review a few hundred a day. LLM-as-judge is now a standard pattern, and it is genuinely useful. It is also where careful teams quietly reintroduce the exact problem this book is about, because **a judge is a generator pointed at a different task, and it carries the same kind of fingerprints. **
When you generate data with model A and judge it with model A (or its sibling), you have built a closed loop: the generator's blind spots are precisely the blind spots the judge shares, so the judge approves the generator's worst habits and the loop certifies itself. The model chasing its own test generator, from the book prompt's image, is real, and a single LLM judge is one of the main ways teams build it without noticing. The fix is not to abandon model judges, at scale you cannot, but to treat any single judge as one opinion and to mine disagreement for the truth a single opinion hides.
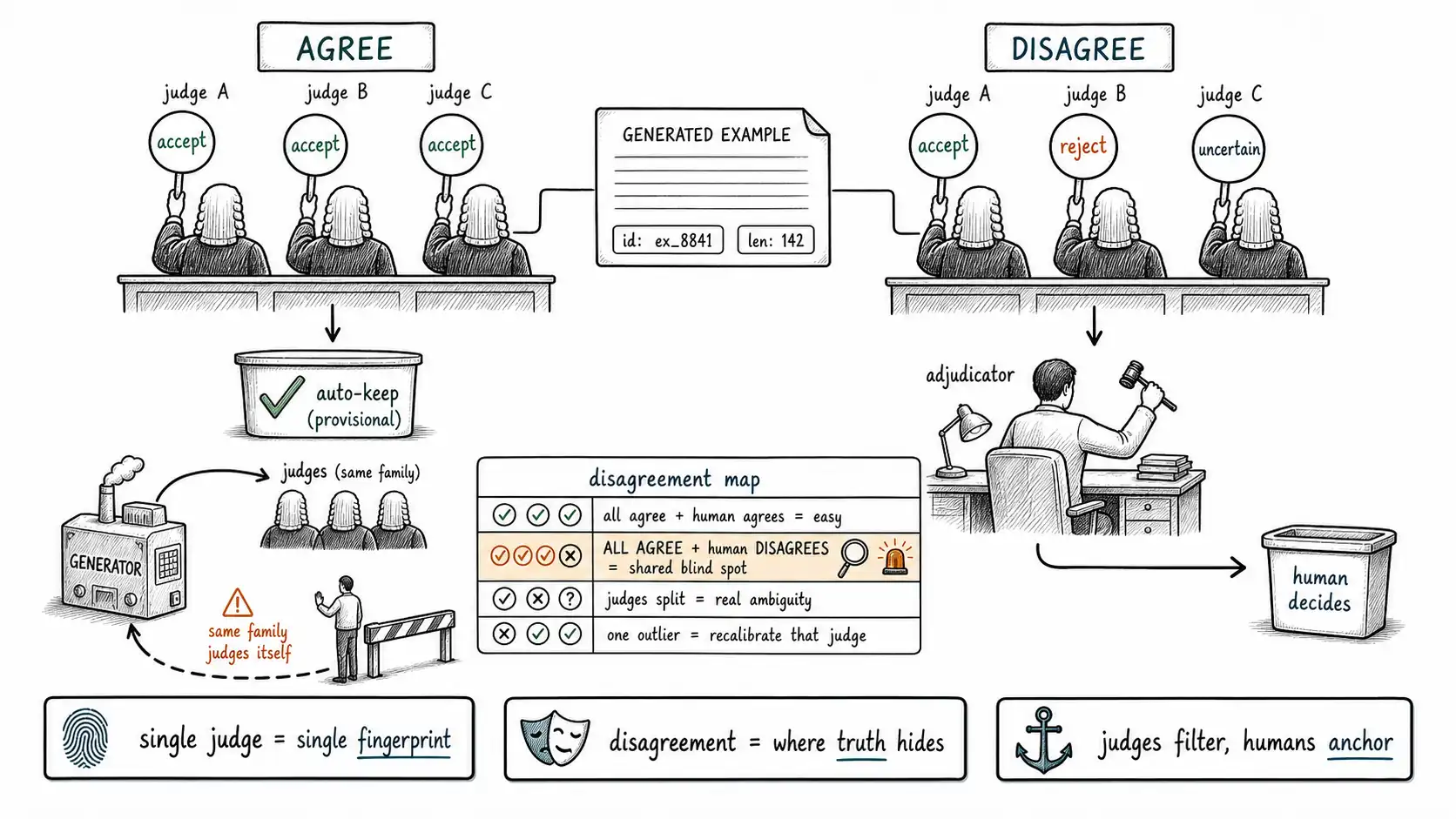
Why a single judge is a single fingerprint
It helps to be precise about what an LLM judge actually does. Asked "is this generated GDPR ticket realistic and correctly labeled?", the judge does not measure realism against the real distribution; it produces its model's opinion of realism, shaped by its training and your rubric prompt. That opinion has systematic tendencies: judges tend to prefer longer, more fluent, more confident answers; they exhibit position and verbosity biases; they reward outputs that look like their own generations. The InstructGPT line is instructive here in the other direction, it anchored alignment in human preference labels precisely because human judgment, with all its noise, was the reality signal; the model was the thing being judged, not the judge.
