Model Collapse, Honestly
> **Working claim: ** Model collapse is real, mechanistically specific, and frequently misquoted.

Key Takeaways
- Model Collapse, Honestly treats synthetic data as a governed artifact, not a free replacement for reality.
- The safe use depends on the cell: training, evaluation, red-team, demo, privacy, or lineage all need different gates.
- Generated data earns its keep only when a real anchor, verifier, and owner survive after generation.
**Working claim: ** Model collapse is real, mechanistically specific, and frequently misquoted. It is not "all synthetic data is bad." It is what happens when a model is trained recursively on its own unfiltered, unanchored output: rare events vanish first, variance shrinks, and the distribution converges toward the generator's mean. Understanding the actual mechanism is what lets you use synthetic data without triggering it.
The headline and the misquote
"Model collapse" had a moment. The Nature paper showing that models trained on recursively generated data degrade got compressed, in the retelling, into "synthetic data poisons models" and then into "never use synthetic data." Both retellings are wrong, and the wrongness is expensive in both directions: it scares careful teams away from legitimate uses, and it gives lazy critics a slogan that prevents them from understanding the actual risk.
So let us be precise about what the research shows and what it does not. The Curse of Recursion and the Nature follow-up demonstrate a specific process: take a model, generate data from it, train the next model on that generated data, generate from that model, and repeat, a closed recursive loop with no fresh real data entering. Across generations, the models degrade in a characteristic way. The tails of the distribution disappear first. Variance collapses. The model converges toward a narrow, high-probability core and forgets the rare, the diverse, and the improbable. After enough generations, the model produces low-variance nonsense that has lost most of what made the original distribution rich.
That is collapse. Note what it requires: recursion (model trained on model output, repeatedly), no anchor (no fresh real data re-entering the loop), and no filtering (the output is used as-is). Remove any one of those conditions and the dynamics change. This chapter is about understanding the mechanism well enough to know which of your practices are safe and which are generation-one of a collapse trajectory.
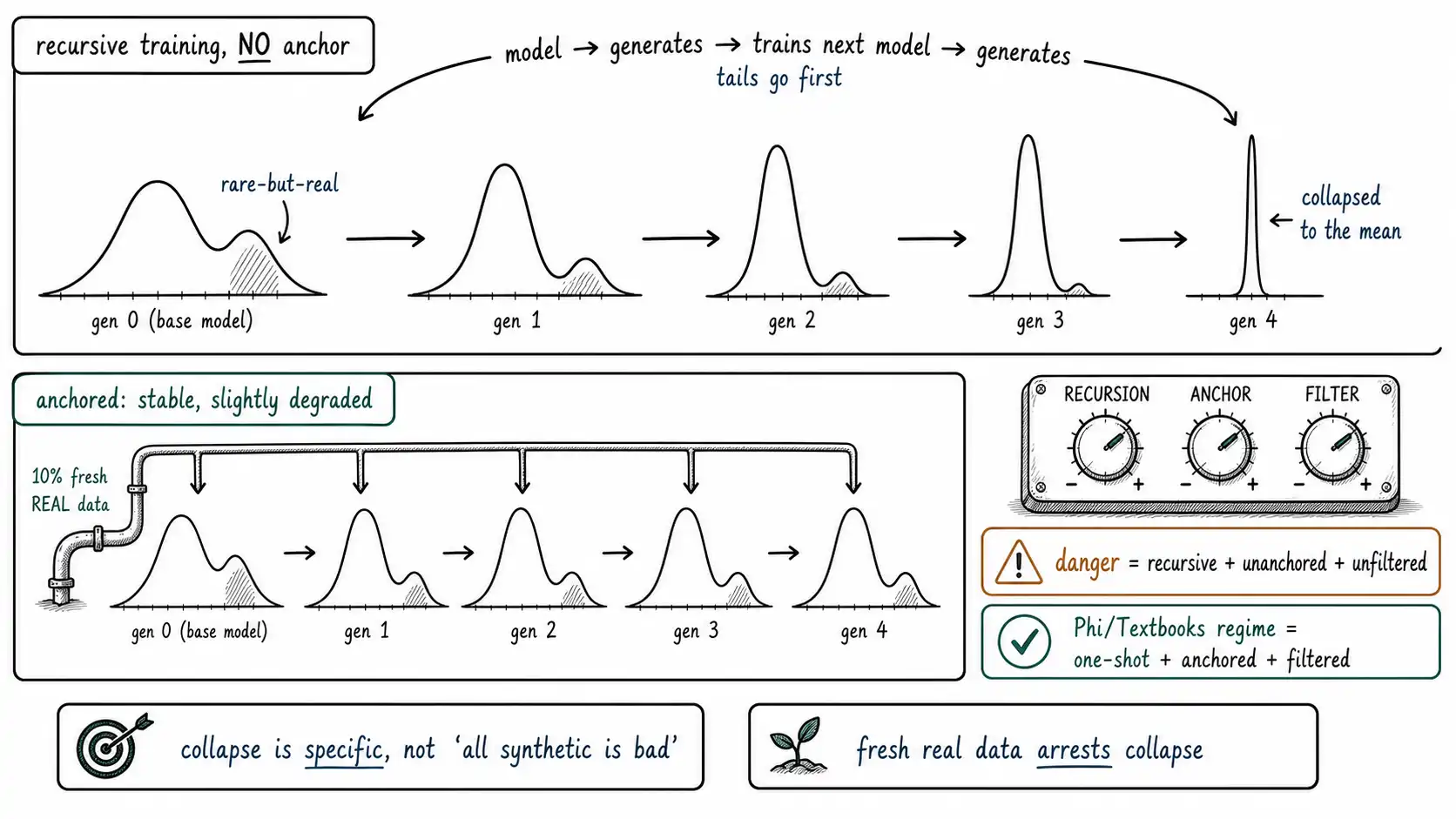
The mechanism: why tails go first
The intuition is statistical and worth internalizing because it generalizes far beyond the famous experiments. When a model generates samples, it samples from its learned distribution, and finite sampling under-represents low-probability events, that is just what sampling does. A tail event with probability 0.001 might not appear at all in ten thousand samples. So the generated data has fewer tail events than the distribution the model learned. Train the next model on that generated data, and it learns a distribution with even thinner tails, because it never saw the events the sampling dropped. Generate from it, and the tails thin again. The error compounds multiplicatively across generations.
Two distinct error sources drive it, and the research separates them:
- **Statistical approximation error: ** finite samples can't capture the full distribution, especially the tail. This alone shrinks tails even with a perfect model.
