Evaluation Is Where Synthetic Data Does the Most Damage
> **Working claim: ** Synthetic data is most dangerous when it becomes your ruler. A generated training example that is wrong costs you some signal; a generated evaluation example that is wrong destroys your ability to *detect* that anything is wrong.

Key Takeaways
- Evaluation Is Where Synthetic Data Does the Most Damage treats synthetic data as a governed artifact, not a free replacement for reality.
- The safe use depends on the cell: training, evaluation, red-team, demo, privacy, or lineage all need different gates.
- Generated data earns its keep only when a real anchor, verifier, and owner survive after generation.
**Working claim: ** Synthetic data is most dangerous when it becomes your ruler. A generated training example that is wrong costs you some signal; a generated evaluation example that is wrong destroys your ability to detect that anything is wrong. Evaluation isolation is not a best practice, it is the difference between measuring your system and measuring your generator's reflection of it.
The asymmetry at the heart of the chapter
Every prior chapter has a worse version of itself when the data is used for evaluation. A flattened distribution in training data costs you some generalization. A flattened distribution in evaluation data costs you the ability to notice the flattening, because the test rewards exactly the flattened behavior. This asymmetry is the whole chapter: errors in training data degrade the system; errors in evaluation data degrade your knowledge of the system. The second is far worse, because a degraded system you can measure is fixable, and a system you cannot measure is a confident guess wearing a number.
The Chapter 1 team lived this. Their training augmentation was imperfect but survivable, anchored and ratio-capped, it might have helped. Their evaluation was fatal: the held-out split shared the generator's fingerprints, so the eval rewarded the polished-ticket style the model had learned, reported 0.88, and gave zero warning. The training mistake made the model worse; the evaluation mistake made the team blind. This chapter is about staying able to see.
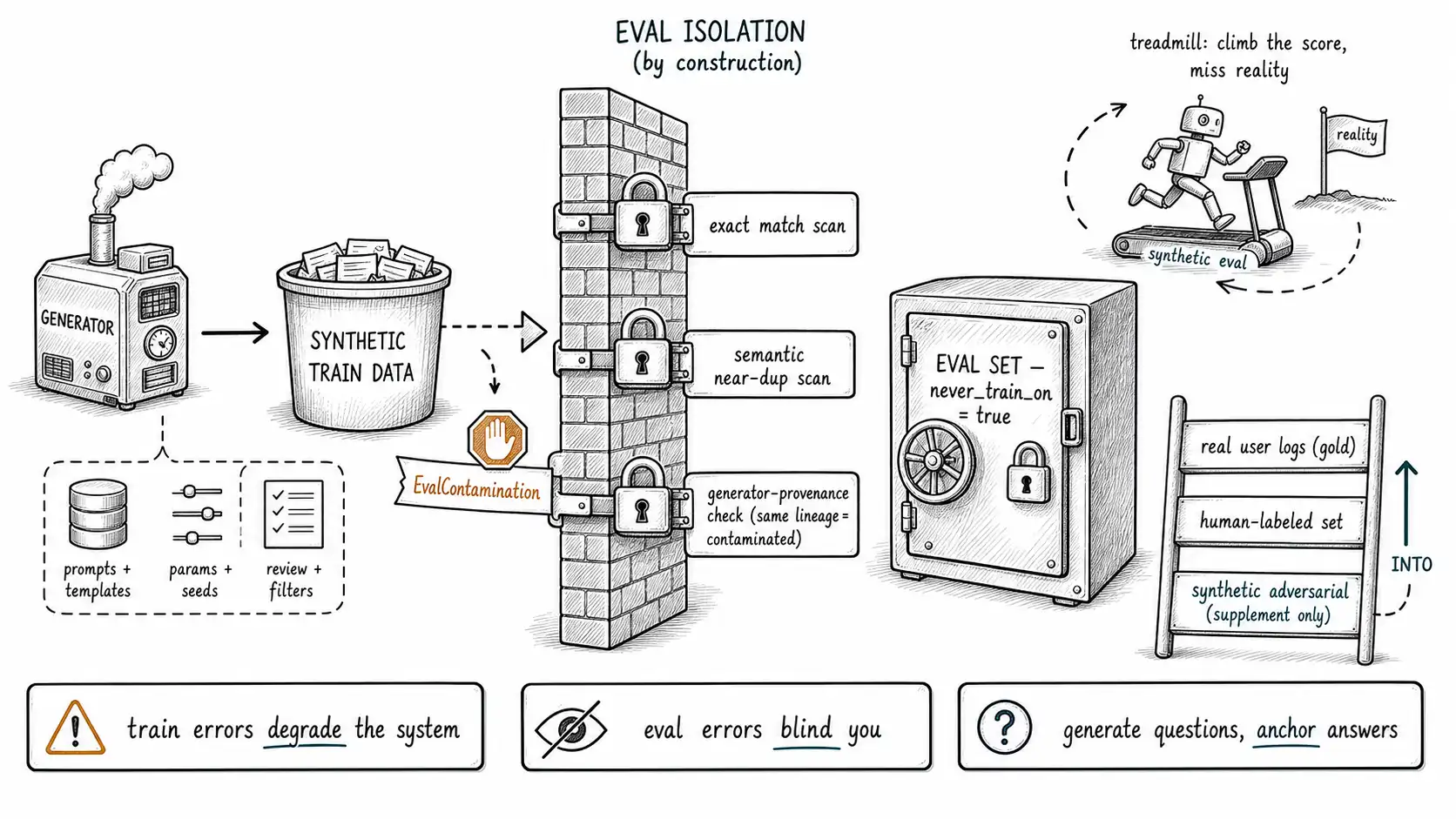
The four ways synthetic evals lie
Synthetic evaluation data fails in four characteristic ways, and they compound.
