What Fine-Tuning Actually Changes
> **Working claim:** A fine-tune does not "teach the model your data" in the way the phrase implies. It nudges a probability distribution toward the patterns your examples demonstrate.

Working claim: A fine-tune does not "teach the model your data" in the way the phrase implies. It nudges a probability distribution toward the patterns your examples demonstrate. Understanding that one mechanical fact, that you are reshaping a distribution, not loading a database, explains almost every surprise teams hit: why facts don't stick reliably, why style does, why a little contradictory data does outsized damage, and why the model forgets things you never meant it to touch.
Key Takeaways
- Fine-tuning reshapes a probability distribution; it does not write to a key-value store.
- Patterns like style and format stick because they repeat across examples.
- A fine-tune is a trade: more task specialization can mean less general capability.
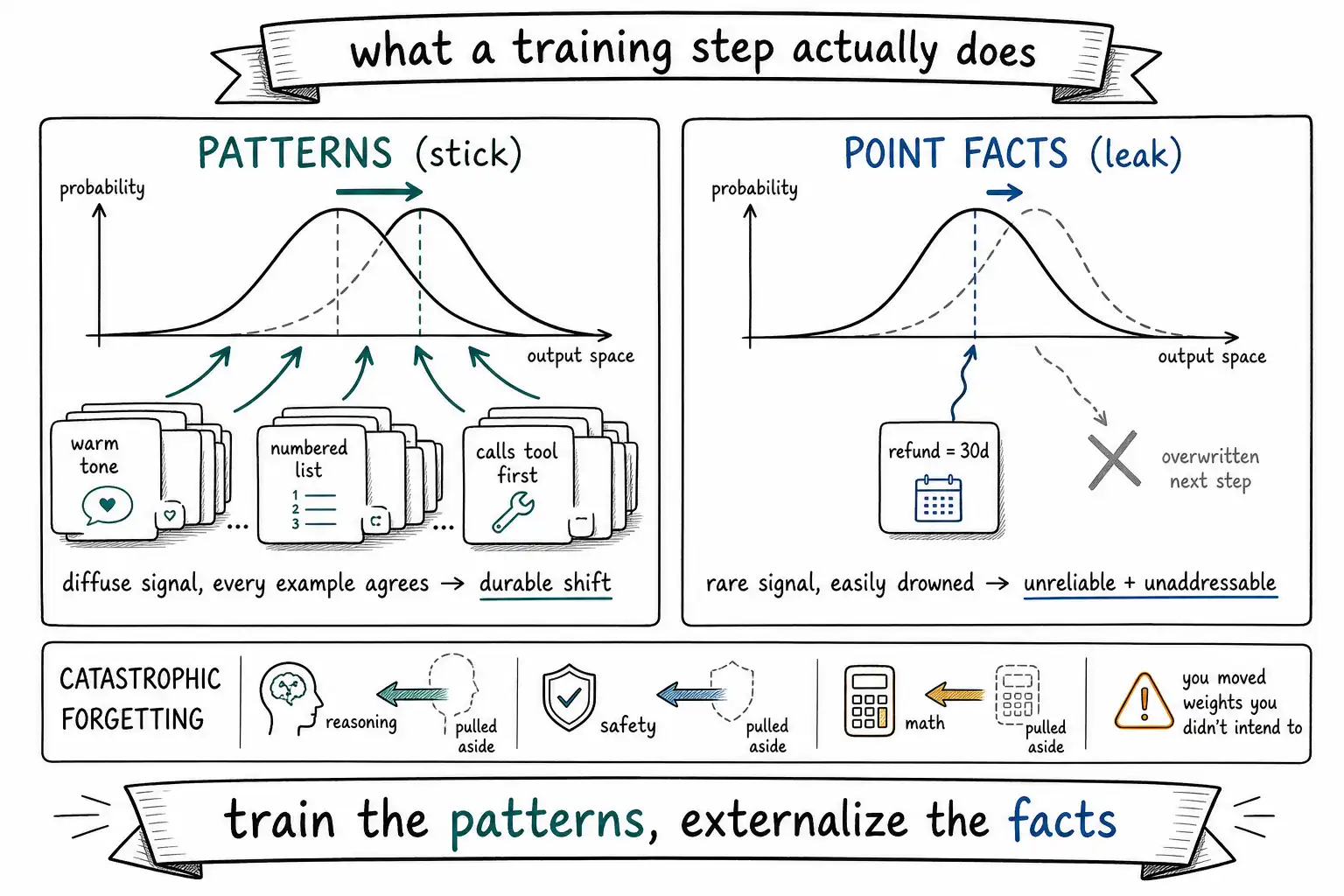
What a training step does, in one paragraph of mechanism
Set aside the metaphors for a moment and look at the machinery. A language model is a function that, given a sequence of tokens, produces a probability distribution over the next token. Supervised fine-tuning shows the model an example, a prompt and the response you want, and, for each token in the desired response, measures how much probability the model currently assigns to the correct next token. Where the model is already confident and correct, the loss is small and little changes. Where the model would have predicted something else, the loss is large, and the optimizer nudges the weights so that next time, on a similar input, the desired token is slightly more probable. Repeat over thousands of examples and many passes, and the model's distribution shifts toward producing outputs that look like your examples. The OpenAI supervised fine-tuning guide describes this plainly: training adjusts weights to minimize the difference between predicted and target outputs across the examples you provide.
