Playbooks II: RAG Evaluation, Fine-Tuning Tone, Low-Resource, Code, and Cautious Domains
> **Working claim: ** The careful-use principles scale across very different tasks, but the safe synthetic ratio, the right verifier, and the human-review level swing enormously between them.

Key Takeaways
- Playbooks II: RAG Evaluation, Fine-Tuning Tone, Low-Resource, Code, and Cautious Domains treats synthetic data as a governed artifact, not a free replacement for reality.
- The safe use depends on the cell: training, evaluation, red-team, demo, privacy, or lineage all need different gates.
- Generated data earns its keep only when a real anchor, verifier, and owner survive after generation.
**Working claim: ** The careful-use principles scale across very different tasks, but the safe synthetic ratio, the right verifier, and the human-review level swing enormously between them. Code generation can lean heavily synthetic because correctness is executable; medical and legal generation can lean almost not at all, because being wrong is harmful and verification is expensive.
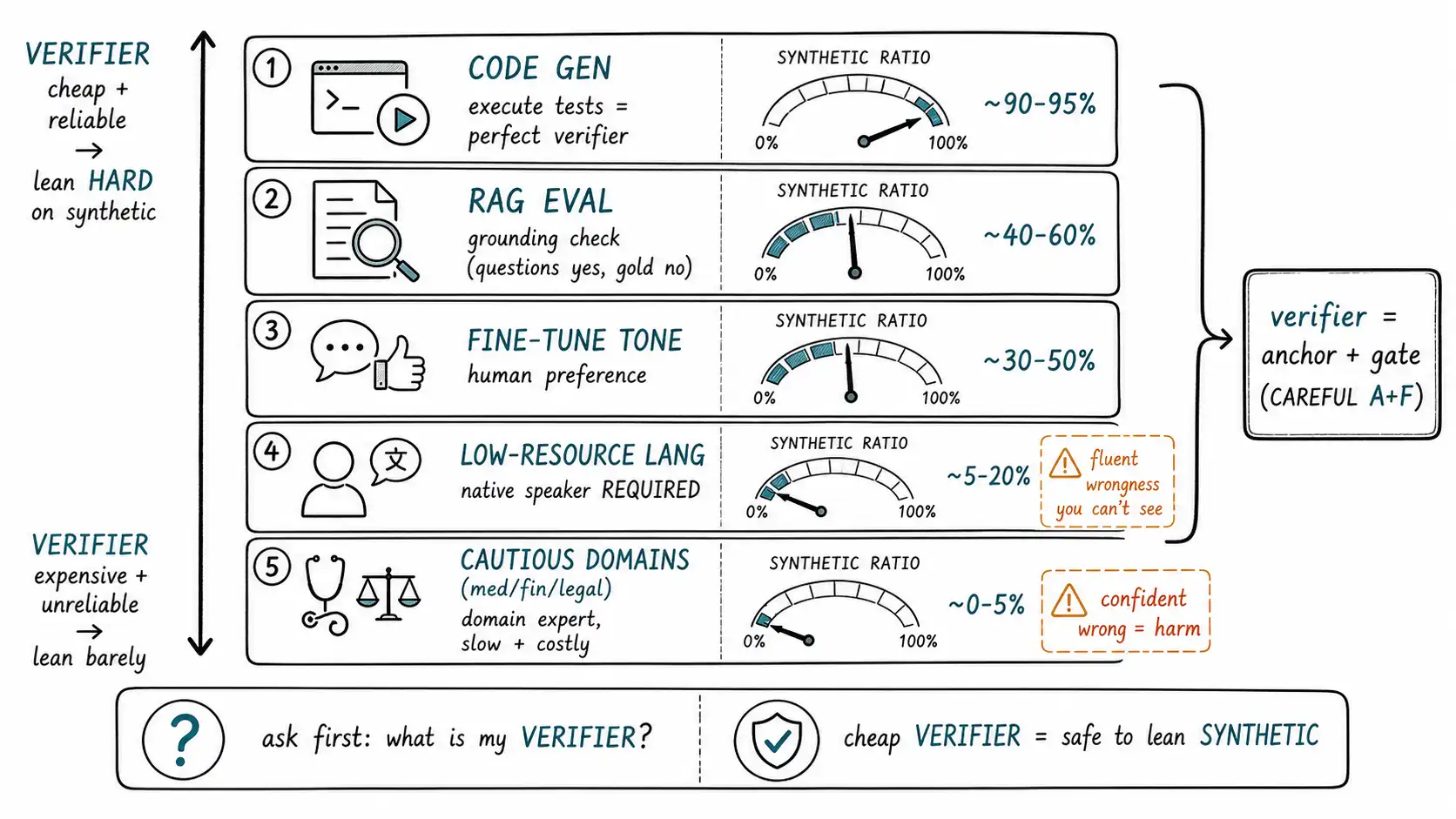
The verifier determines the safe ratio
The unifying idea of this second playbook chapter is a single lever: **how cheaply and reliably can you verify a generated example? ** That lever sets how heavily a task can lean on synthetic data. Code has an executable verifier, run the tests, so it tolerates a high synthetic ratio. RAG evaluation has a grounding verifier, is the answer in the retrieved context, so it tolerates synthetic questions but not synthetic gold answers. Medical advice has no cheap verifier and a high cost of error, so it tolerates almost no synthetic data in the answer position. Read each playbook below as a different point on the verifier axis.
