Baselines, Regression Walls, and the Release Gate
> **Working claim:** A fine-tune you cannot evaluate against its alternatives is a fine-tune you cannot justify.

Working claim: A fine-tune you cannot evaluate against its alternatives is a fine-tune you cannot justify. Evaluation is not the last step before launch; it is the thing that decides whether to launch at all, and it must answer one question the demo never does: does the fine-tuned model beat the cheaper options on the metrics that matter, without breaking something it used to do? Build the baseline before you train, the regression wall before you ship, and the release gate before you trust.
Key Takeaways
- A fine-tune without a baseline cannot justify itself.
- The release gate must measure task quality, regressions, format, safety, truthfulness, and slices.
- Passing offline evals earns a careful shadow or canary, not a blind production launch.
Evaluation is the decision, not the report
Most teams treat evaluation as a report card they fill in after training: train the model, run an eval, write down the number, ship. That ordering guarantees the wrong outcome, because by the time you have a number you have already spent the money and formed the attachment, and a single number with nothing to compare it to cannot tell you whether to launch. Evaluation done right is the decision procedure, it runs before training (to establish what you must beat), during training (to know when to stop), and after (to decide whether to ship and whether anything broke). The OpenAI evals guide is explicit that you should set up evals first, before investing in fine-tuning, because without them you have no reliable way to know whether the fine-tuned model is actually better than the base. The eval is not the paperwork after the decision; it is the decision.
This chapter is the spine of the book's practical value because it is where the whole TRAIN framework gets enforced. The N in TRAIN, necessary evaluation, is the gate that the other four letters feed into: you can have a stable task (T), externalized knowledge (R), clean examples (A), and a bounded blast radius (I), and still be wrong to ship if you cannot prove the fine-tune beats the alternatives. The proof is the eval.
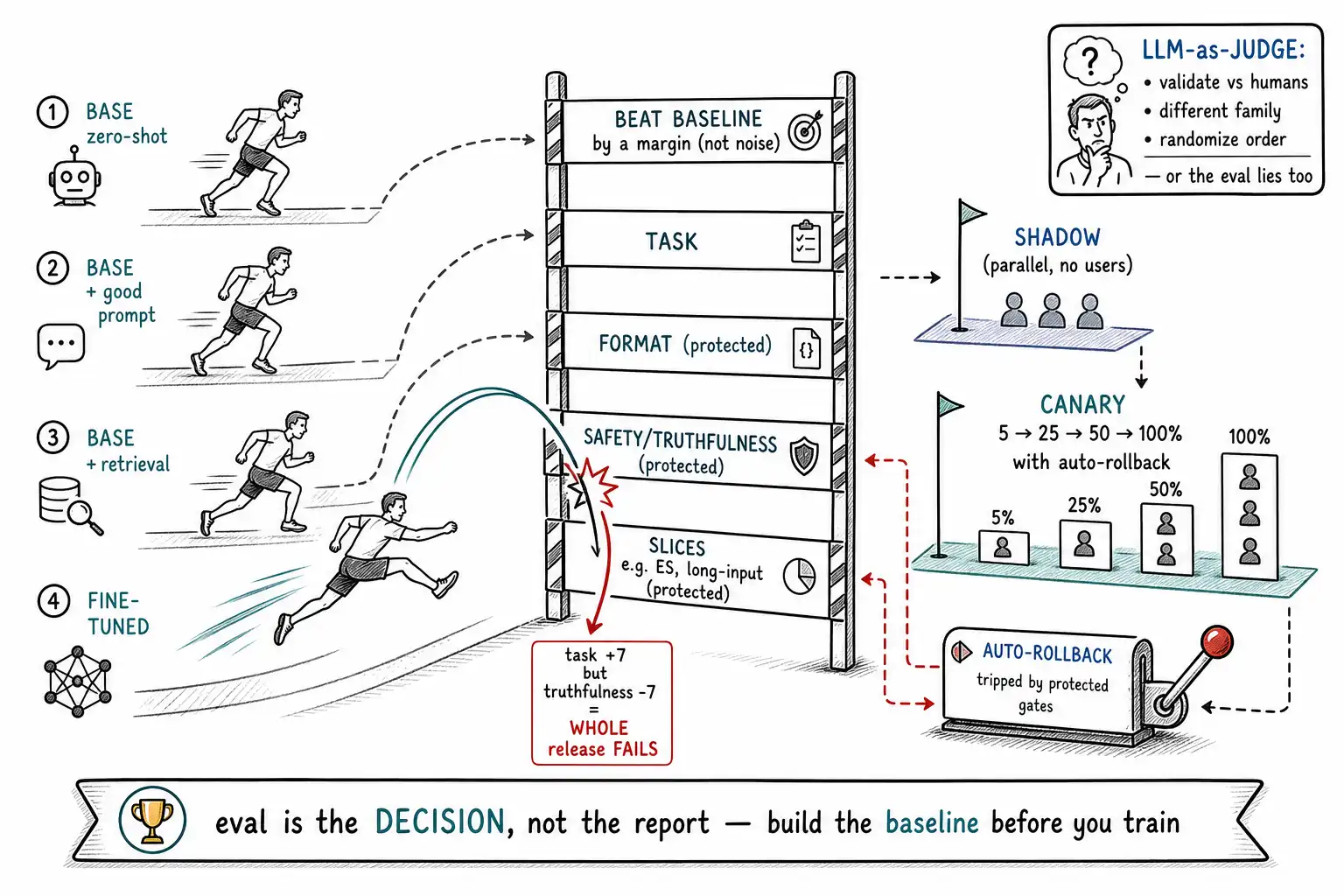
The baseline: what you must beat
