Generated Data Without Lineage Is Operational Debt
> **Working claim: ** A generated example with no recorded provenance is a liability disguised as an asset.

Key Takeaways
- Generated Data Without Lineage Is Operational Debt treats synthetic data as a governed artifact, not a free replacement for reality.
- The safe use depends on the cell: training, evaluation, red-team, demo, privacy, or lineage all need different gates.
- Generated data earns its keep only when a real anchor, verifier, and owner survive after generation.
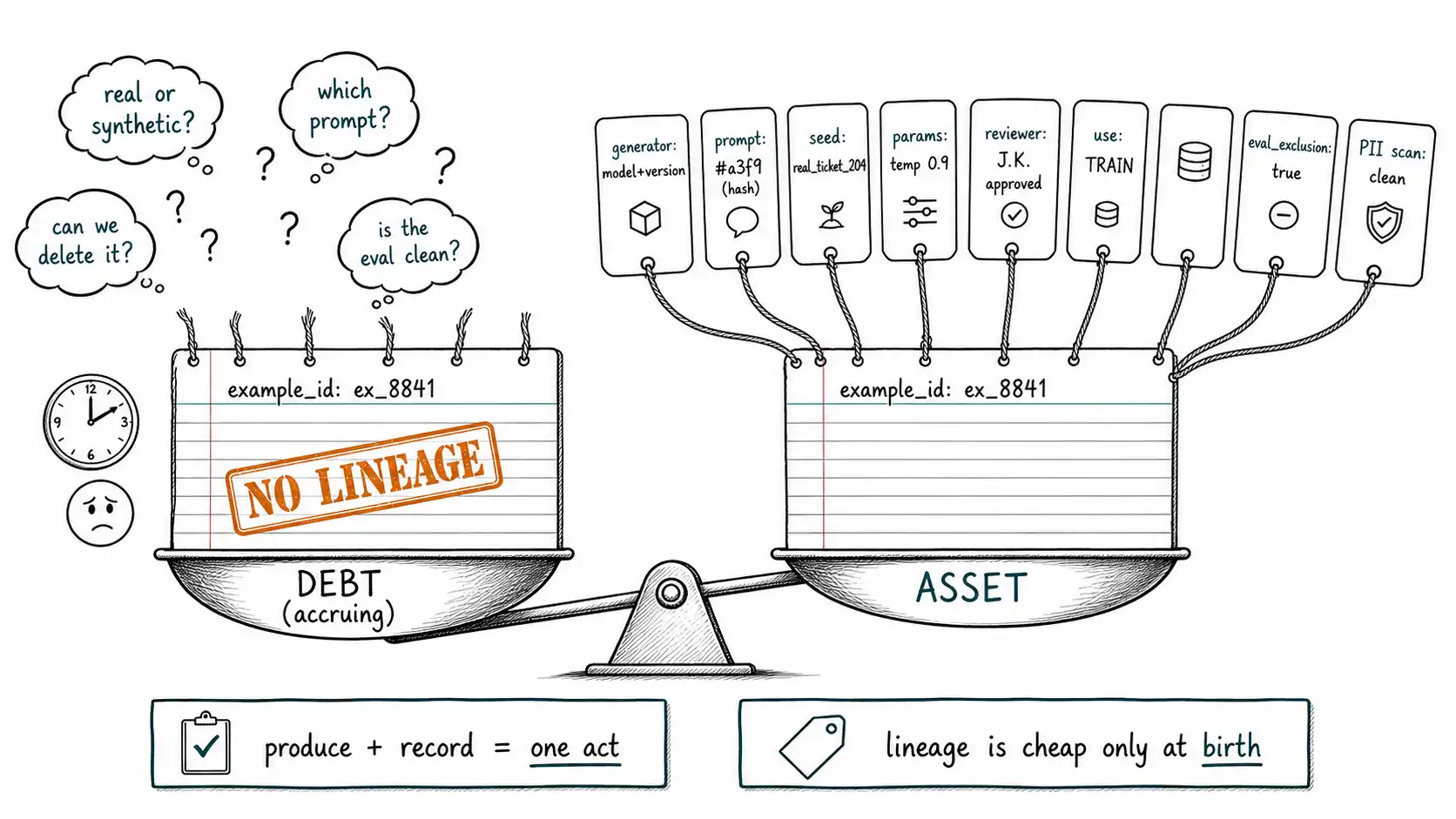
**Working claim: ** A generated example with no recorded provenance is a liability disguised as an asset. If you cannot say which model, which prompt, which seed, which parameters, and which reviewer produced an example, you cannot audit it, reproduce it, exclude it from an eval, or delete it on request, and every one of those will eventually be required of you.
The question you cannot answer at 2 a.m.
It is six months after the support classifier shipped, fixed, and stabilized. A new engineer is auditing the training set before a major retrain. She finds a training_v3.jsonl with 41,000 rows. About 1,800 are obviously the original real tickets. The rest are not labeled real or synthetic. She opens a sample. Some read like real customers. Some read like a model. A few contain what look like actual customer names. She has a simple, reasonable question: which of these did a model generate, and with what prompt?