Playbook: RAG Evaluation Query Generation
Building evaluation sets for retrieval-augmented systems, questions over a document corpus, is a common, high-value use of generation, because hand-writing thousands of questions over a knowledge base is expensive.
- **Helps with: ** Generating questions over your corpus at scale to test retrieval coverage, questions touching documents and sections your real query logs never reached.
- **Cannot replace: ** Real user questions, which are messier, more ambiguous, and more often unanswerable than generated ones. And it cannot supply trustworthy answers, the answer is the ruler, and a generated ruler corrupts (Chapter 9).
- **Generation design: ** Generate questions grounded in specific passages, recording which passage each question targets (so retrieval can be scored). Crucially, also generate unanswerable questions, questions the corpus does not cover, because real RAG systems must decline these, and a synthetic eval of only answerable questions over-rewards confident answering.
- **Required filters: ** RAGAS-style checks, context relevance (is the target passage actually relevant to the question?) and answerability (is the question answerable from the corpus, or is it a deliberate unanswerable?). De-duplicate questions; many generated questions are trivial rephrasings.
- **Human review level: ** Medium. Humans verify that answerable questions have correct gold (gold = human or extractive, never generated) and that unanswerable questions are genuinely uncovered.
- **Eval strategy: ** Score retrieval (did the system fetch the target passage?) separately from generation (was the answer faithful to what was fetched?). Use RAGAS-style faithfulness and context-relevance as automated supplements to a human-labeled core, and run the synthetic eval alongside a real-query eval to watch for divergence (Chapter 9).
- **Failure risks: ** Hidden answerability assumptions (every question cleanly answerable); generated gold answers smuggling the generator's errors into the metric; over-findable answers; treating the synthetic eval as primary instead of supplementary.
Playbook: Fine-Tuning Support Tone
Generating examples to teach a model a desired style, a support assistant's tone, a brand voice. Here the target is stylistic, not factual, which changes the risk profile interestingly.
- **Helps with: ** Demonstrating consistent tone across many scenarios, far more examples of "how we'd phrase this" than humans will write. Style is something generators do well, and tone is a forgiving target because there is no single correct answer.
- **Cannot replace: ** Human judgment about what good tone is for your brand and your users. The InstructGPT lesson applies directly: the human preference signal is the anchor for what "good" means; generation can scale demonstrations of a standard humans defined, not define the standard itself.
- **Generation design: ** Anchor on human-written exemplars of the target tone, then generate variations across scenarios. Keep the content grounded (don't let tone generation invent facts or policies), separate the "what to say" (factual, grounded) from the "how to say it" (stylistic, generatable).
- **Required filters: ** Tone-consistency check (does the example match the target style?); a factual-grounding guard so tone examples don't fabricate product facts or policies; dedup.
- **Human review level: ** Light-to-medium, focused on whether the tone is right and whether any facts crept in. Tone is subjective, so a small human panel calibrates "on-brand" rather than one reviewer deciding.