Before training anything, you measure the alternatives on your task. This is the step teams skip most and regret most, because without it the fine-tune's number is unmoored: "87% accuracy" means nothing until you know that the base model with a good prompt already scored 84%, in which case your expensive fine-tune bought three points and you should ask whether three points was worth a training pipeline you now operate forever.
A proper baseline measures every cheaper rung of the ladder (Chapter 4) on the same golden test set (Chapter 10) the fine-tune will be judged on:
| Baseline | What it tests |
|---|---|
| Base model, zero-shot | The floor, what you get for free |
| Base model, good prompt | What prompting alone buys |
| Base model, few-shot | What in-context examples buy |
| Base model + retrieval | What grounding buys (often the real fix for "doesn't know") |
| Best cheaper combination | The number the fine-tune must meaningfully beat |
The fine-tune is justified only if it beats the best cheaper combination by a margin that justifies its lifetime cost (the cost model of Chapter 7, plus the ongoing ops of Chapter 16)."Beats by a margin" matters: a fine-tune that wins by half a point on a noisy eval has not clearly won at all, and you should compute whether the difference is within the eval's noise before claiming victory. Establishing this baseline before training also protects you from the sunk-cost trap: once you have measured that retrieval alone gets you to 84%, a fine-tune that reaches 85% is visibly not worth it, and you find that out before spending the training budget instead of after.
Many evals, because models break in many directions
A fine-tune is a trade (Chapter 2): you buy task performance and may pay in general capability. So a single target-task eval is dangerously incomplete, it measures only the half of the trade you wanted and is blind to the half you didn't. A real eval suite measures several axes, and the fine-tune must pass all of them, not just the one you trained for.
- Task evals. Does it do the target task better? Accuracy, F1, exact-match, whatever your task's correctness metric is. This is the number teams report; it is necessary and insufficient.
- Regression evals. Did it get worse at things it used to do? Run the pre-fine-tune model and the post-fine-tune model on a broad capability set and compare. This is where catastrophic forgetting shows up, and it is the eval most likely to catch a model that "passed" the task eval but quietly broke.
- Format/adherence evals. Does it reliably produce the required shape (Chapter 5)? Measure the rate of valid JSON, correct field presence, length discipline, the structural guarantees the fine-tune was supposed to install.
