Patterns That Earn Their Keep
> **Working claim: ** Generation helps when it fills a *named, bounded* gap with examples a model can produce reliably and a human can verify cheaply.

Key Takeaways
- Patterns That Earn Their Keep treats synthetic data as a governed artifact, not a free replacement for reality.
- The safe use depends on the cell: training, evaluation, red-team, demo, privacy, or lineage all need different gates.
- Generated data earns its keep only when a real anchor, verifier, and owner survive after generation.
**Working claim: ** Generation helps when it fills a named, bounded gap with examples a model can produce reliably and a human can verify cheaply. It hurts when it is asked to manufacture the thing that needed verifying in the first place, most dangerously, synthetic rationales, which read as proof and are merely fluent.
The constructive turn
The first four chapters were mostly about what goes wrong. This chapter is the opposite: a catalog of generation patterns that genuinely work, with the conditions that make them work. The book is not anti-synthetic-data, and a manual that only catalogs failures teaches fear, not skill. The skill is knowing which generation tasks are safe and why, so you can reach for the safe ones confidently and treat the dangerous ones with the suspicion they earn.
A single principle sorts the patterns. **Generation is safe to the degree that verification is cheap and the gap is bounded. ** If you can cheaply check whether a generated example is correct, and the thing you are generating is a known, bounded variation rather than novel ground truth, generation is a force multiplier. If checking correctness is as hard as producing the example, or the gap is open-ended, generation is laundering uncertainty. Hold that principle and the catalog organizes itself.
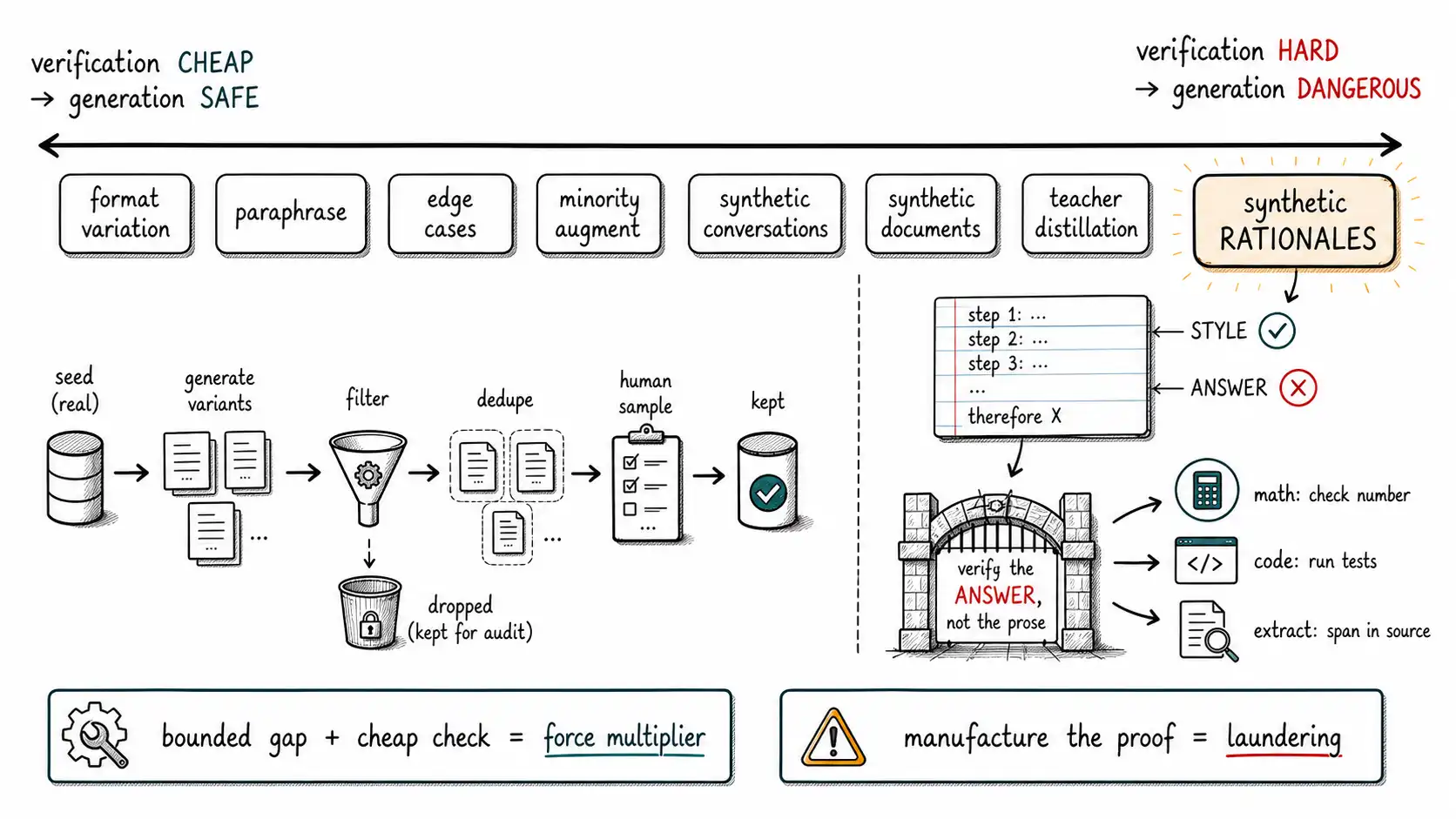
The patterns, by how much verification they need
| Pattern | What it generates | Verification cost | Safe because / dangerous when |
|---|---|---|---|
| Paraphrase expansion | Reworded versions of real examples | Cheap (meaning-preservation check) | Safe: anchored to a real example, label preserved. Dangerous when paraphrases drift in meaning and the label silently no longer applies. |
| Format variation | Same content, new surface form (JSON↔text, date formats, casing) | Cheap (deterministic) | Safe: makes parsers/classifiers robust. Rarely dangerous. |
| Minority-class augmentation | More examples of a rare class | Medium (a human can judge class membership) | Safe when shape is preserved; dangerous when it flattens the rare class into a central caricature (Ch. 1). |
| Edge-case generation | Deliberately unusual inputs | Medium | Safe: fabrication is appropriate here, you want the weird case. Dangerous when edges are weird in ways the system already handles. |
| Intent / coverage filling | Examples for under-covered intents or slots | Medium | Safe with a coverage map (Ch. 6); dangerous as undirected "more data." |
| Synthetic conversations | Multi-turn dialogues for tool-use/agent flows | Medium-High | Safe for structure and tool-call practice; dangerous because synthetic users are too cooperative and tool errors are under-represented. |
| Synthetic documents | Long-form docs for extraction/RAG tests | High | Safe for format coverage; dangerous when the answer is too findable and real document chaos is absent. |
| Teacher distillation | A stronger model labels/answers for a smaller one | High | Powerful (Alpaca) but inherits the teacher's errors wholesale; verify against a real anchor. |
