Manifests, Data Cards, and the Diff That Regenerates a Dataset
This chapter turns manifests, data cards, and the diff that regenerates a dataset into a concrete operating problem for the synthetic data book.

Key Takeaways
- Manifests, Data Cards, and the Diff That Regenerates a Dataset treats synthetic data as a governed artifact, not a free replacement for reality.
- The safe use depends on the cell: training, evaluation, red-team, demo, privacy, or lineage all need different gates.
- Generated data earns its keep only when a real anchor, verifier, and owner survive after generation.
**Working claim: ** Row-level provenance answers "where did this example come from"; a dataset manifest answers "what is this dataset, who made it, what is it allowed to do, and how do I reproduce it." A synthetic dataset without a manifest and a data card is unshippable, not because of policy, but because no one can safely consume it.
From rows to a release
Chapter 3 made every row traceable. That is necessary and insufficient. A consumer of your dataset, a teammate, a future you, an auditor, a fine-tuning job, does not read 41,000 rows. They read the label on the crate. If the crate has no label, they make assumptions, and the assumptions are wrong in exactly the ways this book is about: they assume the data is real, or that it is fine for eval, or that the labels are human-verified, or that it is safe to train on at any ratio.
A dataset manifest is the crate label. It is a single, machine-readable artifact that travels with the dataset and states what it is. A data card is the human-readable companion that explains the manifest to a person making a judgment call. Together they are the difference between a dataset you can hand off and a dataset that only its author can use safely, and authors leave.
This is the documentation tradition the field already has. Datasheets for Datasets proposed standardized documentation answering how a dataset was created, what it contains, and how it should and should not be used. Model Cards did the same for models. Both were written before LLM-generated datasets were routine, and both transfer directly. A synthetic dataset is more in need of this documentation than a collected one, because its defects (generator fingerprints, assumed labels, flattened tails) are invisible on inspection in a way that, say, a class imbalance in collected data often is not.
