Synthetic Data: When It Helps, When It Poisons
> **Working claim:** Synthetic training data, examples generated by a model rather than collected from reality, is the most powerful and most dangerous tool in the data toolkit.

Working claim: Synthetic training data, examples generated by a model rather than collected from reality, is the most powerful and most dangerous tool in the data toolkit. Used with verification and grounding, it solves coverage and labeling-cost problems nothing else can. Used naively, it teaches the model the generator's mistakes, narrows the distribution toward the generator's blind spots, and in the limit collapses the model. The discipline is the same throughout: synthetic data is a candidate, never a fact, until something real verifies it.
Key Takeaways
- Synthetic data is a candidate until a trustworthy verifier accepts it.
- Generated examples can amplify inherited errors, narrow distributions, and trigger model-collapse loops.
- Synthetic data works best when the output is cheap to check with code, retrieval, rules, or humans.
The temptation and the trap, in one breath
Synthetic data is irresistible for a simple reason: it makes the most expensive part of fine-tuning: building a clean, well-covered dataset, fast and cheap. Need a thousand examples of a rare edge case? Generate them. Need labels for ten thousand unlabeled inputs? Have a strong model label them. Need coverage of the negatives and refusals that nobody bothered to collect? Synthesize them. The technique genuinely works: Self-Instruct bootstrapped instruction-following data by having a model generate its own instructions and responses, and Stanford Alpaca used that approach to fine-tune a capable instruction-follower cheaply. Textbooks Are All You Need trained phi-1 substantially on synthetic "textbook-quality" exercises generated by a larger model and reached coding performance far above its weight class. Synthetic data is not a hack; it is a legitimate, sometimes superior, source.
The trap arrives in the same breath. A synthetic example is a model's guess at what a good example looks like, and a guess is not ground truth. If the generator is wrong, the example is wrong, and you have just manufactured a labeled error at scale. If the generator has a blind spot, every synthetic example shares it, and you have manufactured a systematic error, far worse than random noise because it points consistently in one wrong direction. And if you train a model on data generated by a model and repeat, each generation drifts further from reality, a degenerative loop that the Nature model-collapse study documented: models trained recursively on generated data lose the tails of the distribution, converge toward bland repetition, and eventually collapse. Synthetic data amplifies whatever the generator believes, including what it believes wrongly.
The three failure modes, named
To use synthetic data safely you must be able to name how it fails, because each failure has a different defense.
Inherited error. The generator is confidently wrong on some inputs, and every synthetic example for those inputs encodes the wrong answer. Because the error is consistent (the generator is reliably wrong the same way), the student learns it as a rule, not as noise to average out. This is the distillation hazard from Chapter 7 generalized: copying a teacher copies its mistakes. Defense: verify a sample of synthetic examples against ground truth or human review, especially on the slices where the generator is weakest.
Distribution narrowing. A generator does not sample reality; it samples its own most-likely outputs. Ask a model for "a thousand support tickets" and you get a thousand typical support tickets, the messy, weird, multilingual, adversarial real ones are underrepresented, because the model's mode is the bland center. Train on this and the model gets good at the center and worse at the tails, which is exactly backwards, because the tails are where it was already failing. Defense: deliberately prompt for diversity and edge cases, measure the synthetic distribution against the real one, and blend synthetic with real data so the tails survive.
Recursive collapse. The catastrophic limit: synthetic data trains a model whose outputs become synthetic data for the next model, and so on. The Nature study showed this loop degrades models generation over generation, rare events disappear first, then variance shrinks, then quality. Even one round of careless synthetic-on-synthetic does measurable damage; the loop just makes it cumulative. Defense: keep real data in every generation's mix, never train purely on the previous model's output, and treat "synthetic data from a model we also fine-tuned" with extra suspicion, because that is the loop forming.