| Synthetic rationales | Step-by-step reasoning/explanations | Very high | **Most dangerous. ** Fluent reasoning reads as verified. Train on it only after the answer (not the prose) is independently checked. |
Read top to bottom and the risk rises with verification cost, exactly as the principle predicts. The safe end is mechanical and anchored; the dangerous end asks the generator to supply the thing you cannot cheaply check.
A controlled-variant pipeline
The safe patterns share a shape: take a real seed, produce bounded variations, filter to a human-review queue, and keep what survives. Here is that pipeline as a generation→filter→dedupe→review flow. The point is not the API call; it is the gates between the steps.
from dataclasses import dataclass, field
from hashlib import sha256
@dataclass
class Candidate:
text: str
label: str
seed_id: str
template_id: str
prompt_hash: str
status: str = "candidate" # candidate -> kept | dropped | needs_review
drop_reason: str | None = None
def generate_variants(seed, template, n, sampler) -> list[Candidate]:
rendered = template.render(seed=seed)
out = []
for _ in range(n):
text = sampler.generate(rendered) # the only model call
out.append(Candidate(
text=text, label=seed.label, seed_id=seed.id,
template_id=template.id,
prompt_hash=sha256(rendered.encode()).hexdigest(),))
return out
def filter_pipeline(cands, *, real_corpus, near_dup, label_check) -> list[Candidate]:
seen = set()
for c in cands:
# 1. exact dedup
h = sha256(c.text.strip().lower().encode()).hexdigest()
if h in seen:
c.status, c.drop_reason = "dropped", "exact_duplicate"; continue
seen.add(h)
# 2. near-duplicate vs already-kept and vs real corpus (Ch.7)
if near_dup.too_similar(c.text):
c.status, c.drop_reason = "dropped", "near_duplicate"; continue
# 3. label sanity: does the text still match the claimed label?
if not label_check.consistent(c.text, c.label):
c.status, c.drop_reason = "needs_review", "label_uncertain"; continue
# 4. survivors still go to a human SAMPLE, not straight to train
c.status = "needs_review" if near_dup.is_novel_region(c.text) else "kept"
return cands
# Everything dropped is KEPT in an audit table, not deleted (Ch.7).Three design choices matter more than the code. First, the label travels from the seed, but a label_check still verifies it, because a paraphrase can drift until the label no longer fits, and an assumed label is the Chapter 1 failure. Second, survivors in novel regions of the space go to a human, not straight to training; the generator is most likely to fabricate exactly where it has the least real grounding. Third, dropped candidates are retained for audit (the reject set of Chapter 7), so you can later ask what the generator over-produced and why.
The pattern that built famous models: and its actual recipe
The strongest evidence that generation works is the instruction-tuning and small-model-quality lineage. It is worth stating the recipe precisely, because the lesson is the opposite of "just generate."
Self-Instruct started from 175 human-written seed tasks and used a model to bootstrap new instructions and instances. The headline is "the model generated its own training data." The fine print is the filtering: new instructions were discarded if they were too similar to existing ones (a diversity gate), if the model could not produce a valid instance for them, or if they were duplicates or invalid. The generation was cheap; the selection was the contribution. Stanford Alpaca applied this to produce 52,000 demonstrations from a stronger teacher at low cost, explicitly a teacher-distillation pattern, and the authors were candid that the result inherited the teacher's limitations and was a research artifact, not a production-grade dataset.
