Introduction: The Sentence That Should Make You Nervous
There is a sentence that gets said in planning meetings, slack threads, and grant applications, and it should make you nervous every time you hear it:

Key Takeaways
- The Sentence That Should Make You Nervous treats synthetic data as a governed artifact, not a free replacement for reality.
- The safe use depends on the cell: training, evaluation, red-team, demo, privacy, or lineage all need different gates.
- Generated data earns its keep only when a real anchor, verifier, and owner survive after generation.
Research spine: this chapter stays grounded in Self-Instruct filtering and data-contamination literature, then applies that evidence to the operating judgment in the book. There is a sentence that gets said in planning meetings, slack threads, and grant applications, and it should make you nervous every time you hear it:
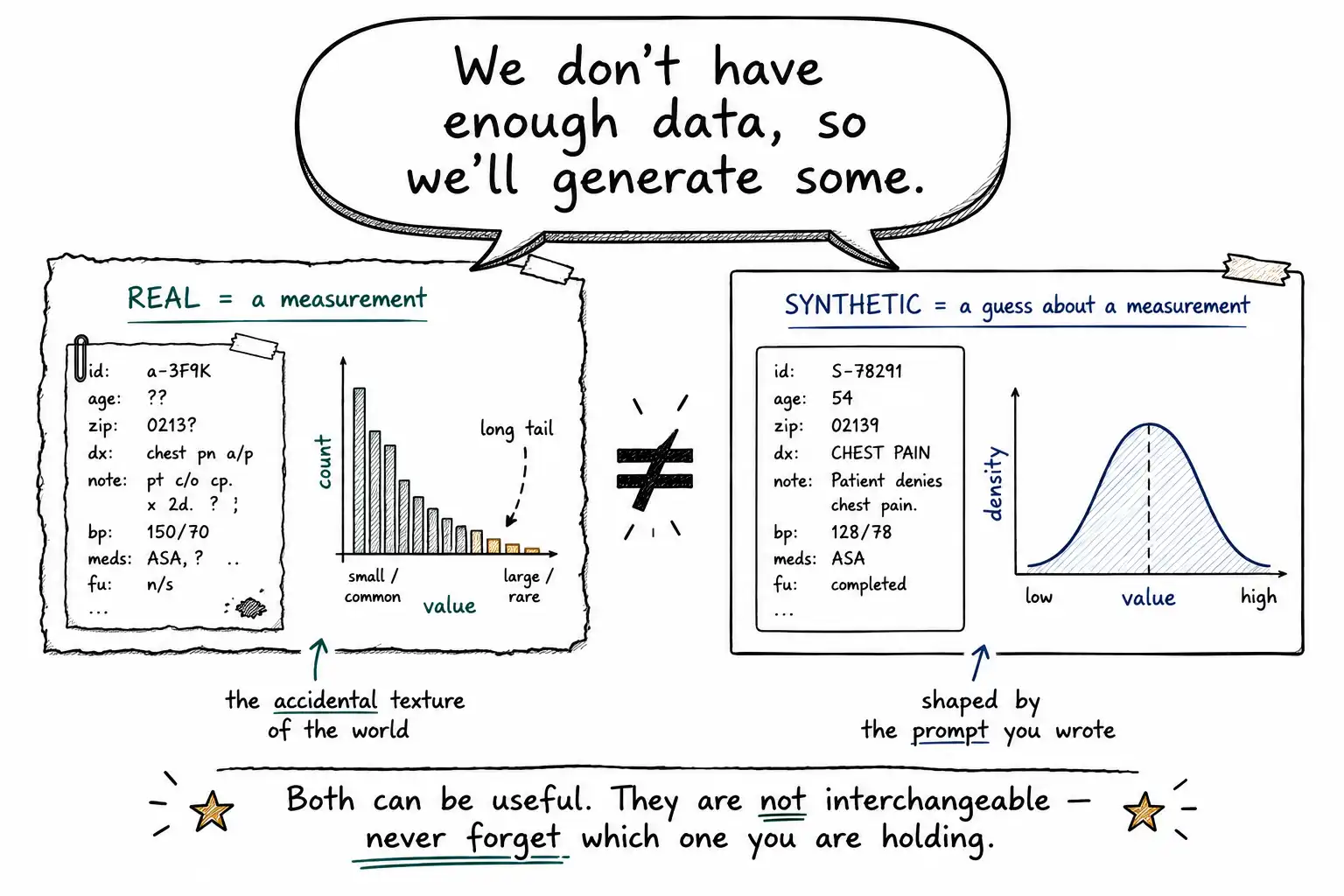
"We don't have enough data, so we'll generate some."
The sentence is not wrong. It is incomplete in a way that hides its most important assumptions. It treats "data" as a single substance, fungible across its sources, as if a row produced by a model and a row produced by reality were the same kind of thing as long as the columns line up. They are not. A row from reality is a measurement: something happened, somebody recorded it, and the record carries the accidental texture of the world, the typos, the terse phrasing, the cases nobody anticipated, the long tail that no schema predicted. A row from a model is a guess about what such a measurement might look like, drawn from a distribution the model learned and shaped by the prompt you happened to write. Both can be useful. They are not interchangeable, and the entire discipline of using synthetic data carefully is the discipline of never letting yourself forget which one you are holding.