**1. Encoded generator assumptions. ** A generated test question reflects what the generator thinks is askable. If the generator never imagines terse, hostile, or malformed inputs, the eval never contains them, and a model that fails on exactly those inputs scores perfectly. The eval inherits the generator's imagination as its boundary. This is the polished-ticket problem aimed at the ruler instead of the training set.
**2. Hidden answerability assumptions. ** When you generate a question and its expected answer from the same source, you bake in the assumption that the question is answerable, and answerable in the way the generator answered it. Real users ask unanswerable questions, ambiguous questions, and questions with multiple valid answers. A synthetic eval where every question has one clean generated answer over-rewards models that confidently answer everything and never abstain. The RAGAS framing makes the failure precise: context relevance and answer relevance are separate properties, and generating both from one pass collapses them, so you never test whether the system correctly declines an unanswerable question.
**3. Benchmark contamination / leakage. ** If the eval is generated by the same model the system was trained on or distilled from, the eval is contaminated by construction even with zero string overlap, because it shares the generator's distribution. Worse, generated eval examples can be near-duplicates of training examples (Chapter 7), so the model has effectively seen the test. The contamination survey and trustworthy-evaluation work document that this leakage is frequently invisible to exact-match checks and can even cross languages and paraphrases, a benchmark can be contaminated by a translated or reworded version of itself.
**4. Overfitting to synthetic style. ** Run a synthetic eval long enough as your primary metric and your team optimizes the model to the eval's style. You climb the synthetic benchmark while diverging from reality, and because the benchmark is your only window, the divergence is invisible until production. The synthetic eval becomes a treadmill: you run faster and the scenery never changes.
Generating questions vs. generating answers
A distinction that resolves much of the danger: it is far safer to generate questions than to generate answers, and safest of all to generate questions whose answers are checked by something other than the generator.
Generating questions expands coverage, you can probe more of the input space than your logs captured. The risk is bounded: a bad generated question is a poorly-targeted test, not a wrong ruler. Generating answers is where the ruler corrupts, because a generated expected-answer is the standard you score against, and if it is wrong, every model that gets the right answer is marked wrong and every model that shares the generator's error is marked right.
The safe pattern, therefore:
def build_eval_item(source_doc, generator, verifier) -> dict | None:
# 1. Generate a QUESTION (coverage expansion - low risk).
q = generator.make_question(source_doc)
# 2. Do NOT trust a generated answer as gold. Get gold from a stronger source:
gold = None
if verifier.kind == "human":
gold = verifier.human_answer(q, source_doc) # gold = human
elif verifier.kind == "extractive":
gold = verifier.extract_span(q, source_doc) # gold = a span we can check
elif verifier.kind == "executable":
gold = verifier.compute(q) # gold = a runnable check
# 3. If no trustworthy gold exists, the item is unusable as a scored eval case.
if gold is None:
return None # discard; do not fabricate gold
return {"question": q, "gold": gold, "gold_source": verifier.kind}The function refuses to fabricate gold. A generated question with no trustworthy answer source is discarded, not patched with a generated answer. This is the operational form of Chapter 2's "labels and rationales are forbidden as eval gold" cell. Generate to expand the questions; anchor the answers in human judgment, an extractive check, or an executable verifier, never in the generator.
Isolation by construction, not by hope
Evaluation isolation, CAREFUL's E, must be a property the system enforces, not an intention the team holds. Three mechanisms, in increasing strength:
**A never_train_on flag, enforced at the data layer. ** Every eval example carries the flag; the training data loader filters it out and fails loudly if it ever sees one.
-- The training loader's guard query. If this returns ANY rows, the build aborts.
