Playbooks I: Classification, Extraction, and Safety Red-Teaming
> **Working claim: ** The general principles become useful only when they collapse into specific recipes.

Key Takeaways
- Playbooks I: Classification, Extraction, and Safety Red-Teaming treats synthetic data as a governed artifact, not a free replacement for reality.
- The safe use depends on the cell: training, evaluation, red-team, demo, privacy, or lineage all need different gates.
- Generated data earns its keep only when a real anchor, verifier, and owner survive after generation.
**Working claim: ** The general principles become useful only when they collapse into specific recipes. Each task has a different answer to the same six questions, what synthetic data helps, what it cannot replace, how to generate it, what to filter, how much human review, how to evaluate, and how it fails, and the answers are not interchangeable across tasks.
How to read a playbook
The previous thirteen chapters built a toolkit. The last three spend it. Each playbook answers the same seven questions, so they are comparable, but the answers differ sharply by task, which is the point. A recipe that works for classification will quietly ruin a safety eval. The seven questions, fixed across every playbook:
- **Helps with: ** the specific gap generation can fill.
- **Cannot replace: ** the reality that must stay in the loop.
- Generation design, how to generate, and toward what target.
- **Required filters: ** the gates that are non-negotiable for this task.
- Human review level, how much, and on what.
- Eval strategy, how to measure without contaminating.
- **Failure risks: ** the specific ways this task goes wrong.
This chapter covers the three tasks where the toolkit is most often misapplied: classification (the Chapter 1 task, done right), document extraction, and safety red-teaming.
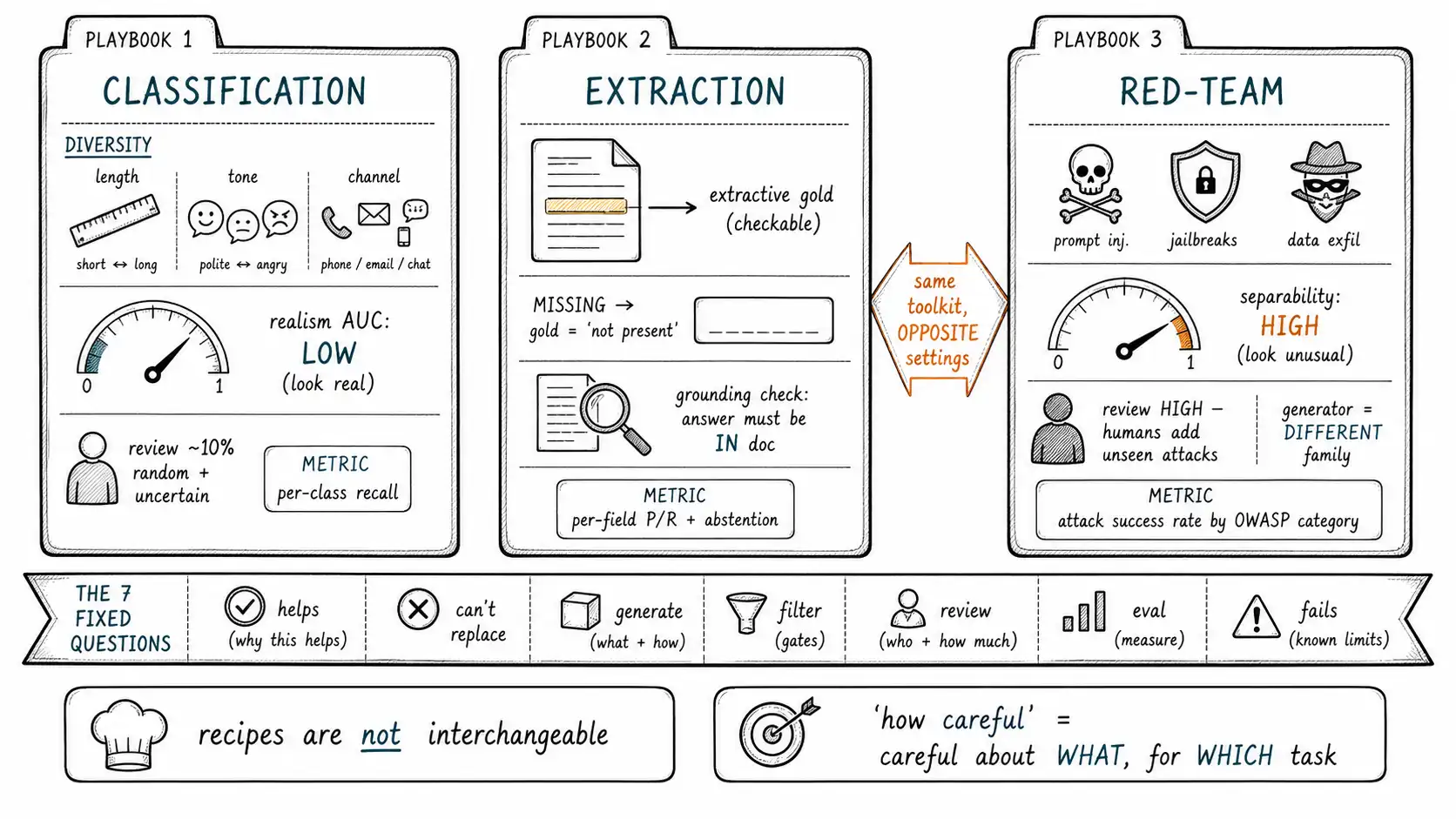
Playbook: Intent / Text Classification
The canonical synthetic-data task, and the one the book opened with. Done right, generation genuinely helps; done as Chapter 1 did it, it produces the polished-ticket failure.