Nobody can answer. The person who generated them left. The prompt lived in a notebook that was not committed. The generator was "GPT-something, whatever we were using in Q2." There is no seed, no timestamp, no parameters, no review record. The 39,000 synthetic rows are now indistinguishable from the real ones, which means several things are now impossible:
- She cannot exclude the synthetic rows from a held-out eval, because she cannot identify them. Any eval she builds from this pool is contaminated and she cannot prove otherwise.
- She cannot reproduce or regenerate them if a prompt bug is discovered, because the prompt is gone.
- She cannot delete the rows that contain real customer names in response to an erasure request, because she cannot find which generated rows ingested which real data.
- She cannot attribute a model regression to the data, because she cannot diff what changed.
This is operational debt, and like financial debt it accrues interest. The debt was taken on the day someone wrote df.to_json("training_v3.jsonl") without writing down how df was made. The interest is paid now, by someone else, in audit hours and risk. The thesis of this chapter is blunt: **generated data without lineage is debt, and provenance is the only principal payment. **
Provenance is not metadata garnish
It is easy to file provenance under "nice documentation" and deprioritize it behind shipping. That framing is wrong because provenance is load-bearing for operations, not decorative. The NIST AI RMF places data provenance and traceability inside its core functions precisely because you cannot govern, measure, or manage a risk you cannot trace. The OWASP LLM Top 10 lists data and model poisoning as a top risk, and the only way to detect or recover from a poisoned synthetic pipeline is to know what entered it and when. The data-contamination survey and the trustworthy-evaluation work keep arriving at the same operational requirement: to keep evaluation honest you must be able to prove that test data was not seen in training, and you cannot prove a negative about data you cannot identify.
Every one of those is an operational need, not a paperwork need. Provenance is the data layer that makes governance, contamination control, and erasure possible. Skip it and those capabilities are not merely harder, they are unavailable.
The minimum fields, and why each one earns its place
A common objection is that full provenance is heavy. It is lighter than you think, and every field exists to answer a specific 2 a.m. question. Here is the minimum record for a generated example, with the question each field answers.
| Field | Answers the question | What breaks without it |
|---|---|---|
example_id | Which row is this? | Can't reference, dedupe, or delete a specific example |
source_type | Real, synthetic, or human-edited? | Can't separate real from generated; eval contamination |
generator_model + generator_version | Which model made it? | Can't recall a batch when a model is found to be biased |
prompt_hash (+ stored template) | Which prompt produced it? | Can't reproduce, can't audit prompt-induced bias |
seed_source | What real data seeded it? | Can't trace PII ingress; can't assess leakage risk |
sampling_params | temperature, top_p, etc. | Can't reproduce; can't explain diversity collapse |
post_processing | What transforms ran after generation? | Can't explain why output differs from raw generation |
human_review_status | Reviewed? By whom? Verdict? | Can't tell verified from assumed |
license / consent_basis | Are we allowed to use this? | Legal exposure; can't honor consent withdrawal |
intended_use | Train / eval / red-team / demo | Silent crossings into stricter uses |
prohibited_use | What it must NOT be used for | No enforcement hook for use limits |
eval_exclusion | Should this be banned from eval? | Contaminated benchmarks |
created_at | When? | Can't reconstruct timeline of a regression |
Notice that this is the R of CAREFUL, recorded provenance, made concrete, and that several fields directly serve other CAREFUL letters: eval_exclusion serves E, prohibited_use serves U, human_review_status serves F. Provenance is not a separate concern from quality; it is the substrate the quality controls hang on.
A schema you can adopt tomorrow
Provenance is cheapest if it is structural, a schema the pipeline writes automatically, not a doc someone is supposed to update. Here is a lineage table for generated examples in SQL. It is deliberately strict: several columns are NOT NULL because a row that cannot say how it was made should not be insertable.
