The Gates After Generation
> **Working claim: ** Synthetic data is only as good as the gates that run after generation. Generation is the cheap, optimistic part; filtering is the expensive, skeptical part, and it is where quality is actually decided.

Key Takeaways
- The Gates After Generation treats synthetic data as a governed artifact, not a free replacement for reality.
- The safe use depends on the cell: training, evaluation, red-team, demo, privacy, or lineage all need different gates.
- Generated data earns its keep only when a real anchor, verifier, and owner survive after generation.
**Working claim: ** Synthetic data is only as good as the gates that run after generation. Generation is the cheap, optimistic part; filtering is the expensive, skeptical part, and it is where quality is actually decided. The gates must be ordered, they must keep what they reject, and "reject confidently" must be a normal outcome, not a failure.
Generation is the easy half
Every team that gets burned by synthetic data spent its effort on the wrong half. Generation is intoxicating because it produces a big number fast, ten thousand examples, look at all this data. Filtering is unglamorous because it makes the big number smaller and the work is skeptical, repetitive, and easy to skip. But the gates after generation are where a synthetic dataset earns the right to exist. The Self-Instruct result is, read honestly, mostly a filtering result: the generation was trivial, and the contribution was the cascade of filters that decided what survived.
This chapter is that cascade, built as an ordered pipeline. Order matters, because cheap, deterministic gates should run before expensive, fuzzy ones, you do not pay for a semantic similarity computation on an example an exact-duplicate check would have killed for free. The gates, in order: format validation, exact dedup, near-duplicate detection, PII/toxicity screening, contradiction/realism checks, and label consistency. Each gate has one job and a recorded reject reason.
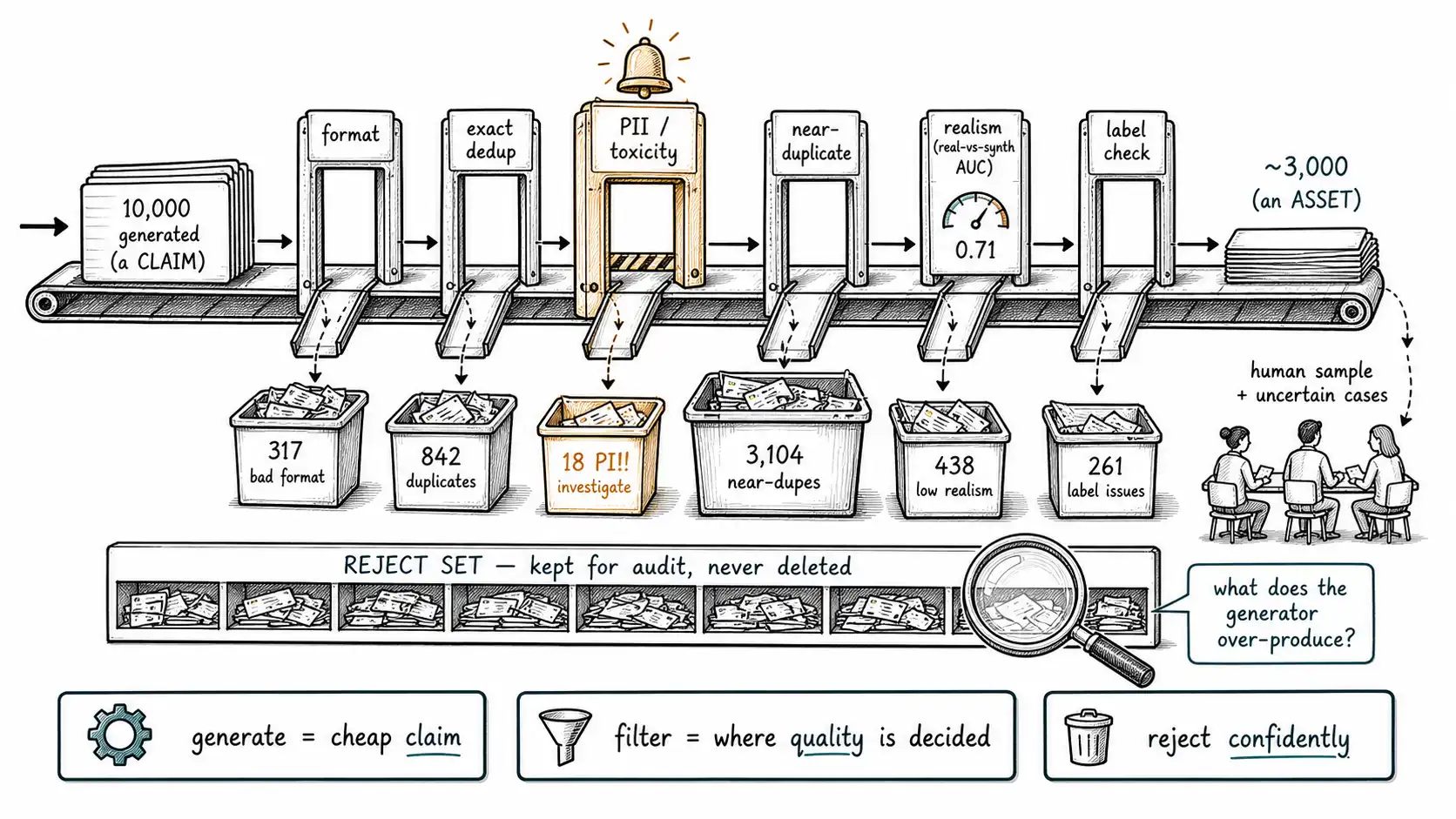
The gate order, and why
GATES = [
"format_valid", # cheap, deterministic - does it parse / fit the schema?"exact_dedup", # cheap - hash match
"pii_toxicity", # cheap-ish - regex/classifier, but SAFETY-critical so early
"near_duplicate", # medium - embedding similarity
"realism", # medium - synthetic-vs-real classifier (this chapter's star)
"label_consistency", # medium - does the text support the claimed label?"human_sample", # expensive - route a sample + all uncertain cases to people
]Two ordering choices are deliberate. PII and toxicity run early despite not being the cheapest, because a leaked real name or a toxic example is a safety problem you want caught before it propagates into any later stage or any human's screen. And the human sample runs last, on survivors plus all uncertain cases, because human time is the scarcest gate and you want it spent on what the automated gates could not decide. Every example carries its outcome and reason, and, this is the rule teams skip, **nothing is deleted; rejects are moved to an audit table. **
Deduplication: exact and near