- **Helps with: ** Minority-class augmentation, paraphrase robustness, and coverage of intents your logs under-represent. A few hundred synthetic examples of a rare intent, anchored to real ones, can lift minority-class recall.
- **Cannot replace: ** The real input distribution, its terseness, hostility, misspelling, and class balance. Generation cannot tell you the shape of reality; it can only fill in once you have characterized that shape.
- **Generation design: ** Simulate toward a measured target (Chapter 1). Force diversity along the axes that fail by default: length (include terse), tone (include hostile), channel (email/chat/phone), and difficulty (Chapter 6). Use real examples as few-shot seeds, but vary aggressively so you do not just paraphrase the seeds, the seed-then-diversify pattern Self-Instruct established.
- **Required filters: ** Exact + near-duplicate dedup; label-consistency check (the assumed-label failure is fatal here, verify the text supports the prompted intent); realism classifier with a low AUC target (you want synthetic to sit in the real distribution); difficulty histogram matched to real.
- **Human review level: ** Light but mandatory, a stratified sample plus all label-uncertain cases (Chapter 8). The reviewer confirms the label and flags style fingerprints. ~5-10% review is typical.
- **Eval strategy: ** Never evaluate on the synthetic data or on a split that shares its generator. Hold aside a real, human-labeled set including the rare intents and the hard tail; measure per-class recall, not aggregate accuracy.
- **Failure risks: ** Polished-ticket style monoculture; balanced counts with drifted labels; contaminated eval; flattened difficulty. The signature is offline-up, production-down on the rare slice.
classification_playbook = {
"max_synthetic_ratio": 0.50, # of the minority class, not overall
"force_diversity": ["length", "tone", "channel", "difficulty"],
"filters": ["exact_dedup", "near_dup", "label_consistency", "realism_low_auc"],
"eval": "real_human_labeled_holdout", # generator-isolated
"primary_metric": "per_class_recall", # NOT aggregate accuracy
}Playbook: Document Extraction
Pulling structured fields (dates, amounts, parties, clauses) from documents, invoices, contracts, forms. Synthetic documents are tempting because real ones are scarce, sensitive, and tedious to label. They are also where the "answer is too findable" trap bites hardest.
- **Helps with: ** Format and layout variation (the same field in different positions, formats, phrasings), edge cases in formatting (dates as
03/04/26vs.4 March 2026), and rare document types. Generation is good at surface variety of structure. - **Cannot replace: ** Real document chaos, scan artifacts, OCR noise, inconsistent layouts, multi-column mess, the field that is missing or stated three contradictory ways. Synthetic documents are too clean and the target field is too findable.
- **Generation design: ** Generate documents and their ground-truth extractions together, but anchor the extraction to a verifiable property: the field must be a literal span present in the document (extractive gold, Chapter 9), so the label is checkable, not generated prose. Deliberately inject the hard cases reality supplies: missing fields, contradictory statements, fields split across pages.
- **Required filters: ** Faithfulness/grounding check (RAGAS-style, Chapter 7), the extracted value must actually appear in the document; format validators on the structured output; near-duplicate dedup on document templates (generators reuse layouts heavily).
- **Human review level: ** Medium. A human verifies extractions on a sample and, critically, reviews the hard cases (missing/contradictory fields), because that is where the generator's "helpful" tendency to always find an answer produces wrong gold.
- **Eval strategy: ** Evaluate on real documents wherever any exist, even a small human-labeled set; synthetic documents may supplement for format coverage but cannot measure real-world extraction accuracy. Measure precision/recall per field, and specifically measure the abstention behavior on documents where the field is absent, synthetic-trained extractors notoriously hallucinate a value rather than report "not present."