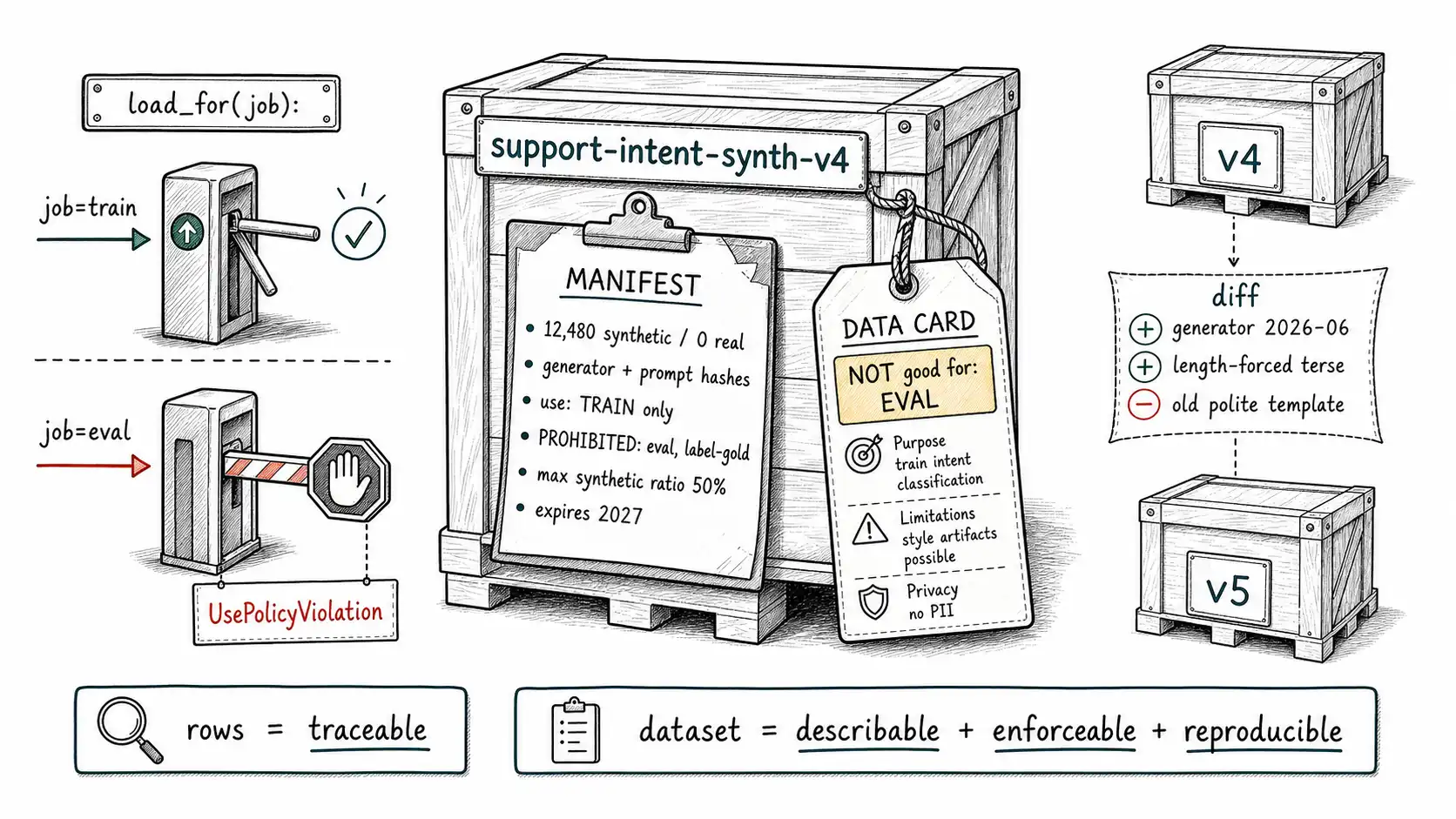
The manifest schema
Here is a dataset manifest for a synthetic dataset, as YAML. It is the dataset-level analog of the row schema: it records what the rows collectively are, how they were made, and the rules for using them.
manifest_version: "1.2"
dataset_id: "support-intent-synth-v4"
title: "Synthetic support tickets for rare-intent augmentation"
created_at: "2026-05-18T14:22:00Z"
created_by: "data-platform@acme"
status: "released" # draft | in_review | released | deprecated | quarantined
composition:
total_examples: 12480
by_source_type:
real: 0
synthetic: 12480
human_edited: 1120 # subset of synthetic that a human revised
by_intent: # the per-class counts - coverage is auditable here
gdpr_erasure: 1500
data_export_request: 1500
# ... remaining intents
real_anchor:
description: "38 real rare-intent tickets held aside, NOT in this dataset"
location: "anchors/rare_intent_real_v1 (eval_exclusion=true, never_train_on=true)"
generation:
generator_model: "vendor-model-X"
generator_version: "2026-04"
prompt_templates:
- template_id: "gdpr_erasure_v3"
prompt_hash: "sha256:9c1f..."
- template_id: "data_export_v3"
prompt_hash: "sha256:2ab8..."
sampling_params: { temperature: 0.95, top_p: 0.95 }
diversity_strategy: "persona x channel x verbosity matrix; see Ch.6"
seed_data: "rare_intent_real_v1 (used as few-shot exemplars only, not copied)"
quality_gates: # what was done after generation (Ch.7-8)
deduplication: { exact: true, near_dup_threshold: 0.92, removed: 3104 }
pii_scan: { status: "passed", findings: 0, tool: "pii-scan v2" }
realism_audit: { method: "synthetic-vs-real classifier", auc: 0.71, note: "Ch.7" }
human_review: { reviewed_fraction: 0.10, approve_rate: 0.83, reviewers: 3 }
use_policy:
intended_use: ["train"]
prohibited_use:
- "eval" # generated by a model the classifier trains alongside
- "prod_label_gold"
eval_exclusion: true
max_synthetic_ratio: 0.50 # see Ch.11 - cap on synthetic share of any training mix
expires_at: "2027-05-18" # re-review or retire (Ch.16)
known_limitations:
- "Generator over-produces long, polite phrasing; terse real tickets under-represented."