So a single-judge approval is not a measurement of quality. It is a correlated second opinion from the same family that produced the data. The TruthfulQA work is a sharp reminder of how this fails: models confidently assert common misconceptions, and a judge from the same lineage will happily approve a generated example that repeats a popular falsehood, because the falsehood is exactly what both models learned. If your only gate on truthfulness is a model judge, you launder the misconception into your dataset and call it verified.
Disagreement as the primary signal
The useful reframe: stop asking "did the judge approve?" and start asking "where do judges disagree?" Run multiple judges, different model families, different prompts, ideally including a human on a sample, and the agreement structure tells you far more than any single verdict.
from dataclasses import dataclass
from statistics import mode
@dataclass
class Verdicts:
example_id: str
judge_a: str # e.g."accept" / "reject" / "uncertain"
judge_b: str
judge_c: str
human: str | None = None
def disposition(v: Verdicts) -> str:
model_votes = [v.judge_a, v.judge_b, v.judge_c]
agree = len(set(model_votes)) == 1
if v.human is not None:
# Human is the anchor; record judge-vs-human for calibration.
return v.human # human decides, judges are advisory
if agree:
return model_votes[0] # unanimous models -> provisional auto-decision
return "needs_human" # ANY disagreement -> route to a personThe rule is simple and powerful: **unanimous model judges can make a provisional automatic decision; any disagreement routes to a human. ** This concentrates scarce human review exactly where it has the most value, the examples the models cannot agree on, which are, almost by definition, the genuinely ambiguous or borderline cases. It is the opposite of the naive pattern (trust the single judge everywhere); it is also far cheaper than reviewing everything, because most examples are easy and the judges agree on them.
A judge-disagreement analysis
The disagreement structure itself is a dataset you should analyze, because it diagnoses both your data and your judges. A disagreement table over the human-reviewed sample looks like this:
| Pattern | judge_a | judge_b | judge_c | human | n | What it means |
|---|---|---|---|---|---|---|
| All agree, human agrees | accept | accept | accept | accept | 612 | Easy cases; judges are reliable here |
| All agree, human DISAGREES | accept | accept | accept | reject | 47 | Shared blind spot, judges' common fingerprint; investigate |
| Judges split, human decides | accept | reject | uncertain | reject | 133 | Genuine ambiguity; human time well spent |
| One judge outlier | accept | accept | reject | accept | 58 | judge_c is mis-calibrated for this task |
The most important row is the second: 47 cases where all three model judges agreed and a human overruled all of them. That is a shared blind spot, a region where the judges' common fingerprints make them confidently, uniformly wrong. These cases are gold, because they reveal a systematic error your automated gates will never catch, since the judges that constitute those gates all share it. The TruthfulQA-style misconception lives exactly here: every model approves it, and only a human catches it.
The fourth row diagnoses your judges rather than your data: judge_c is an outlier, which means either it is mis-calibrated for this task (drop it or re-prompt it) or it is catching something the others miss (investigate before dropping). Either way, you learned it from the disagreement structure, not from any single verdict.