- **Functional approximation / model expressivity error: ** the model itself can't perfectly represent the distribution, adding its own systematic distortion each generation.
The combined effect is that the rare-but-real cases, exactly the ones you often generated synthetic data to cover in the first place, are the first casualties. This is the cruel irony the Chapter 1 team brushed against: they generated to cover a rare intent, and the generator, sampling from its own distribution, produced a flattened, central version of that rare intent, dropping precisely the rare-within-the-rare cases that mattered. One round of unfiltered, unanchored generation is generation-one of the collapse trajectory. The reason it did not look catastrophic is that they only ran it once. The reason it was still a failure is that even generation-one loses the tail.
A simulation you can run
Abstract claims about tail loss become visceral when you watch it happen. Here is a minimal simulation: a distribution with a fat tail, recursively re-estimated from finite samples across generations. It is not a neural network, it is the statistical core of collapse, stripped to its essence so the mechanism is undeniable.
import numpy as np
def recursive_resample(generations=8, n=5000, anchor_frac=0.0, seed=0):
"""Model a distribution, sample from it, re-fit, repeat.
anchor_frac: fraction of REAL data re-injected each generation.
Tracks how much of the rare tail survives."""
rng = np.random.default_rng(seed)
# Real distribution: a mixture with a heavy tail (rare large values).
def real_sample(k):
core = rng.normal(0, 1, int(k * 0.97))
tail = rng.normal(8, 1, k - len(core)) # the rare, important tail
return np.concatenate([core, tail])
real = real_sample(n)
current = real.copy()
tail_threshold = 5.0
history = []
for g in range(generations):
frac_tail = np.mean(current > tail_threshold)
history.append(frac_tail)
# Fit a (deliberately simple) model: a single Gaussian - limited expressivity.
mu, sigma = current.mean(), current.std()
gen = rng.normal(mu, sigma, n) # generate from the fitted model
if anchor_frac > 0: # re-inject real data as an anchor
keep = int(n * (1 - anchor_frac))
current = np.concatenate([gen[:keep], real_sample(n - keep)])
else:
current = gen # pure recursion, no anchor
return history
print("no anchor: ", [round(x, 4) for x in recursive_resample(anchor_frac=0.0)])
print("10% real anchor:", [round(x, 4) for x in recursive_resample(anchor_frac=0.10)])
# no anchor: [0.030, 0.001, 0.000, 0.000, 0.000, 0.000, 0.000, 0.000]
# 10% real anchor: [0.030, 0.012, 0.011, 0.010, 0.012, 0.011, 0.010, 0.011]The two output lines are the entire argument of the chapter. With no anchor, the rare tail (originally 3% of mass) is gone by generation two and never returns, the single-Gaussian model can't even represent the bimodal shape, so it collapses to the core immediately. With a 10% real anchor re-injected each generation, the tail stabilizes around 1% and persists indefinitely. The anchor does not perfectly preserve the tail, 10% real is not 100% real, but it stops the collapse, converting a death spiral into a stable, slightly-degraded equilibrium. This is the single most important operational result in the model-collapse literature: **fresh real data, re-injected, arrests collapse. ** Human data is the anchor, and the anchor is not optional.