- **Failure risks: ** Over-findable answers (the field is always cleanly present in synthetic docs, so the model never learns to handle absence); template monoculture; the contamination risk of synthetic eval documents leaking into training; hallucinated extractions on absent fields.
The abstention point is the one teams miss. A synthetic document where every field is present teaches the model that fields are always present, so on a real document missing a field, the model invents one. The fix is to generate documents with deliberately missing fields and gold extractions of "not present, " so absence is in the training distribution.
Playbook: Safety Red-Teaming
The task where generation's fabrication tendency is a feature, not a bug, you want adversarial inputs unlike normal traffic. But it is also the task where shared fingerprints between generator and target model are most dangerous, because a generator probing a sibling model tests only the attacks it can imagine.
- **Helps with: ** Scaling coverage of adversarial inputs: prompt injections, jailbreak attempts, harmful-request variations, edge-case policy violations, far beyond what a human red team can hand-write. Generation produces volume and variation of attack patterns.
- **Cannot replace: ** Human creativity and the attacks the generator cannot conceive. A generator from the same family as your target shares its blind spots, so it under-tests exactly the failures most likely to slip through. Real adversaries are creative in ways no model anticipates.
- **Generation design: ** Generate adversarial inputs (high separability from normal traffic is fine here, Chapter 7's realism caveat), but deliberately use a different model family from the one under test, and seed with real attack patterns from threat intelligence and prior incidents. The OWASP LLM Top 10 categories (prompt injection, insecure output handling, etc.) are a coverage checklist to generate against.
- **Required filters: ** De-duplication (generators produce many trivial variants of one attack); a coverage check against the OWASP categories (are all attack classes represented, or did the generator over-produce one easy class?); and a check that the "expected safe behavior" gold is human-defined, not generated.
- **Human review level: ** **High. ** Red-teaming is where human judgment is least replaceable. Humans define what counts as a successful attack, review the novel attack regions (Chapter 6's semantic novelty), and, most importantly, add the attacks the generator could not imagine. Treat generation as a force multiplier on human red-teamers, not a replacement.
- **Eval strategy: ** The "gold" is the policy, the defined safe behavior, which must be human-authored, never generated (a generated definition of "safe" is the TruthfulQA trap: the generator may share the unsafe assumption). Measure attack success rate by category; track which attack classes the model fails on. Keep red-team eval sets isolated from any safety training data (Chapter 9), or you train to your own test.
- **Failure risks: ** Sanitized attacks that don't probe real failures; coverage gaps the generator can't imagine; same-family blind spots; and the contamination failure of training safety behavior on the same generated attacks you evaluate with, which produces a model that passes your red-team and fails a real one.
red_team_playbook = {
"generator": "DIFFERENT_family_from_target", # avoid shared blind spots
"seed_with": ["real_incidents", "threat_intel", "OWASP_categories"],
"realism_target": "high_separability_is_FINE", # opposite of classification!"human_review": "HIGH - humans add attacks the generator cannot imagine",
"gold_definition": "human_authored_policy", # never generated
"eval_isolation": "red_team_eval NEVER shares data with safety training",}Note the deliberate contrast between this playbook and classification. Classification wants low realism AUC (synthetic should look real) and light human review; red-teaming wants high separability (attacks should look unusual) and heavy human review. The same toolkit, opposite settings, which is exactly why the playbooks cannot be interchanged and why "how careful?" always resolves to "careful about what, for which task?"
Chapter summary
Principles become useful as task-specific recipes, and each playbook answers the same seven questions, helps with, cannot replace, generation design, required filters, human review level, eval strategy, failure risks, with sharply different answers. Classification (the Chapter 1 task done right) uses generation for minority-class and paraphrase coverage, simulating toward a measured target with forced length/tone/channel/difficulty diversity, a mandatory label-consistency check, a low realism-AUC target, light human review, and evaluation strictly on a generator-isolated real human-labeled holdout measured by per-class recall. Document extraction uses generation for format and layout variety but cannot replace real document chaos; it anchors gold to verifiable extractive spans, deliberately injects missing and contradictory fields so the model learns abstention, applies faithfulness/grounding filters, and measures per-field precision/recall plus abstention on absent fields: the trap is over-findable answers that teach the model fields are always present. Safety red-teaming inverts the classification settings: fabrication is a feature, high separability is fine, the generator should be a different family to avoid shared blind spots, the safe-behavior gold must be human-authored (never generated, per the TruthfulQA trap), human review is heavy because humans add the attacks the generator cannot imagine, and red-team eval data must never share with safety training. The deliberate contrast, classification wants low AUC and light review, red-teaming wants high separability and heavy review, proves the playbooks are not interchangeable and that "how careful?" always resolves to "careful about what, for which task?"