| Failure mode | Mechanism | Defense |
|---|---|---|
| Inherited error | Generator's consistent mistakes become learned rules | Verify against ground truth on weak slices |
| Distribution narrowing | Generator samples its mode, not reality's tails | Prompt for diversity; measure vs. real; blend |
| Recursive collapse | Synthetic-on-synthetic loop degrades each generation | Keep real data in the mix; never train purely on prior output |
The grounding discipline: candidate, not fact
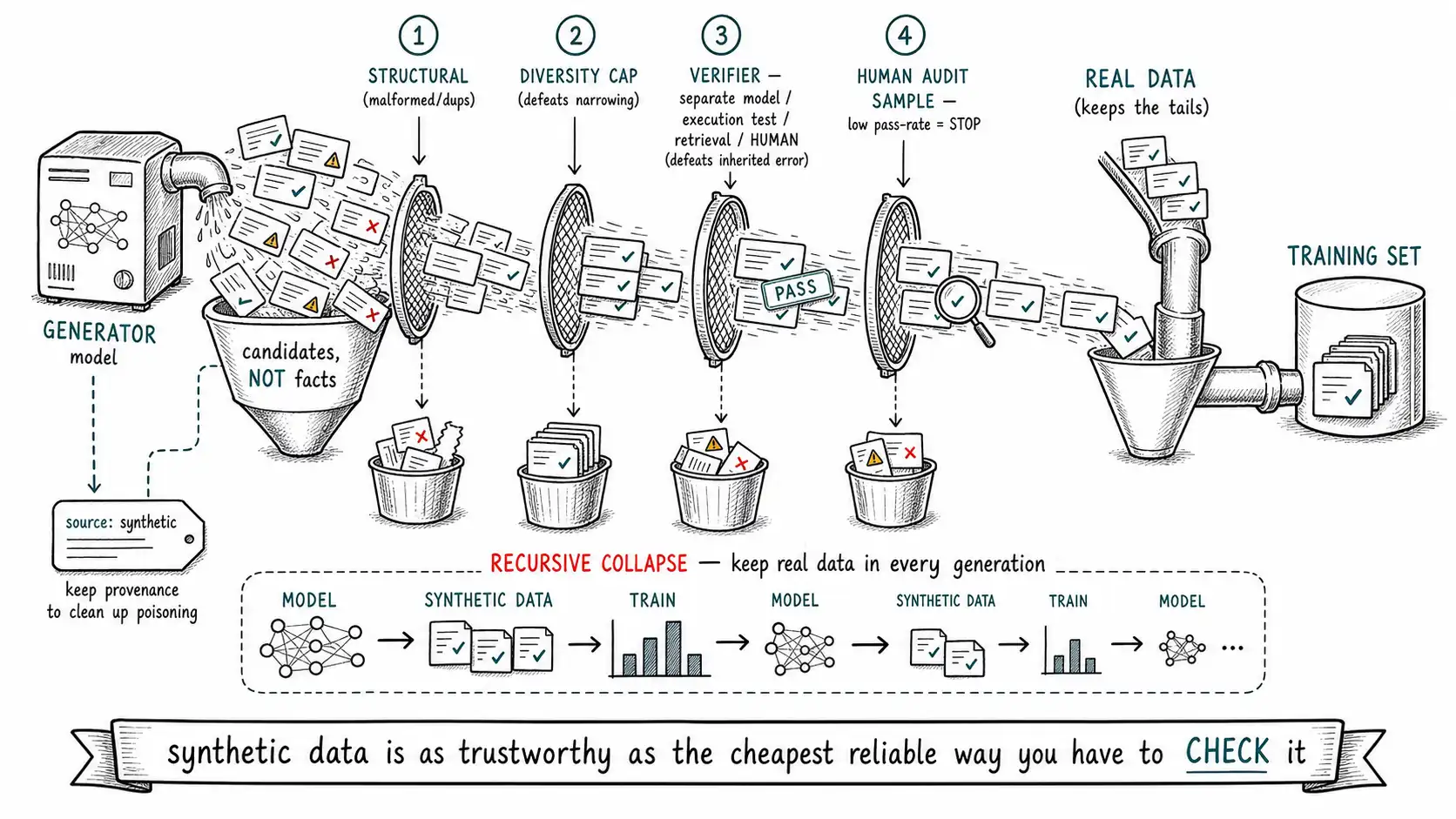
The single principle that makes synthetic data safe is the one from the memory and write-gate tradition: a synthetic example is a candidate until something real verifies it. You do not write a model's guess straight into the training set any more than you would write a model's guess straight into a database of facts. You generate candidates, filter them, verify a portion, and only then admit the survivors. Self-Instruct itself was not "generate and train", it was generate, filter aggressively (deduplicate, drop low-quality and invalid instructions), and then train, and the filtering was essential to the result. Synthetic data without a filter is not a dataset; it is an unaudited model output you are about to compile into weights.
A safe synthetic pipeline has verification built into its structure:
def synthetic_pipeline(prompts, generator, verifier, real_data, max_per_cluster=50):
"""Generate -> filter -> verify -> blend. Each stage removes a failure mode."""