This book is built around one image. A generated dataset is a mirror with fingerprints. Point a model at a task and ask it to produce examples, and what comes back is a reflection, of the model's training distribution, of its preferred register, of the assumptions baked into your prompt. The reflection can be genuinely useful. A mirror shows you the back of your own head. It can reveal a class you under-sampled, a phrasing your real users gave you but your labelers normalized away, a failure mode your logs were too sparse to capture. But the glass is never clean. The generator's blind spots, its house style, its tendency to over-explain, its quiet flattening of the rare and the weird, those are fingerprints, and they are smeared across every example unless someone deliberately measures and wipes them off. A mirror you never clean does not show you the world. It shows you the last model that breathed on it.
The trap, stated plainly
The enemy of this book is a belief, and the belief is seductive because it is half true:
Synthetic data is free training signal.
Here is the true half. Generation is cheap now. You can produce ten thousand examples in an afternoon for the price of a few API calls, where collecting and labeling ten thousand real examples might take a quarter and a budget line. For specific, bounded gaps, a rare class you need a few hundred more of, an edge case your test suite never covers, a paraphrase set to make a classifier robust to surface variation, that cheapness is a real superpower. Some of the most important models of the last few years were built on heavily synthetic or model-curated data, and they were not flukes. We will look at them honestly.
Here is the false half."Cheap to produce" is not "free." The cost did not disappear; it moved. It moved downstream, into evaluation you can no longer trust because the test set leaked from the same generator, into a model that learned the generator's writing style instead of the customer's, into a distribution whose tails quietly evaporated after a few rounds of training on its own output, into a dataset nobody can audit two quarters later because no one recorded how it was made. The bill for synthetic data is almost never paid at generation time. It is paid later, by someone who did not generate it, in a currency, trust, distribution coverage, auditability, that is much harder to refund than API credits.
What this book is, and is not
This is not a privacy-preserving synthetic-tabular-data textbook. It is not a "generate 10,000 examples with an LLM and fine-tune" tutorial. It is not a manifesto that model-trained-on-model-output is always doom. And it is emphatically not a blanket warning against synthetic data, that position is as lazy as uncritical enthusiasm, just lazy in the other direction.
It is a field guide to controlled use. It is organized around the lifecycle of generated data, because that is where the decisions actually live:
purpose → generation → filtering → labeling → evaluation → training → monitoring → retirement
Each stage has its own failure modes and its own controls. A team that nails generation and skips filtering ships polished garbage. A team that filters beautifully but lets the eval set share a generator with the training set ships a model that scores 0.94 offline and falls over in week one. A team that does everything right but records nothing about how the data was made hands a time bomb to whoever inherits the system. The lifecycle view is what keeps "we'll generate some data" from collapsing into a single, unexamined act.
Throughout, the book insists on distinctions that get blurred in casual use. Training data and evaluation data are different products with opposite contamination rules: you want training data diverse and you want eval data isolated, and a generated example that helps one can quietly ruin the other. Red-team data, demo data, and synthetic documentation each have their own risk profile, a fabricated customer name is harmless in a demo, a liability in a fine-tuning set, and a contamination vector in an eval. These are not pedantic categories. Confusing them is how good teams ship bad systems.
The framework you will see throughout
To keep the lifecycle from becoming a checklist nobody reads, the book carries one recurring question set, named so it is easy to invoke in a design review. It is CAREFUL:
- **C: Clear purpose. ** Why generate this, and what gap does it fill that reality cannot fill faster?
- **A: Anchored reality. ** What real data or human knowledge keeps the dataset honest?
- **R: Recorded provenance. ** Can every example be traced to generator, prompt, seed, parameters, and reviewer?
- **E: Evaluation isolation. ** Is the eval set protected from training contamination by construction?
- **F: Filtering gates. ** What automated and human gates decide inclusion, and what gets rejected and kept?
- **U: Use limits. ** What is this dataset forbidden from being used for?
- **L: Lifecycle monitoring. ** How will post-deployment failures be caught, and when is the dataset retired?
CAREFUL is a lens, not a liturgy. You will not find it stamped as a subsection in every chapter. You will find its letters doing work where they matter, provenance in the chapters on lineage and manifests, evaluation isolation in the chapter on contamination, lifecycle monitoring where we talk about collapse and drift.
How to read the chapters
Each chapter opens with a working claim, lists the specific sources it leans on, and then does its own thing: some open with an incident, some with a schema, some with a distribution that misbehaves, some with a disagreement between two judges. They end with a placed visual prompt and a short summary. They are deliberately different shapes, because the subjects are different shapes, and a book that forces every chapter into the same mold teaches you the mold instead of the material.
The code is data-engineering code, not model-demo code. You will see lineage schemas, manifest formats, deduplication and near-duplicate checks, distribution-comparison metrics, a synthetic-versus-real diagnostic classifier, eval-leakage detectors, judge-disagreement analysis, a model-collapse simulation, and dataset release manifests. There is very little "call the API and print the answer, " because that is not where synthetic data goes wrong. It goes wrong in the parts nobody photographs for the demo: the provenance you didn't record, the duplicates you didn't catch, the test set you didn't isolate, the tail you didn't notice disappearing.
By the last chapter, the goal is a change in reflex. Today, when a team hits a data wall, the reflex is "can we generate more?" After this book, the reflex should be two questions instead of one: what reality anchors this data, and what damage could it do if we are wrong? Hold the mirror up if you must. Just remember to check it for fingerprints before you believe what it shows you.