CREATE TABLE generated_example (
example_id TEXT PRIMARY KEY,
dataset_id TEXT NOT NULL REFERENCES dataset(dataset_id),
source_type TEXT NOT NULL CHECK (source_type IN ('real','synthetic','human_edited')),
content JSONB NOT NULL, -- the example itself
label JSONB, -- the label, if any
label_source TEXT CHECK (label_source IN ('human','model','rule','heuristic')),
-- generation provenance (NULL only when source_type='real')
generator_model TEXT,
generator_version TEXT,
prompt_hash TEXT, -- sha256 of the rendered prompt
prompt_template_id TEXT REFERENCES prompt_template(template_id),
seed_example_id TEXT REFERENCES generated_example(example_id), -- what seeded it
sampling_params JSONB, -- {"temperature":0.9,"top_p":0.95}
post_processing JSONB, -- ordered list of transforms applied
-- quality + governance
human_review_status TEXT NOT NULL DEFAULT 'unreviewed'
CHECK (human_review_status IN ('unreviewed','approved','rejected','needs_review')),
reviewer_id TEXT,
reviewed_at TIMESTAMPTZ,
intended_use TEXT NOT NULL CHECK (intended_use IN ('train','eval','red_team','demo')),
prohibited_use TEXT[], -- e.g. {'eval','prod_label_gold'}
eval_exclusion BOOLEAN NOT NULL DEFAULT FALSE,
license TEXT NOT NULL DEFAULT 'internal_generated',
consent_basis TEXT, -- if seeded by user data
contains_real_pii BOOLEAN NOT NULL DEFAULT FALSE,
pii_scan_status TEXT NOT NULL DEFAULT 'unscanned',
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
-- The constraint that prevents the 2 a.m. problem:
ALTER TABLE generated_example ADD CONSTRAINT synthetic_has_provenance
CHECK (
source_type <> 'synthetic'
OR (generator_model IS NOT NULL AND prompt_hash IS NOT NULL)
);The last constraint is the whole chapter expressed as a database rule: a synthetic row cannot be inserted without naming its generator and prompt. If your pipeline is built so that producing the example and recording its lineage are the same operation, the debt never accrues. If lineage is a separate step someone is supposed to remember, it will be skipped under deadline pressure, and you will meet that new engineer at 2 a.m.
Provenance makes contamination control mechanical
The most direct payoff is evaluation integrity. To keep an eval honest you must guarantee that no eval example was trained on. With provenance, that guarantee is a query, not a hope:
-- Find any training example whose content matches an eval example exactly.
-- (Semantic near-duplicate matching is Chapter 7; this is the exact-match floor.)
SELECT t.example_id AS train_id, e.example_id AS eval_id
FROM generated_example t
JOIN generated_example e
ON md5(t.content::text) = md5(e.content::text)
WHERE t.intended_use = 'train'
AND e.intended_use = 'eval';
-- Find eval examples generated by the same model the system was trained on.
-- These are contaminated by construction: the eval shares the generator's fingerprints.
SELECT e.example_id, e.generator_model
FROM generated_example e
WHERE e.intended_use = 'eval'
AND e.source_type = 'synthetic'
AND e.generator_model IN (SELECT model FROM training_run_generators);The second query is the one teams forget. Exact-match leakage is the obvious failure. The subtler one, surveyed across the contamination literature, is generator overlap: an eval generated by the same model family the system was trained on is contaminated even if no string matches, because it shares assumptions about what is askable and answerable. You can only run this query if you recorded generator_model on the eval set. Provenance is what turns "we think the eval is clean" into "we can show the eval is clean."
The cultural failure behind the technical one
The 2 a.m. story is usually told as a tooling failure, but it is a cultural one. The team that lost its provenance did not lack the ability to write a generator_model column. They lacked the norm that producing synthetic data and recording its lineage are inseparable acts. The norm erodes in three predictable ways:
- **Generation happens in notebooks. ** Notebooks are exploratory and uncommitted by nature. The prompt that produced a shipped dataset lived in cell 14 of a notebook that was overwritten the next day. The fix is to promote any prompt that produces kept data out of the notebook and into a versioned template store before the data is saved.
- "We'll add lineage later." Later never comes, because by the time anyone needs it, the context to reconstruct it is gone. Lineage is only cheap at creation; afterward it is archaeology.
- **One folder, many uses. ** A single
data/directory with mixed real, synthetic, train, and eval files invites crossings. Provenance fields plus enforced separation (the warehouse shelves of Chapter 2) prevent the glob pattern from sweeping the wrong rows.
The Datasheets for Datasets authors named this dynamic from the documentation side years before LLM-generated data was common: datasets without a record of their creation and intended use get misused by default, not by malice. Their datasheet questions, how was the data collected, by whom, for what purpose, with what preprocessing, under what consent, map almost one-to-one onto the provenance fields above. The lesson transfers directly: the discipline that prevents misuse of any dataset prevents the specific misuses of generated data, and it has to be structural, not aspirational.
Chapter summary
A generated example with no recorded provenance is operational debt that accrues interest until someone else pays it. The 2 a.m. scenario, a mixed dataset where real and synthetic rows are indistinguishable, the generating prompt is lost, and no review record exists, makes four required operations impossible: excluding synthetic rows from evals, reproducing or regenerating data, deleting rows that ingested real PII, and attributing regressions to data changes. Provenance is not documentation garnish; it is the data layer that makes governance, contamination control, and erasure possible, which is why NIST, OWASP, and the contamination literature all treat traceability as load-bearing. A minimum lineage record (source type, generator and version, prompt hash, seed, sampling params, post-processing, review status, license/consent, intended and prohibited use, eval exclusion, PII status, timestamp) answers a specific operational question per field and makes contamination checks a query rather than a hope, including the often-forgotten check for generator overlap between eval and training. The failure is ultimately cultural: lineage erodes through uncommitted notebook prompts, "we'll add it later, " and one shared folder. The fix is structural, make producing an example and recording its lineage the same database operation, enforced by a constraint that refuses to insert a synthetic row that cannot name its generator and prompt.