- "Channel diversity is simulated, not measured against real channel mix."
- "Labels are the prompted intent; verified on a 10% human-reviewed sample only."Several fields are doing quiet, important work. real_anchor records that there is an anchor and where it lives, with the flags that keep it out of training and eval, this is CAREFUL's A made auditable. prohibited_use and eval_exclusion are enforcement hooks, not just notes: your training pipeline should refuse to load a dataset whose prohibited_use includes the current job's purpose. max_synthetic_ratio carries a policy decision (Chapter 11) with the data so it cannot be forgotten. And known_limitations is the most honest field in the file, it states the fingerprints the team knows are present and did not fully remove, which is exactly what a consumer needs to decide whether this dataset is safe for their use.
The enforcement hook
A manifest that is only read by humans gets ignored under deadline. The manifest earns its keep when the pipeline enforces it. This is a small amount of code with a large payoff:
import datetime as dt
class UsePolicyViolation(Exception):
pass
def load_dataset_for(job_purpose: str, manifest: dict) -> str:
"""Refuse to hand a dataset to a job whose purpose is prohibited."""
if job_purpose in manifest["use_policy"]["prohibited_use"]:
raise UsePolicyViolation(
f"{manifest['dataset_id']} forbids use '{job_purpose}'."
f"intended_use={manifest['use_policy']['intended_use']}"
)
if manifest["status"] in ("draft", "quarantined", "deprecated"):
raise UsePolicyViolation(
f"{manifest['dataset_id']} status is '{manifest['status']}', not releasable."
)
expires = dt.date.fromisoformat(manifest["use_policy"]["expires_at"])
if dt.date.today() > expires:
raise UsePolicyViolation(
f"{manifest['dataset_id']} expired {expires}; re-review before use."
)
return manifest["dataset_id"] # ok to load
# An eval job that tries to use the synthetic train set fails LOUDLY, at load time:
# load_dataset_for("eval", support_intent_synth_v4_manifest)
# -> UsePolicyViolation: ...forbids use 'eval'...This is the difference between a use limit and a use policy. The support team in Chapter 1 had no enforcement, so the same data flowed into both training and the held-out split. Eight lines of load-time checking would have refused the eval job and surfaced the contamination before the model shipped.
The data card: judgment, not just facts
The manifest is for machines. The data card is for the human who has to decide whether to trust the dataset for something the manifest didn't anticipate. It is prose, short, and brutally honest. A good data card for the synthetic support dataset reads:
**Dataset: ** support-intent-synth-v4 **What it is: ** 12,480 synthetic support tickets generated to augment six rare intents. Entirely model-generated; no real tickets are included. **Why it exists: ** Real rare-intent tickets number in the dozens. This set raises minority-class counts for training only. **What it is good for: ** Training augmentation of rare intents, capped at 50% synthetic share, anchored against 38 held-aside real tickets. **What it is NOT good for: ** Evaluation of any kind. The generator's style (long, polite, self-labeling) does not match real tickets, and using this for eval will inflate scores. Do not use the prompted intents as ground-truth labels for measuring accuracy. **Known fingerprints: ** Over-long, over-courteous phrasing; terse and hostile real tickets under-represented; channel mix simulated, not measured. **How to reproduce: ** Prompt templates
gdpr_erasure_v3et al. (hashes in manifest), generator vendor-model-X@2026-04, temperature 0.95. Re-running with a different generator version will produce a different distribution; bump the dataset version. **Who to ask: ** data-platform@acme. **Reviewed by: ** 3 reviewers, 10% sample, 83% approve.
The card's value is the "NOT good for" paragraph. Facts alone do not stop misuse; a clear statement of the dataset's failure modes does. The Datasheets framework calls for exactly this, explicit statements of recommended and discouraged uses, and the discipline is even more important for synthetic data, whose discouraged uses (eval, label gold) are the tempting ones.