Exact deduplication is a hash and a set. The interesting gate is near-duplicate detection, because generators produce examples that are not byte-identical but are semantically the same, the "ten rephrasings of three ideas" of Chapter 6. Near-duplicates are dangerous in two distinct ways: they inflate your apparent dataset size (you think you have 10,000 examples; you have 3,000 ideas times 3), and if some land in training and their near-twins land in eval, you have leakage that exact-match checks miss entirely.
import numpy as np
def near_duplicate_clusters(embeddings, threshold=0.92):
"""Greedy near-dup clustering. Returns cluster id per example; -1 = unique."""
e = embeddings / np.linalg.norm(embeddings, axis=1, keepdims=True)
cluster = np.full(len(e), -1)
cid = 0
for i in range(len(e)):
if cluster[i]!= -1:
continue
sims = e @ e[i]
members = np.where(sims >= threshold)[0]
if len(members) > 1:
cluster[members] = cid
cid += 1
return cluster
# Keep one representative per cluster; send the rest to the reject table
# with drop_reason='near_duplicate', cluster_id recorded for audit.The same machinery does double duty as a leakage check across the train/eval boundary. Run near-duplicate detection over the union of a candidate training example and the eval set; any candidate within threshold of an eval example is contaminated and must be dropped from training. This is the semantic complement to the exact-match SQL of Chapter 3, and the contamination survey is explicit that near-duplicate and paraphrase leakage is a primary way benchmarks get quietly contaminated, string-match checks pass while the model has effectively seen the test.
-- Candidate training examples too close to ANY eval example (semantic leakage).
-- near_sim is precomputed from the embedding index.
SELECT c.example_id, c.near_eval_id, c.near_sim
FROM candidate_train c
WHERE c.near_sim >= 0.92
ORDER BY c.near_sim DESC; -- every row here MUST be dropped from trainingThe realism gate: a synthetic-vs-real classifier
Here is the chapter's most useful diagnostic, and one of the book's signature tools. If you have any real anchor data, you can train a simple classifier to distinguish real examples from your synthetic ones. The classifier's accuracy is a measurement of how distinguishable, how fingerprinted, your synthetic data is.
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
import numpy as np
def realism_auc(real_emb, synth_emb) -> float:
"""AUC of a real-vs-synthetic classifier.
~0.5 -> synthetic is INDISTINGUISHABLE from real (good for training realism)
~1.0 -> synthetic is trivially separable (heavy fingerprints; the Ch.1 failure)"""
X = np.vstack([real_emb, synth_emb])
y = np.r_[np.ones(len(real_emb)), np.zeros(len(synth_emb))]
clf = LogisticRegression(max_iter=1000)
return cross_val_score(clf, X, y, scoring="roc_auc", cv=5).mean()The interpretation is counterintuitive at first and then obvious. A classifier that cannot tell real from synthetic (AUC near 0.5) means your synthetic data sits in the real distribution, the fingerprints are faint. A classifier that easily separates them (AUC near 0.9+) means your synthetic data is trivially marked as fake, the Chapter 1 polished tickets, separable from real ones in milliseconds because they are all long and polite. The realism gate uses this two ways: as a release metric in the manifest (Chapter 4 recorded AUC 0.71), and as a feature-importance microscope, inspect which features the classifier uses to separate, and you learn exactly what the fingerprints are (length, politeness markers, specific tokens). That tells you what to fix in the generation prompt.