- **Eval strategy: ** Human preference evaluation (which response is more on-tone?) on a held-out set, plus a guard that fine-tuning for tone did not degrade factual accuracy, a common side effect, where the model learns to sound confident and helpful at the cost of correctness.
- **Failure risks: ** Tone homogenization (every response sounds identical and robotic); fabricated facts smuggled in under the cover of style; over-fitting to a synthetic tone that real users find off-putting; the confidence-over-correctness drift.
Playbook: Low-Resource Language Augmentation
Generating data for languages or dialects with little real data: a genuinely valuable use, and one with a sharp ethical and quality edge.
- **Helps with: ** Bootstrapping coverage where real data is scarce, expanding a thin corpus, generating parallel examples for translation or classification in under-served languages, the seed-and-bootstrap move Self-Instruct pioneered, applied to a far less forgiving setting.
- **Cannot replace: ** Native-speaker reality. This is the most important "cannot replace" in the chapter: a generator's competence in low-resource languages is often much worse than in high-resource ones, so it produces fluent-looking but subtly or grossly wrong text, and the team that most needs the data is least able to evaluate it. The mirror's fingerprints are heaviest exactly where you can see them least.
- **Generation design: ** Anchor on real native-speaker data, even if scarce. Prefer generation that transforms real examples (paraphrase, format variation) over generation from scratch, because transformation stays closer to real grounding. Be explicit that the generator's low-resource competence is suspect.
- **Required filters: ** Native-speaker review is non-negotiable, automated filters cannot assess fluency or correctness in a language the team does not speak; back-translation consistency as a weak signal only.
- **Human review level: ** High, and it must include native speakers. This is the case where you cannot substitute a model judge for a human, because the model shares the generator's weakness in the language. Budget for native-speaker review or do not generate.
- **Eval strategy: ** Native-speaker-labeled eval; never evaluate low-resource generation with a model from the same family that generated it (it will approve its own errors, the shared-fingerprint trap at its worst).
- **Failure risks: ** Fluent wrongness that non-speakers can't catch; cultural and dialectal errors; amplifying the generator's bias in under-represented languages; and the meta-risk that the data scarcity that motivated generation also prevents proper evaluation.
Playbook: Code Task Generation
The task that can lean hardest on synthetic data, because correctness is executable.
- **Helps with: ** Generating coding problems, test cases, and solutions at scale, and, uniquely, verifying them automatically by execution. This is where high synthetic ratios are genuinely safe, because the verifier (run the code against tests) is cheap, reliable, and objective.
- **Cannot replace: ** Real-world code messiness, legacy constraints, ambiguous requirements, the gap between "passes tests" and "is correct/maintainable." Executable verification proves a solution passes given tests; it does not prove the tests are complete or the problem is realistic.
- **Generation design: ** Generate problem + solution + tests, then execute to verify the solution passes its tests (Chapter 5's rationale rule made concrete). Discard anything that doesn't run or pass. Generate diverse difficulty and avoid the generator's tendency toward toy problems.
- **Required filters: ** Execution-based verification is the star filter, run it, keep only what passes; static analysis; dedup (generators produce many near-identical problems); a check that tests actually exercise the solution (not trivially-passing tests).
- **Human review level: ** Low for correctness (the executor handles it), but medium for realism and coverage, humans check that problems resemble real tasks and that test suites are meaningful, since "passes its own tests" is a weak bar if the tests are weak.
- **Eval strategy: ** Execution-based eval on held-out problems, ideally including real-world-derived tasks; measure pass rates and guard against the eval problems leaking into training (a serious contamination risk in code, where benchmark leakage is rampant per the contamination survey).
- **Failure risks: ** Toy-problem monoculture; weak test suites that pass trivially; benchmark contamination; and the gap between executable correctness and real-world quality.
Playbook: Cautious Domains (Medical, Finance, Legal)
The task that can lean least on synthetic data in the answer position, because being wrong is harmful and verification is expensive and slow.
- **Helps with: ** Format variation, de-identified document structure, and non-clinical/non-advisory scaffolding, e.g., varying how a form is laid out, or generating structure without generating substance. Generation can help with the envelope, not the content.