The diff that regenerates a dataset
Here is the capability that ties the chapter together and that most teams lack: the ability to treat a synthetic dataset's recipe as versioned source, so that a change to the recipe produces a reviewable diff and a regenerated, re-versioned dataset. Because the manifest records the generator, prompts, params, and gates, the recipe is just the manifest plus the prompt templates. Change one, and you can show exactly what changed:
dataset_id: "support-intent-synth-v4"
- dataset_id: "support-intent-synth-v5"
generation:
generator_model: "vendor-model-X"
- generator_version: "2026-04"
+ generator_version: "2026-06" # generator upgraded
sampling_params: { temperature: 0.95, top_p: 0.95 }
+ diversity_strategy: "persona x channel x verbosity x LENGTH-FORCED short/terse"
prompt_templates:
- - template_id: "gdpr_erasure_v3" # old: produced long polite tickets
+ - template_id: "gdpr_erasure_v4" # new: forces 40% terse, adds hostile/forwarded
known_limitations:
- - "Generator over-produces long, polite phrasing; terse real tickets under-represented."
+ - "Length distribution now matched to real anchor; hostile tone still under 5%."That diff is a design review of a dataset change. A reviewer can see that v5 upgraded the generator (which means re-running the contamination and realism checks the data-contamination survey argues are non-negotiable), added a length-forcing diversity strategy, and replaced the prompt template that produced the polished-ticket problem. The regeneration is reproducible because every input to it is recorded. Contrast this with the Chapter 1 reality, where "we generated more tickets" was an untracked act with no diff, no version bump, and no way to attribute the resulting model change to anything specific.
This is the Self-Instruct discipline generalized: that work treated the generation pipeline, seed tasks, generation prompt, filtering rules, as the artifact worth describing precisely, so the dataset could be understood and reproduced. A manifest-plus-diff workflow makes that reproducibility a default property of every synthetic dataset you ship, and it makes the NIST AI RMF governance expectations, knowing your data assets, their lineage, and their approved uses, something your tooling produces rather than something a compliance team chases.
What a release gate looks like
Pulling it together, a synthetic dataset is releasable when its manifest can answer yes to a small gate. This is not a generic checklist; it is the specific set of facts a consumer needs and a consumer cannot get from the rows:
- Is
source_typecomposition stated, and is the real/synthetic split explicit? - Is there a named, located
real_anchor, flagged out of train and eval? - Are generator, version, prompt hashes, and params recorded well enough to reproduce?
- Are
intended_use,prohibited_use, andeval_exclusionset, and is the load path enforcing them? - Is there a
max_synthetic_ratioand anexpires_at? - Does
known_limitationshonestly state the fingerprints the team did not remove? - Does the data card's "NOT good for" paragraph exist and name the tempting misuses?
A dataset that passes this gate can be handed to a stranger. A dataset that fails it can only be used safely by the person who made it, which means it cannot be used safely, because that person is, on a long enough timeline, gone.
Chapter summary
Row-level provenance is necessary but insufficient; consumers read the crate label, not the rows. A dataset manifest is that label, a machine-readable record of composition (real vs. synthetic split, per-class counts, the named real anchor), generation recipe (generator, version, prompt hashes, params, diversity strategy, seed), quality gates run, and use policy (intended use, prohibited use, eval exclusion, max synthetic ratio, expiry, known limitations). The manifest earns its keep only when enforced: a few lines of load-time checking should refuse to hand a dataset to a job whose purpose is prohibited, which is exactly the control the Chapter 1 team lacked. The data card is the human companion whose most valuable section is "NOT good for, " naming the tempting misuses (eval, label-gold) that facts alone do not prevent. Because the manifest records the full recipe, a synthetic dataset's generation becomes versioned source: changing the generator or a prompt template yields a reviewable diff and a re-versioned, reproducible dataset, a design review of a data change, replacing Chapter 1's untracked "we generated more." This generalizes the Datasheets/Model Cards tradition and the Self-Instruct reproducibility discipline, and it makes a dataset shippable to a stranger rather than usable only by an author who will eventually leave.