The Polished-Ticket Problem
> **Working claim: ** Generated data can fix a small, well-defined coverage gap, but it cannot stand in for the real distribution.

Key Takeaways
- The Polished-Ticket Problem treats synthetic data as a governed artifact, not a free replacement for reality.
- The safe use depends on the cell: training, evaluation, red-team, demo, privacy, or lineage all need different gates.
- Generated data earns its keep only when a real anchor, verifier, and owner survive after generation.
**Working claim: ** Generated data can fix a small, well-defined coverage gap, but it cannot stand in for the real distribution. When a team replaces reality with a generator, the model learns the generator's writing style instead of the customer's, and offline accuracy rises while production accuracy quietly falls.
An incident, reconstructed
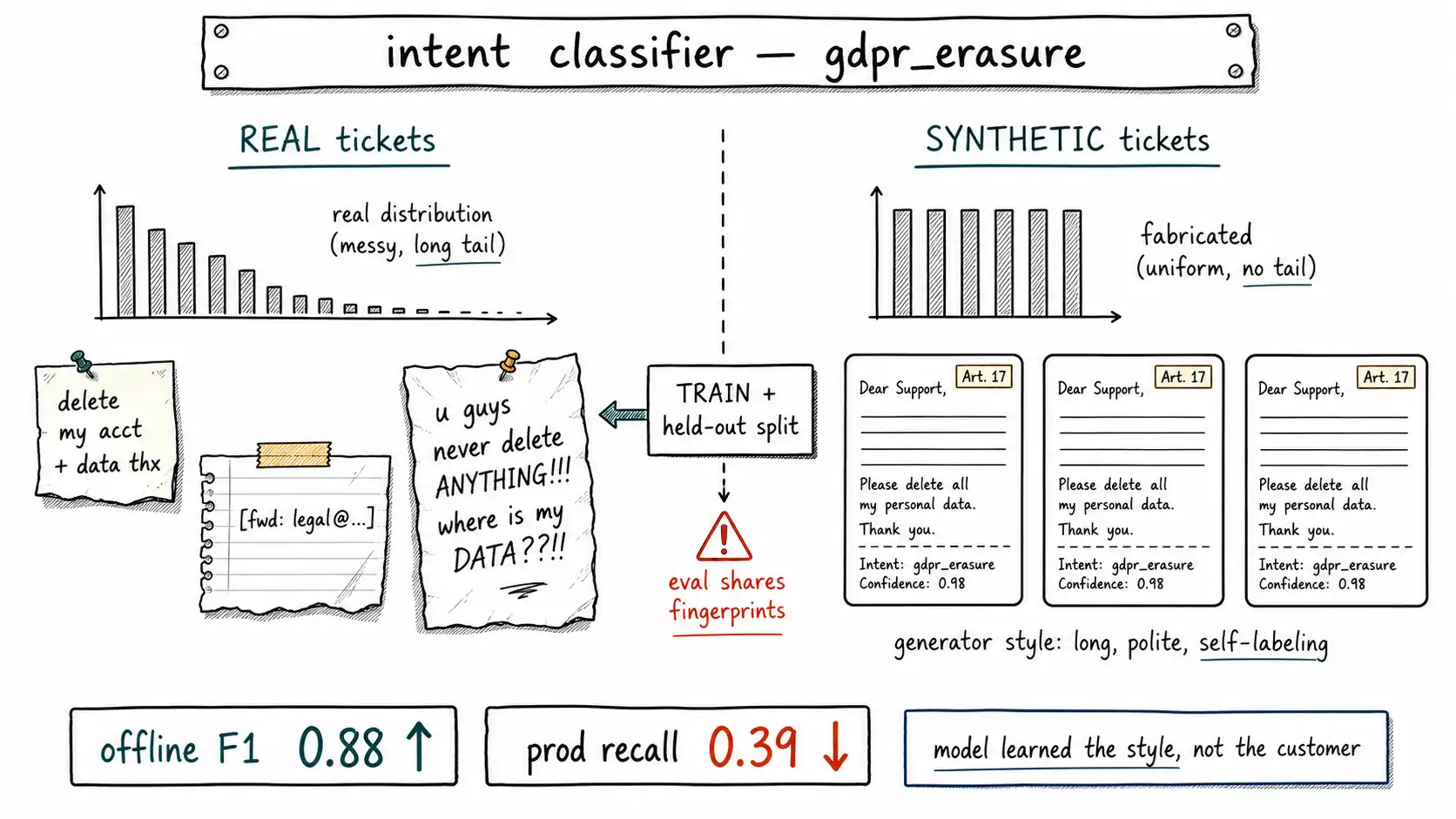
A B2B support team had a real problem and a reasonable plan. They were building an intent classifier for inbound tickets, twelve intents like billing_dispute, password_reset, feature_request, cancel_account, integration_broken. They had about 1,800 labeled tickets, scraped from a year of support history and hand-labeled by two agents. Twelve hundred of those tickets were three intents. The other nine intents shared six hundred examples, and two of them, data_export_request and gdpr_erasure, had fewer than forty each. The classifier they trained was excellent at the common intents and useless at the rare ones, which were exactly the intents that mattered most because they triggered compliance workflows.