Textbooks Are All You Need and the Phi-3 report pushed the quality-over-quantity thesis hardest: small models trained on filtered web data plus carefully generated "textbook-quality" synthetic data matched or beat much larger models. This is the most pro-synthetic result in the field, and its actual recipe is curation. The synthetic data was generated to a high pedagogical bar and combined with aggressive filtering of what to exclude. The win was not raw generation volume; it was treating data quality as the central engineering problem.
The contrast that completes the picture is InstructGPT, which anchored alignment in human demonstrations and human preference judgments. The human signal is the anchor (CAREFUL's A) that the synthetic methods lean on indirectly, Alpaca distilled from a model that was itself aligned with human feedback. None of these methods generated in a vacuum. Each one had reality somewhere in the loop: human seeds, human preferences, or a teacher that human feedback had shaped.
The dangerous pattern, in detail: synthetic rationales
The single most seductive and most dangerous pattern deserves its own treatment, because it is where careful teams still get burned. A synthetic rationale is a generated chain of reasoning, "let's solve this step by step", attached to an answer. Teams generate rationales to teach models to reason, and the practice has real value. The hazard is specific: **a rationale's fluency is uncorrelated with its correctness, but humans and downstream training treat fluency as evidence of correctness. **
A generator can produce a beautifully structured, confidently worded derivation that arrives at a wrong answer through a plausible-looking but invalid step. If you train on it, you are not teaching reasoning; you are teaching the appearance of reasoning, decoupled from getting the answer right. The model learns to emit confident derivations, including for cases where it is wrong, because that is the pattern it was rewarded on.
The defense is to never let the rationale be its own warrant. Concretely:
def accept_rationale(item) -> bool:
# The ANSWER must be checkable independently of the rationale's prose.
if item.task_type == "math":
return verify_numeric(item.answer, item.gold) # exact check
if item.task_type == "code":
return run_unit_tests(item.code).all_pass # execution check
if item.task_type == "extraction":
return item.answer in item.source_document # grounding check
# If the answer can't be checked independently, the rationale is unverifiable.
# Do NOT train on it as if correct; route to human or discard.
return FalseThe rule is simple to state and constantly violated: **train on a rationale only when the final answer is independently verifiable, and verify the answer, not the prose. ** For math, check the number. For code, run the tests. For extraction, confirm the span is in the source. When the answer cannot be checked independently of the reasoning that produced it, open-ended explanation, judgment, "why" questions: a synthetic rationale is exactly the artifact this book warns about: a confident-looking sample masquerading as truth. That is the type-7 "Forbidden as gold" cell of Chapter 2, made concrete.
A worked example: edge cases for a returns-policy classifier
To ground the safe end, take a real, small task. A retailer's classifier decides whether a return request is within_policy, outside_policy, or needs_human. The real data is dominated by clean cases; the misclassifications cluster on edge cases the logs barely contain. This is fabrication's home turf, because you want the unusual case and the label is checkable by a human against a written policy.
Useful generated edges, each anchored to a real policy clause:
- "I bought this 31 days ago, your policy says 30, but it was a gift and I didn't open it until yesterday." →
needs_human(policy is silent on gifts; this is the genuine ambiguity). - "Returning a final-sale clearance item because it's defective." →
needs_human(final-sale vs. defective conflict, a real policy collision). - "I want to return it but I never received it." →
outside_policyfor returns, but actually a different intent (this tests whether the classifier confuses non-delivery with returns).
Each edge is generated to probe a named boundary in the policy, a human can verify the label against the written policy in seconds, and the cases are exactly the ones reality under-supplies. That is the recipe: bounded gap, cheap verification, anchored to a real artifact (the policy). The contrast with Chapter 1 is sharp, there, the generator was asked to manufacture the whole distribution; here, it is asked to manufacture named hard cases a human can check.
Chapter summary
Generation helps when verification is cheap and the gap is bounded, and hurts when it is asked to manufacture the very thing that needed verifying. Ordered by rising verification cost, the safe-to-dangerous spectrum runs from format variation and paraphrase (mechanical, anchored), through minority-class augmentation, edge cases, intent filling, synthetic conversations, and synthetic documents, to teacher distillation and, most dangerous, synthetic rationales. The safe patterns share a pipeline: real seed → bounded variants → exact and near-duplicate dedup → label verification → human review of novel-region survivors → keep, with everything dropped retained for audit. The famous successes (Self-Instruct, Alpaca, the Textbooks/Phi line) won not through raw generation but through aggressive filtering, curation, and a human or human-shaped anchor somewhere in the loop, in contrast to InstructGPT's direct human anchoring. Synthetic rationales are the seductive trap: fluency is uncorrelated with correctness but is treated as evidence of it, so train on a rationale only when the final answer is independently verifiable, check the number, run the tests, confirm the span, and verify the answer, not the prose. A returns-policy edge-case example shows the safe recipe concretely: generate named hard cases against a written policy a human can check in seconds.