- **Cannot replace: ** Expert-verified ground truth. In these domains a generated answer that is plausibly wrong is a liability, and a model from the same family that judges it shares the error (the TruthfulQA failure with real-world stakes). There is no cheap verifier for "is this medical advice correct."
- **Generation design: ** Generate only what can be expert-verified or what carries no advisory weight (structure, format, de-identified scaffolding). Never generate substantive answers as gold without expert review. Treat synthetic rationales here as the most dangerous artifact in the book (Chapter 5), a fluent wrong clinical or legal rationale is actively harmful.
- **Required filters: ** Expert review gate (domain professional, not a model judge); PII/PHI scanning (Chapter 12) at the highest sensitivity; compliance review (Chapter 13) as an early gate.
- **Human review level: ** **Highest: ** qualified domain experts, with second-approver sign-off (Chapter 13's high-risk path). Model judges are advisory at most.
- **Eval strategy: ** Expert-labeled gold only; synthetic evals as coverage supplements that an expert has accepted; strict eval isolation; conservative metrics that penalize confident wrongness heavily.
- **Failure risks: ** Plausible-but-wrong substantive content; expert-shortage tempting teams to substitute model judgment for human; PHI leakage; compliance violations; and the catastrophic case of confident, fluent, wrong advice trained from synthetic rationales.
The verifier axis, summarized
The five playbooks line up cleanly on the verifier axis, and the synthetic ratio they can safely bear tracks it directly.
| Task | Verifier | Verifier cost/reliability | Safe synthetic lean | Human role |
|---|---|---|---|---|
| Code generation | Execute against tests | Cheap, reliable, objective | High | Realism/coverage check |
| RAG eval (questions) | Grounding in corpus | Cheap (RAGAS-style) | Medium (questions yes, gold no) | Verify gold + unanswerables |
| Fine-tuning tone | Human preference | Medium, subjective | Medium | Calibrate "good", guard facts |
| Low-resource language | Native speaker | Expensive, scarce | Low-medium | Non-negotiable native review |
| Cautious domains | Domain expert | Expensive, slow | Very low (substance) | Highest, expert + 2nd approver |
The table is the chapter in one view: the cheaper and more reliable the verifier, the more synthetic data you can safely use, because verification is what converts a generated guess into a verified asset. Code sits at the top because execution is the perfect verifier; cautious domains sit at the bottom because there is no cheap verifier for correctness and the cost of being wrong is high. Every other task falls between, and a team's first question for any new task should be "what is my verifier, and how cheap and reliable is it?", because that answer, more than any general rule, sets how carefully this particular synthetic data must be handled, the kind of risk-tiering by context and consequence that the NIST AI Risk Management Framework asks teams to make explicit. This is CAREFUL's A (anchored reality) and F (filtering gates) fused: the verifier is the anchor and the gate at once.
Chapter summary
A single lever unifies these five playbooks: how cheaply and reliably you can verify a generated example sets how heavily the task can lean on synthetic data. RAG evaluation generates questions (including deliberately unanswerable ones to test declining) grounded in specific passages, scores retrieval separately from generation, uses RAGAS-style checks as automated supplements to human gold, and never generates the gold answer. Fine-tuning tone leans on generation for stylistic demonstrations anchored to human exemplars while separating generatable "how to say it" from grounded "what to say, " guarding against fabricated facts and confidence-over-correctness drift. Low-resource language augmentation is valuable but treacherous because the generator's competence is worst exactly where the team can least evaluate it, making native-speaker review non-negotiable and same-family model judging the worst trap. Code generation can lean hardest on synthetic data because execution is a cheap, reliable, objective verifier, generate problem/solution/tests and keep only what runs and passes, with humans checking realism and test quality rather than correctness. Cautious domains (medical, finance, legal) can lean least in the answer position because there is no cheap verifier for correctness and wrong-but-fluent content is harmful; generate only expert-verifiable structure, never substantive gold without expert review, with the highest human review and second-approver sign-off. The verifier axis summarizes it: cheaper, more reliable verification permits more synthetic data because verification converts a guess into an asset, the verifier is simultaneously CAREFUL's anchor and gate, and a team's first question for any task should be "what is my verifier, and how good is it?"