So they did the obvious modern thing. They wrote a prompt: "Generate a realistic customer support ticket requesting GDPR data erasure. Vary the tone and the details." They ran it a few thousand times across the thin intents, labeled each generated ticket with the intent it was generated for (the label was free: they had asked for that intent), and added the synthetic tickets to the training set. They held out a test set, retrained, and watched the macro-F1 on the rare intents climb from 0.51 to 0.88. The minority classes were no longer minority classes. Everyone agreed the data problem was solved, and they shipped.
In production, the rare-intent recall was 0.39.
The offline number was not a lie, exactly. It was an answer to the wrong question. The held-out test set had been carved from the same pool, partly real, increasingly synthetic, so the classifier was tested on tickets that looked like its training data, and it had indeed learned to classify tickets that look like that. The trouble was that real GDPR erasure requests do not look like that. A real one reads: "delete my account and all my data thx." Or it is three lines forwarded from a legal address with a subject line and no body. The synthetic ones read like this:
"Hello, I hope this message finds you well. In accordance with my rights under the General Data Protection Regulation, specifically Article 17, I am writing to formally request the complete erasure of all personal data your organization holds pertaining to my account. Please confirm receipt of this request and advise on the expected timeline for completion."
Every synthetic ticket was polished, balanced, well-punctuated, and helpfully self-explanatory, it practically announced its own intent. The model learned that gdpr_erasure means "a long, courteous, regulation-citing paragraph." The terse real request, the angry one, the misspelled one, the one routed through a legal forwarder, those landed in feature_request or cancel_account, because nothing in training looked like them. The generator had a writing style, and the classifier learned the style, not the customer.
This is the polished-ticket problem, and it is the whole book in miniature. The synthetic data was not fake. It was a faithful reflection of a model asked to imagine a GDPR request. The fingerprints, fluency, length, helpful self-labeling, the suppression of mess, were the generator's, not the world's, and nobody measured them before training on them.
What actually went wrong, in lifecycle terms
It is tempting to summarize the failure as "synthetic data is bad." That is the wrong lesson and it will lead you to the opposite, equally expensive mistake. Walk it through the lifecycle instead.
| Lifecycle stage | What the team did | The defect |
|---|---|---|
| Purpose | Fill thin minority classes | Sound, this is a legitimate use of generation |
| Generation | One prompt per intent, default sampling | No diversity control; the generator's register dominated |
| Filtering | None | No dedup, no realism check, no style audit |
| Labeling | Label = the intent prompted for | Labels were assumed, never verified against the text |
| Evaluation | Held-out split from the mixed pool | Eval contaminated by synthetic style; not anchored to reality |
| Training | Mixed synthetic into the train set freely | No ratio policy, no anchor to real tail examples |
| Monitoring | Watched offline F1 | No production slice for rare intents until the incident |
Two defects are fatal on their own. The evaluation defect, testing on data that shares the generator's fingerprints, is why the team had no warning. The anchor defect, no held-aside set of real rare tickets to measure against, is why "improvement" was unfalsifiable. Everything else (no filtering, assumed labels, no ratio) made the failure larger, but those two made it invisible. We will spend whole chapters on each: evaluation isolation in Chapter 9, anchoring and ratios in Chapter 11.
The distinction the team collapsed: simulation vs. fabrication
There is a clean line between two things generation can do, and the team crossed it without noticing.
Simulation produces examples that are plausibly drawn from the real distribution, including its mess. A good simulated GDPR ticket would sometimes be three rude words, sometimes a legal forward, sometimes a misspelled plea, in roughly the proportions reality produces them. Simulation tries to match a distribution you have characterized.
Fabrication produces examples that are plausible in isolation but reflect the generator's defaults rather than any measured distribution. A fabricated GDPR ticket is what a helpful model thinks such a ticket "should" look like: complete, courteous, regulation-aware. Fabrication tries to satisfy a prompt.
Both are legitimate; they answer different questions. Fabrication is fine for "show me what a clear example of intent X looks like", useful for documentation, onboarding, or seeding a labeling guideline. Simulation is what you need if the generated data is going to train or evaluate a model that faces reality. The team used fabrication and treated it as simulation. The fix is not to stop generating. The fix is to know which one you are doing and to anchor simulation to a measured target.