SELECT example_id
FROM generated_example
WHERE intended_use = 'train'
AND (eval_exclusion = TRUE OR example_id IN (
SELECT example_id FROM generated_example WHERE intended_use = 'eval'));
-- A non-empty result is a contamination incident, not a warning.**A train/eval leakage scan, exact and semantic. ** Before every training run, scan the training set against the eval set for exact matches (Chapter 3) and near-duplicates (Chapter 7). The contamination literature is explicit that exact-match alone is insufficient because paraphrase and cross-lingual leakage slip through, so the semantic scan is mandatory, not optional.
**A generator-provenance check on the eval set. ** The subtlest and most-skipped: verify that no eval example was generated by a model in the system's training lineage. This requires the generator_model provenance of Chapter 3. If the eval was generated by the same family the model was distilled from, it is contaminated even with zero overlap, and only the provenance record reveals it.
def assert_eval_isolation(eval_set, training_lineage_models: set) -> None:
leaked = [e for e in eval_set
if e.source_type == "synthetic"
and e.generator_model in training_lineage_models]
if leaked:
raise EvalContamination(
f"{len(leaked)} eval items generated by a model in the training lineage "
f"{training_lineage_models}; eval is contaminated by construction.")What evaluation gold should actually be
If synthetic data is a poor ruler, what is a good one? The chapter's constructive answer, in priority order:
- Real user query logs, where volume exists and privacy permits. This is the gold standard because it is the distribution you serve. The constraints are real, privacy, consent, sampling bias toward existing users, but where logs can be used, no synthetic eval beats them for measuring production reality. The Chapter 1 team had a year of real tickets; a held-aside, human-labeled slice of those would have caught the failure on day one.
- Human-labeled eval sets, built deliberately to cover the distribution including its hard tail and unanswerable cases. Expensive, slow, and the most trustworthy thing you can build. The TruthfulQA benchmark is the model here: human-crafted to probe exactly the failure (confident falsehoods) that a model-generated eval would miss, because the generator shares the misconception.
- Synthetic adversarial evals, as a supplement for coverage of rare and dangerous cases, never as the primary metric. Generated edge cases and red-team prompts (Chapter 5) expand what you test, and because they are checked by humans or executable verifiers rather than generated answers, they can be trustworthy for the narrow thing they probe.
The ordering is the point. Real logs and human labels are the anchor; synthetic evals are a supplement for coverage. Inverting that order, making the synthetic eval primary and the human eval a rare spot-check, is how teams end up optimizing the treadmill.
A synthetic-eval acceptance protocol
When you do build a synthetic eval (for coverage of cases real data is too sparse to provide), it must pass a human acceptance gate before it is allowed to be a metric, well beyond what a generic harness like the OpenAI Evals guide automates for you. This is the protocol:
- Generate questions only; anchor every answer in a human, an extractive check, or an executable verifier.
- Run the leakage scans (exact, semantic, generator-provenance). Any hit aborts.
- Have humans accept the eval set: each item is reviewed for whether the question is realistic, the gold is correct, and the difficulty is representative (Chapter 6's difficulty axis applies to evals too, a synthetic eval that is all easy questions is as misleading as easy training data).
- Record the eval in a manifest with
never_train_on = true, the gold source per item, and the human acceptance record. - Run it alongside a real or human-labeled eval, never instead of one, and watch for divergence between the two: divergence is your early warning that the synthetic eval is drifting from reality.
Step 5 is the safety harness. A synthetic eval that tracks the real eval is earning trust; a synthetic eval that diverges from the real eval is showing you its fingerprints, and you should believe the real eval. As long as both exist, the synthetic eval can expand coverage without becoming a treadmill, because reality is still in the loop holding the synthetic ruler to account.
Chapter summary
Synthetic data is most dangerous as the ruler: a wrong training example costs signal, but a wrong evaluation example destroys your ability to detect that anything is wrong, errors in training degrade the system, errors in evaluation blind you to it. Synthetic evals lie in four compounding ways: they encode the generator's assumptions about what is askable, bake in hidden answerability assumptions when question and answer come from one pass, contaminate benchmarks by construction when generated by a model in the training lineage (invisible to exact-match checks, surviving paraphrase and translation), and create a treadmill where teams overfit to synthetic style while diverging from reality. The key distinction: generating questions expands coverage at low risk, but generating answers corrupts the ruler, so anchor every eval answer in a human, an extractive span, or an executable verifier, and discard questions with no trustworthy gold rather than fabricating one. Isolation must be enforced by construction, a never-train-on flag that aborts the build, exact and semantic leakage scans, and a generator-provenance check, not held as an intention. Good gold is, in order, real user logs, deliberately human-labeled sets (TruthfulQA as the model), and synthetic adversarial evals strictly as a supplement; inverting that order is how teams optimize the treadmill. When a synthetic eval is built, it passes a human acceptance protocol and runs alongside a real eval so divergence between the two becomes an early warning that the synthetic ruler is showing its fingerprints.