What the Nature work does and does not let you conclude
It is worth stating the boundaries of the evidence carefully, because misquoting in the other direction, using collapse to ban synthetic data, is also a failure.
The collapse experiments use recursive, unfiltered, unanchored training. That is a specific and somewhat artificial regime. Real-world synthetic-data practice rarely matches it exactly: the Phi/Textbooks line (Textbooks Are All You Need) trained on heavily filtered synthetic data mixed with real data, ran one generation (not a recursive loop), and produced strong models. That is not a refutation of collapse; it is a demonstration that the conditions for collapse can be avoided. Filtering removes the worst generated samples (Chapter 7). Mixing with real data provides the anchor (the simulation above). Running one generation instead of recursing avoids the compounding. The Phi result and the collapse result are consistent: collapse is what happens when you violate those conditions, and the Phi line is what happens when you respect them.
There is also a live concern the contamination survey connects to: as more web text becomes model-generated, web-scale training corpora drift toward partially-synthetic without anyone choosing it, and that uncontrolled, unanchored accumulation is closer to the collapse regime than a deliberate, filtered, anchored synthetic-augmentation pipeline. The polluted-web-scale-training problem is real and is different from controlled synthetic augmentation, conflating the two is exactly the misquote this chapter exists to prevent. You control your augmentation pipeline. You do not control the web's drift, which is an argument for provenance (knowing what is real) and for valuing real data, not an argument against ever generating.
The practical taxonomy of collapse risk
Putting the mechanism to work, here is how to assess whether a given practice is near the collapse regime or far from it.
| Practice | Recursive? | Anchored? | Filtered? | Collapse risk |
|---|---|---|---|---|
| One-shot augmentation, filtered, mixed with real | No | Yes | Yes | Low, the Phi regime |
| Distill once from a stronger teacher, mixed with real | No | Yes (teacher ~ human-aligned) | Usually | Low-moderate |
| Train on this model's own output, no real data | Yes | No | No | High, the collapse regime |
| Iteratively self-improve over many rounds, unfiltered | Yes | No | No | High |
| Self-improve with fresh human data + filtering each round | Yes | Yes | Yes | Moderate, anchor and filters hold it |
| Train on scraped web that is increasingly model-generated | Effectively yes | Unknown | Weak | Rising, uncontrolled, provenance matters |
The three knobs, recursion, anchoring, filtering, predict the risk. The dangerous quadrant is recursive + unanchored + unfiltered. Every safe practice in the table neutralizes at least one knob, usually the anchor. This is why the rest of this movement is about ratios and monitoring: the anchor is not a one-time decision but a standing ratio you maintain and a drift you watch for, because collapse in production does not announce itself, the tail just quietly stops appearing.
The honest summary you can give a skeptic
When someone says "synthetic data causes model collapse, so we shouldn't use it, " the honest, precise response is this. Collapse is a real phenomenon with a specific cause: recursive training on a model's own unfiltered output with no fresh real data. It is driven by sampling under-representing tails and model error compounding across generations, and it kills the rare cases first. It is avoided by the practices this book has been building toward, filtering the generated data, anchoring it to real data, capping the synthetic ratio, and not recursing blindly. The Phi/Textbooks results prove the safe regime exists; the Nature results prove the dangerous regime exists; the engineering is knowing which one you are in and staying in the safe one."Never use synthetic data" overcorrects as badly as "synthetic data is free signal" under-corrects. The careful position is the only correct one, and it is the harder one because it requires measurement instead of a slogan.
Chapter summary
Model collapse is real and routinely misquoted into "all synthetic data is bad." The Curse of Recursion and the Nature work show a specific process: recursive training on a model's own unfiltered, unanchored output causes the distribution's tails to vanish first, variance to shrink, and the model to converge toward its mean. The mechanism is statistical, finite sampling under-represents low-probability tail events, and that loss plus the model's own expressivity error compounds multiplicatively across generations, which cruelly means the rare-but-real cases teams generate to cover are the first casualties; one unfiltered, unanchored round is generation-one of the same trajectory. A minimal resampling simulation makes it undeniable: with no anchor the rare tail disappears by generation two and never returns, while re-injecting 10% real data each generation stabilizes the tail indefinitely, fresh real data arrests collapse, and the human anchor is not optional. Collapse requires three conditions (recursion, no anchor, no filtering); the Phi/Textbooks results are consistent with collapse research because they avoid all three, one generation, heavily filtered, mixed with real data. The distinct and rising concern is uncontrolled drift of web-scale corpora toward synthetic, which argues for provenance and valuing real data, not for banning generation. The honest position for a skeptic is neither slogan: collapse is avoided by filtering, anchoring, ratio caps, and not recursing blindly: measurement, not a catchphrase.