Sampling for human review
Human review is the anchor, CAREFUL's A applied to the filtering stage, and it is scarce, so how you sample matters. Reviewing a uniform random sample wastes most of the budget on easy cases the judges already nailed. A better allocation is stratified by disagreement and uncertainty:
def build_review_queue(examples, budget: int) -> list:
"""Spend human budget where it buys the most information."""
disagreed = [e for e in examples if e.disposition == "needs_human"]
# Of the auto-decided ones, sample some to CALIBRATE the judges:
auto_decided = [e for e in examples if e.disposition!= "needs_human"]
calibration = stratified_sample(auto_decided, frac=0.05) # spot-check the "easy"
queue = disagreed + calibration
# If still over budget, prioritize by (a) judge entropy, (b) novelty region (Ch.6)
queue.sort(key=lambda e: (e.judge_entropy, e.semantic_novelty), reverse=True)
return queue[:budget]Two things are happening. All disagreement cases go to humans, because that is where the value is. And a small calibration sample of the auto-decided cases also goes to humans, this is how you discover the "all judges agree, human disagrees" shared-blind-spot row. Without spot-checking the easy cases, you would never learn that your judges have a correlated error, and you would ship it. The OpenAI evals guide describes this division of labor explicitly: automated graders handle the volume, humans handle the judgment and the calibration of the automated graders themselves.
Judges are filters, not oracles: the recurring rule
Everything in this chapter rests on one rule the book keeps restating because it keeps getting violated: **model judges are filters that reduce risk, not oracles that certify truth. ** The consistency-based checks of SelfCheckGPT and the reference-free metrics of RAGAS are exactly this, useful, scalable, model-based triage that flags likely problems for human attention. They are not certifications. A RAGAS faithfulness score tells you a generated answer is probably grounded in its context; it does not tell you the context was correct or the answer true. A high SelfCheckGPT consistency tells you the model is confident and stable; a confident, stable model can be consistently wrong, which is the TruthfulQA failure exactly.
This is why the human anchor never fully disappears, no matter how good the judges get. The judges scale the review; the humans calibrate the judges and catch the shared blind spots; and the disagreement between them is the signal that tells you where each is needed. A pipeline that uses model judges and a calibrated human sample and analyzes the disagreement between them is doing real measurement. A pipeline that trusts a single judge is doing the Chapter 1 failure with extra steps and a veneer of rigor.
What enters the dataset
Tying it to the gate cascade of Chapter 7, here is how judge output combines with the prior gates to decide inclusion:
- An example clears the deterministic and dedup gates (Chapter 7).
- Multiple model judges score it. Unanimous accept → provisional keep. Any disagreement → human queue.
- A calibration sample of provisional keeps also goes to the human queue.
- Human verdicts override model verdicts and are recorded as the
reviewer_label(which feeds the label-accuracy metric of Chapter 6). - The judge-vs-human disagreement table is regenerated; shared-blind-spot cases (all-agree, human-disagrees) trigger a generation or judge-prompt fix.
- Everything rejected, by judges or humans, goes to the reject set with its reason.
The dataset that emerges is one where the easy majority was efficiently auto-decided, the ambiguous minority was human-decided, the judges were continuously calibrated against humans, and the systematic errors the judges share were surfaced rather than silently approved. That is the most you can ask of filtering, and it is far more than a single judge can deliver.
Chapter summary
LLM-as-judge scales filtering, but a single judge is a generator pointed at a different task and carries the same fingerprints; judging model A's output with model A builds a self-certifying closed loop where shared blind spots get approved, the model chasing its own test generator. A judge's approval is a correlated second opinion, not a measurement, and the TruthfulQA phenomenon shows the danger: same-lineage models approve each other's popular misconceptions. The reframe is to mine disagreement: run multiple judges, let unanimous judges make a provisional automatic decision, and route any disagreement to a human. A judge-disagreement table diagnoses both data and judges, the critical "all judges agree, human disagrees" row reveals shared blind spots that automated gates can never catch, while an outlier judge reveals a mis-calibrated grader. Human review is the scarce anchor, so it is sampled by disagreement and uncertainty plus a small calibration sample of auto-decided cases (the only way to discover shared blind spots). The recurring rule holds: SelfCheckGPT consistency and RAGAS faithfulness are model-based filters that reduce risk, not oracles that certify truth, which is why a calibrated human anchor never fully disappears and why disagreement analysis, not single-judge approval, is real measurement.