candidates = []
for p in prompts:
for _ in range(3): # oversample, we'll filter hard
candidates.append({"input": p, "output": generator(p), "source": "synthetic"})
# 1. Structural filter: drop malformed, empty, duplicate (Ch. 9 validator)
candidates = drop_invalid_and_duplicates(candidates)
# 2. Diversity cap: defeat distribution narrowing - limit near-identical clusters
candidates = cap_per_semantic_cluster(candidates, max_per_cluster)
# 3. Verification: defeat inherited error. A SEPARATE check, not the generator.
verified = []
for c in candidates:
v = verifier(c) # rule check, execution test, retrieval cross-check, or HUMAN
if v.passes:
c["verified_by"], c["confidence"] = v.method, v.confidence
verified.append(c)
# 4. Human-audit a random sample even of the "verified" set, and report the rate
audit = human_audit_sample(verified, n=100) # if audit pass-rate is low, STOP
# 5. Blend with real data so tails and ground truth survive - defeat collapse
return interleave(verified, real_data, real_fraction=0.5), auditThree structural choices in that pipeline matter. The verifier is separate from the generator, if the same model both generates and judges, it approves its own blind spots; the verifier must be a different model, a rule, an execution test (does the generated code run and pass the tests?), a retrieval cross-check (does the claimed fact match a trusted source?), or a human. The diversity cap actively fights narrowing by refusing to let the generator's favorite outputs dominate. And the real-data blend keeps the distribution anchored to reality so collapse cannot set in. Verification is where the strongest synthetic results came from: Constitutional AI generated training and preference signal from a model, but governed it with explicit written principles and a critique-and-revise loop, structure that turned raw generation into usable signal. Synthetic data works in proportion to the rigor of the thing that checks it.
Where synthetic data genuinely shines
Despite the hazards, there are situations where synthetic data is the right answer, and they share a feature: the synthetic output is cheaply and reliably verifiable.
- Code and structured outputs with execution checks. A generated coding example can be run: does the code compile, pass the tests, produce the right output? Execution is ground truth, so the inherited-error mode is defeated by construction, you keep only the examples that actually work. This is why synthetic data worked so well for phi-1's coding task: correctness was checkable.
- Format and schema augmentation. Generating varied inputs that map to a known schema (Chapter 5) is safe because the shape is the target and the shape is verifiable, while the varied content washes out (Chapter 2). Synthesizing a thousand differently-formatted invoices that all map to the same JSON is a coverage win with low risk.
- Edge-case and negative coverage. Generating the rare and negative cases that real data starves (Chapter 9) is valuable if each generated edge case is human-reviewed, you are using the generator to propose hard cases a human then verifies and corrects, which is cheaper than finding them in the wild.
- Privacy-preserving stand-ins. When real data carries PII you cannot train on, carefully generated synthetic analogues can sometimes substitute, but only with strong verification that the synthetic data does not leak the real data it was derived from, which is a research-grade concern, not a default.
In every case the safety comes from verifiability, not from the generation. The rule of thumb: synthetic data is as trustworthy as the cheapest reliable way you have to check it. If you can execute it, you can use a lot. If you can only have a human read it, you can use as much as you can afford to review. If you cannot check it at all, you cannot safely use it, generation without verification is just laundering a model's guesses into your training set.
The poisoning angle
There is a security dimension that the contamination chapter only touched. If any part of your training data comes from a source you do not fully control, public datasets, user submissions, scraped content, a third-party generator, an adversary (or just an accident) can introduce examples designed to instill a bad behavior, and once trained, that behavior is in the weights and recited confidently like any other. This is data poisoning, and synthetic data widens the attack surface because generated data is voluminous and under-audited by default. The same grounding discipline is the defense: verify, sample, audit, and keep provenance (source in the pipeline above) so that if a bad behavior shows up after training, you can trace which data introduced it and exclude that source from the next run. A training set without provenance is a training set you cannot clean up after, and the asymmetry of Chapter 1 applies, a poisoned behavior shipped to everyone is expensive to discover and removable only by retraining.
Chapter summary
Synthetic data, examples generated by a model, is the most powerful and most dangerous data tool: it makes the expensive part of fine-tuning (clean, well-covered data) fast and cheap, and it genuinely works (Self-Instruct, Alpaca, phi-1). But a synthetic example is a model's guess, not ground truth, and it fails in three named ways. Inherited error: the generator's consistent mistakes become learned rules (defense: verify against ground truth on the weakest slices). Distribution narrowing: the generator samples its bland mode, not reality's tails, making the model worse exactly where it was already failing (defense: prompt for diversity, measure against real, blend). Recursive collapse: the synthetic-on-synthetic loop degrades each generation, losing rare events then variance then quality, as the Nature study documented (defense: keep real data in every mix, never train purely on prior output). The unifying principle is the grounding discipline: a synthetic example is a candidate until something real verifies it, generate, filter aggressively, verify with a separate checker (a different model, an execution test, a retrieval cross-check, or a human), audit a sample, and blend with real data. Synthetic data is as trustworthy as the cheapest reliable way you have to check it: execution-checkable code, verifiable schemas, human-reviewed edge cases, and privacy stand-ins are where it shines, and unverifiable generation is just laundering guesses into weights. Finally, any uncontrolled data source is a poisoning surface; provenance on every example is what lets you trace and clean a bad behavior after the fact, because the asymmetry holds, a poisoned behavior is removable only by retraining.