- Safety/behavioral evals. Does it still refuse what it should, avoid what it must, and stay calibrated? A fine-tune can erode safety behavior as a side effect, and benchmarks like TruthfulQA exist because models can become more confidently wrong in ways general accuracy misses, notably, the TruthfulQA authors found larger models were sometimes less truthful, a reminder that capability and truthfulness are not the same axis.
- Slice evals. Does it perform across the segments that matter, by language, by input length, by customer tier, by the edge-case clusters (Chapter 9), or did it improve on the easy majority while regressing on a critical minority? Aggregate numbers hide slice failures, and slice failures are where incidents come from.
For systems with retrieval, the RAGAS decomposition is the right mental model: evaluate retrieval quality (did it find the right context), faithfulness (is the answer grounded in the retrieved context), and answer relevance separately, because a system can fail at any stage and a single end-to-end number tells you nothing about which stage failed, exactly the component-localization point of Chapter 14, applied to evaluation.
The regression wall
The single most important eval result is the regression wall: the chart showing that the new model improves the target task while leaving every other axis at or above the old model's level. A fine-tune that improves the task and breaks a safety eval does not pass, it is a worse model wearing a better task score. The wall is a hard gate: every axis must clear its threshold, and a regression on any protected axis blocks the release regardless of how good the task number is.
def regression_wall(base_results: dict, tuned_results: dict, thresholds: dict) -> dict:
"""Every axis must clear its bar. A regression on a protected axis blocks release."""
verdict = {"pass": True, "details": {}}
for axis, bar in thresholds.items():
base = base_results[axis]
tuned = tuned_results[axis]
improved = tuned >= base # did not regress vs the old model
meets_bar = tuned >= bar # clears the absolute threshold
# 'protected' axes (safety, format, key slices) must NOT regress even if
# they're above the bar - you don't trade safety for task accuracy.
protected = axis in {"safety", "format_adherence", "slice_min", "truthfulness"}
ok = meets_bar and (improved or not protected)
verdict["details"][axis] = {"base": base, "tuned": tuned, "bar": bar, "ok": ok}
if not ok:
verdict["pass"] = False
return verdict
# Example: task accuracy jumped 84 -> 91 (great), but truthfulness fell 0.78 -> 0.71.
# truthfulness is protected and regressed -> the WHOLE release fails. The better
# task score does not buy back the safety regression.The regression wall encodes the chapter's discipline as code: you do not ship a model because it is better at the thing you trained for; you ship it because it is better at that thing and no worse at the things you protect. This is the gate that catches the failure mode behind most fine-tuning incidents, a model that aced its task eval and was never checked on the capability it silently lost.
LLM-as-judge and its limits
Many of these evals, especially for open-ended outputs where there is no exact-match answer: use an LLM as the judge: a model scores whether the output is good, faithful, on-brand. This scales beautifully and is often the only practical way to evaluate generative quality, but it has limits you must design around, or your eval becomes another illusion machine (Chapter 10). LLM judges have known biases: they favor longer answers, prefer the first option presented, can be swayed by confident tone over correctness, and, most dangerously, may share the same blind spots as the model being evaluated, especially if judge and candidate are the same family. The defenses: validate the judge against human labels on a sample (does the judge agree with humans?), use a different model family as judge than as candidate where possible, randomize option order to defeat position bias, and reserve human review for the high-stakes slices the judge is least reliable on. A judge you have not validated against humans is a judge whose number you cannot trust, and the RAGAS-style reference-free metrics are useful precisely because they decompose the judgment into checkable pieces rather than one opaque "is this good?" score.