Why generation works when it works
To keep this chapter honest, look at the wins, because they are real and they are instructive. Generated and model-curated data has produced some of the most striking results in recent practice, and the pattern in the successes is consistent: the generation was targeted, filtered, and anchored, not a wholesale replacement for reality.
Self-Instruct bootstrapped instruction-following data by having a model generate new instructions from a small human-written seed set, then filtered aggressively, removing instructions too similar to existing ones, ones the model couldn't produce a valid instance for, and near-duplicates. The diversity and filtering were the point, not the raw generation. Stanford Alpaca applied the same recipe to produce 52,000 instruction-following demonstrations from a stronger teacher model, explicitly as a low-cost academic artifact, and the authors were careful to flag its limitations rather than present it as ground truth.
Textbooks Are All You Need and the later Phi-3 report pushed further, arguing that data quality, heavily filtered web data plus carefully generated "textbook-quality" synthetic examples, could train small models that punch far above their parameter count. This is the strongest pro-synthetic evidence in the field, and it is worth stating precisely what it shows and does not. It shows that generation, when treated as a curation and quality problem with serious filtering, can substitute for raw scale. It does not show that you can prompt a model for a topic, train on the output unfiltered, and expect reality to follow. The Phi line's results came with enormous effort spent on what to exclude.
On the other side, the Nature model-collapse work demonstrates the cost of the naive version: train recursively on a model's own unfiltered output and the distribution's tails disappear first, the model converges toward its own mean, and rare-but-real cases vanish. That is the polished-ticket problem run for several generations: exactly the same mechanism, just compounded. We treat collapse carefully in Chapter 10; here it is enough to note that the support team's single round of unfiltered, unanchored generation was generation-one of the same process.
A small worksheet before you generate anything
The support team would have caught most of this with a five-question worksheet, filled in before writing a generation prompt. It is the operational form of CAREFUL's first two letters: Clear purpose and Anchored reality.
why_are_we_generating:
gap_described: "rare intents gdpr_erasure, data_export_request have <40 real examples"
why_real_data_wont_do: "low volume; compliance intents are rare by nature"
what_generation_adds: "more examples of these intents"
anchored_reality:
real_examples_held_aside: 38 # the few real rare tickets, NEVER generated over
real_distribution_characterized: false # <-- RED FLAG: we never looked at real style/length
target_to_match: "unknown" # <-- RED FLAG: simulating toward nothing
success_criterion:
measured_on: "held-out split of mixed pool" # <-- RED FLAG: not anchored to real
should_be: "recall on REAL rare tickets, held aside, never trained on"
failure_if_wrong:
blast_radius: "compliance workflows misrouted; legal exposure"
reversible: "retrain, but damage to trust already done"Three red flags in one worksheet. The team never characterized the real distribution they were trying to match, so they were fabricating toward an imagined ideal rather than simulating toward a measured target. They measured success on a contaminated split. And the failure was high-blast-radius and tied to compliance, which should have raised the bar for evidence, not lowered it. None of these flags require a model to find. They require ten minutes and the discipline to ask "anchored to what?" before "generate how many?"
The reflex this chapter is trying to install
When a team hits a data wall, the instinctive question is "can we generate more?" The answer is almost always yes, generation is cheap, which is exactly why the question is useless. The useful questions are the ones the polished-ticket team skipped:
- What real distribution are we trying to match, and have we actually characterized it (length, tone, mess, class balance)?
- What real examples are we holding aside, untouched by generation, to measure against?
- Are we simulating toward that target, or fabricating toward the generator's defaults?
- Is our evaluation isolated from the generator's fingerprints, or does it share them?
A team that answers these can use synthetic data as a microscope on a specific gap. A team that skips them uses it as a mirror and mistakes the reflection for the room.
Chapter summary
A support team with too few examples of rare, compliance-critical intents generated thousands of synthetic tickets, watched offline macro-F1 climb from 0.51 to 0.88, and shipped, then discovered production recall on those intents was 0.39. The synthetic tickets were not fake; they were a faithful reflection of a model asked to imagine the intent, and they carried the generator's fingerprints: fluent, balanced, over-explaining, self-labeling. The classifier learned that style instead of the customer's terse, messy, real distribution. Two defects made the failure invisible: the evaluation split shared the generator's fingerprints, and no real rare examples were held aside as an anchor. The deeper error was confusing fabrication (satisfying a prompt) with simulation (matching a measured distribution). The successes in the literature, Self-Instruct, Alpaca, the Phi/Textbooks line, succeeded precisely because generation was targeted, heavily filtered, and anchored; the naive version is generation-one of model collapse. The reflex to install is to replace "can we generate more?" with "what reality anchors this, and what breaks if we are wrong?"