A crucial caveat keeps this honest: low separability is necessary but not sufficient, and it is the wrong target for some uses. For training realism you want low AUC. But for edge cases and red-team data you may want high separability, because the whole point is to produce inputs unlike the normal distribution. The realism gate is a measurement; whether high or low AUC is good depends on the dataset's purpose, which is why the manifest's intended_use must be read alongside it.
Contradiction and consistency checks
For generated factual content, documents, QA pairs, rationales, a powerful filter is self-consistency. The SelfCheckGPT insight is that a model's hallucinations tend to be inconsistent across repeated samples, while grounded content is stable. You can adapt this as a filter: generate an example, then ask the same or another model the same question several times and measure agreement. High variance flags a likely fabrication for human review.
For generated QA pairs specifically, the RAGAS framing of reference-free metrics, faithfulness (is the answer grounded in the provided context?), answer relevance, context relevance, gives a vocabulary for automated checks that do not require a human gold answer. If you generated a QA pair from a source document, you can check that the answer is actually supported by the document (faithfulness) and that the question is answerable from it (context relevance). These are exactly the checks that catch the "hidden answerability assumption" that plagues synthetic evals (Chapter 9). The OpenAI evals guide describes the same pattern operationally: define graders that check structural and grounding properties automatically, reserving humans for judgment calls.
A word of caution that the book keeps returning to: these consistency and faithfulness checks are themselves model-based, so they import the checking model's biases. They are filters that reduce risk, not oracles that certify truth. Use them to triage, confident-pass, confident-reject, route-to-human, never to stamp a generated example as verified ground truth on their own.
Reject reasons and the audit set
The single most undervalued artifact in a synthetic-data pipeline is the reject set: everything the gates threw out, retained with its reason. Teams delete rejects to save space and lose their most valuable diagnostic. The reject set tells you what your generator over-produces, where your filters bite, and whether your gates are mis-calibrated.
-- The reject taxonomy: what are we throwing away, and why?
SELECT drop_reason, COUNT(*) AS n,
ROUND(100.0 * COUNT(*) / SUM(COUNT(*)) OVER (), 1) AS pct
FROM rejected_example
WHERE dataset_id = 'support-intent-synth-v4'
GROUP BY drop_reason ORDER BY n DESC;
-- Example output:
-- near_duplicate 3104 38.2% <- generator is repeating itself heavily
-- label_uncertain 980 12.1%
-- exact_duplicate 412 5.1%
-- pii_detected 18 0.2% <- real names leaked into generation! investigate
-- realism_outlier 201 2.5%That pii_detected: 18 row is the chapter's quiet alarm. Eighteen generated examples contained real PII: almost certainly because the generation prompt included real seed data that the model echoed back. Without a reject set, those eighteen examples are silently dropped and the leak is never investigated. With it, you discover that your seed data is bleeding into generated output, which is a Chapter 12 privacy problem caught early. The reject set turns filtering from a quality step into a feedback loop on the entire pipeline.
Rejecting confidently
The cultural point underneath the code: **rejecting synthetic data must be a normal, frequent, unremarkable outcome. ** A pipeline that keeps 95% of what it generates is not a good pipeline; it is an unfiltered one. Self-Instruct discarded a large fraction of generated instructions. The Phi/Textbooks line was defined by what it excluded. Aggressive rejection is the signature of a serious synthetic-data process, and a low reject rate should worry you more than a high one.
The reason teams under-reject is psychological: generation produced a satisfying big number, and filtering shrinks it, which feels like loss. Reframe it. The big number after generation is a claim; the smaller number after filtering is an asset. Ten thousand candidates that filter down to three thousand verified, diverse, deduplicated, realistically-fingerprinted examples is a far better dataset than ten thousand unfiltered ones, and it is the only version of the ten thousand you can honestly put a manifest on.
Chapter summary
Synthetic data's quality is decided after generation, in the gates, and teams that get burned spent their effort on the cheap, optimistic generation half instead of the expensive, skeptical filtering half, even though Self-Instruct's celebrated result was mostly a filtering result. The gates run in deliberate order: cheap deterministic checks (format, exact dedup) first, safety-critical PII/toxicity early despite cost, then medium-cost fuzzy gates (near-duplicate, realism, label consistency), with the scarce human gate last on survivors and uncertain cases. Near-duplicate detection does double duty as a semantic leakage check across the train/eval boundary, catching the paraphrase contamination that string matching misses. The signature diagnostic is a real-versus-synthetic classifier whose AUC measures how fingerprinted the data is, near 0.5 means indistinguishable from real (good for training realism), near 1.0 means trivially fake (the Chapter 1 failure), and whose feature importances reveal exactly which fingerprints to fix, though the right target depends on intended use. Consistency (SelfCheckGPT-style) and faithfulness (RAGAS-style) checks triage factual content but are model-based filters, not truth oracles. The most undervalued artifact is the retained reject set with reasons, which turns filtering into a feedback loop and surfaces alarms like leaked PII. Rejecting confidently and frequently is the signature of a serious pipeline; a low reject rate should worry you more than a high one.