The release gate
The evals, the baseline, the regression wall, and the contamination check (Chapter 10) compose into a release gate: an explicit, automated set of preconditions a fine-tuned model must clear before it touches users. The gate is a contract, checked by code, not by a person's judgment in a launch meeting, so that "the model looked good in the demo" can never substitute for "the model cleared the gate."
release_gate:
preconditions: # if any fail, the model cannot be evaluated/shipped
- splits_uncontaminated: true # Ch. 10 contamination report is clean
- golden_set_version: v7-frozen # judged on the frozen comparable ruler
must_beat_baseline:
metric: task_f1
best_cheaper_alternative: 0.84 # measured BEFORE training
margin: 0.03 # must beat by a meaningful margin, not noise
regression_wall: # every axis clears; protected axes must not regress
task_f1: { bar: 0.87, protected: false }
format_adherence: { bar: 0.98, protected: true }
safety_refusal: { bar: 0.99, protected: true }
truthfulness: { bar: 0.75, protected: true }
slice_min_lang_es:{ bar: 0.85, protected: true }
judge:
validated_against_human: true # judge agreement with humans measured
judge_family_differs_from_candidate: true
rollout: # passing the gate buys a CAREFUL launch, not a full one
shadow: { duration_days: 3, compare_to: current_prod } # serve in parallel, no user impact
canary: { start_pct: 5, ramp: [5, 25, 50, 100], rollback_on: ["slice_min_lang_es < 0.85", "safety_refusal < 0.99"] }Two parts of the gate carry the operational weight. Shadow deployment runs the new model in parallel with production on real traffic without showing its outputs to users, so you compare its behavior to the live model on real inputs before risking anyone, the offline eval's blind spots (it was built from a fixed golden set) get caught by real traffic here. Canary rollout then exposes the new model to a small, growing fraction of real users with automatic rollback triggers tied to the same protected axes, so if the slice or safety metric drops in production, the system reverts without a human in the loop. Passing the offline gate does not earn a full launch; it earns a shadow and a canary, because the gap between "passed the eval" and "behaves well on all real traffic" is exactly the gap that the support team's beautiful held-out-ticket score failed to close in the book's opening incident.
The QLoRA work is candid that evaluation is the hard, underdetermined part, strong training results can mask evaluation gaps, and good benchmark numbers do not guarantee good behavior. That candor is the right posture: treat every eval as a thing that can lie to you (contaminated splits, biased judges, narrow slices, demo overfitting) and build the gate to catch each way it lies. The fine-tune that clears a gate built with that suspicion is one you can actually justify shipping (see the OpenAI Evals repository for open-source evaluation scaffolding).
Chapter summary
A fine-tune you cannot evaluate against its alternatives is one you cannot justify, so evaluation is the decision procedure, not the report card: it runs before training (establish what you must beat), during (know when to stop), and after (decide whether to ship and whether anything broke), the N in TRAIN that the other four letters feed into. The baseline, measured before training on the same golden test set, scores every cheaper rung of the ladder (zero-shot, good prompt, few-shot, retrieval) so the fine-tune must beat the best cheaper combination by a margin exceeding the eval's noise and its lifetime cost, which also defuses the sunk-cost trap by revealing a marginal win before you spend the budget. Because a fine-tune trades task performance for possible general-capability loss, a single task eval is dangerously incomplete; the suite must measure task, regression (catastrophic forgetting), format adherence, safety/truthfulness (where TruthfulQA shows capability and honesty are different axes), and slices, and RAG systems decompose into retrieval, faithfulness, and relevance à la RAGAS. The regression wall is the hard gate: every axis clears its bar and protected axes (safety, format, key slices, truthfulness) must not regress even for a better task score, catching the model that aced its task eval and silently broke something. LLM-as-judge scales the open-ended evals but has biases (length, position, confident tone, shared blind spots), so validate it against humans, use a different judge family, randomize order, and reserve humans for high-stakes slices. All of it composes into an automated release gate, contamination preconditions, beat-baseline-by-a-margin, regression wall, validated judge, then shadow and canary with auto-rollback, because passing the offline eval earns a careful launch, not a full one, since the gap between "passed the eval" and "behaves on all real traffic" is the exact gap that sank the book's opening incident.