Two consequences follow immediately, and they are the whole chapter.
First, you are shaping a distribution, not writing to a key-value store. There is no row in the model that says refund_window = 30 days. There is a slightly increased probability that, in contexts that resemble your training examples, the tokens "30 days" appear. That probabilistic encoding is why a fine-tuned fact is unreliable (it competes with everything else the model believes) and unaddressable (you cannot locate or edit it). It is also why style sticks so well: style is a pervasive statistical regularity across all your examples, every example is warm, every example is a numbered list, so the nudge is consistent and reinforcing, while a single fact appears in one example and is easily overwritten.
Second, the model is changing everywhere, not just where you intended. You showed it support tickets; it adjusted weights that also govern how it writes poetry, solves arithmetic, and refuses harmful requests. Usually those side effects are small. Sometimes they are not, and the model gets measurably worse at things you never touched. That is catastrophic forgetting, and it is not a bug in your data, it is a property of gradient descent on a shared parameter space.
Why facts are bad tenants in weights
It is worth being precise about why fine-tuning is a poor way to store facts, because "just retrieve it" is advice people accept intellectually and ignore in practice.
Knowledge has measurable capacity limits in model weights. The knowledge capacity scaling study found that models store on the order of a couple of bits of factual knowledge per parameter under good conditions, meaning facts are expensive to store in weights and require many exposures and clean presentation to stick at all. A handful of training examples mentioning a fact does not reliably install it; it perturbs the distribution slightly and is easily drowned out by the vastly larger pre-training signal. This is the mechanical reason the support bot's fine-tune did not even reliably learn the new facts when they were present, facts need repetition and consistency to take, and a support corpus contains each specific fact only a few times, inconsistently phrased.
Contrast this with what a retrieval system does: it stores the fact once, verbatim, in a place you can read, edit, version, and delete, and injects it at full fidelity exactly when needed. On the dimension of storing and serving a specific current fact, retrieval beats fine-tuning on accuracy, freshness, editability, auditability, and cost. There is no contest. Fine-tuning's strength is the opposite kind of thing, diffuse, pervasive patterns that should color every response, and facts are not that kind of thing.
| You want to encode... | ... as a fine-tune? | Why |
|---|---|---|
| "Always answer as a numbered list" | Yes | Pervasive pattern across all examples; reinforced every step |
| "Use a warm, concise tone" | Yes | Diffuse statistical regularity; exactly what distribution-shaping is good at |
| "Classify tickets into these 8 categories" | Yes | Repeated task structure with consistent target behavior |
| "Our refund window is 30 days" | No | A single point fact; expensive to store, unreliable, unaddressable, goes stale |
| "User 8831 is on the Pro plan" | Never | Per-request state; changes; belongs in a database |
"Call the lookup_order tool before answering shipping questions" | Yes | A behavioral convention, repeated across examples |
Catastrophic forgetting: the side effect you didn't authorize
When you fine-tune, the optimizer is free to move any weight that reduces loss on your examples, including weights that encode capabilities unrelated to your task. The result, well documented, is that a model fine-tuned hard on a narrow task can lose general capability, reasoning, instruction-following, even safety behavior, that it had before. The empirical study of catastrophic forgetting during continual fine-tuning found general-capability degradation across model sizes as fine-tuning proceeds, and noted that the effect grows with how aggressively you train.
This reframes a fine-tune as a trade, not a pure gain. You are spending some of the model's general competence to buy specialization on your task. Often that is a good trade, you do not need your extraction model to write sonnets. But you must measure both sides of it, which is why the evaluation movement (Chapter 15) insists on regression evals alongside target-task evals: the new model can win the task you trained for and quietly lose three you didn't, and if you only measure the target task you will ship that loss to production. Catastrophic forgetting is the single most common reason a fine-tune that "passed eval" causes incidents, the eval measured the wrong half of the trade.
Three practical mitigations follow directly from the mechanism, and we will return to each:
- Train less, not more. Fewer epochs and lower learning rates move the weights less, preserving general capability. The instinct to "train until the loss is really low" is usually overfitting plus forgetting.
- Use parameter-efficient methods. LoRA freezes the base weights entirely and learns small low-rank adapter matrices on top. Because the base is frozen, the original capabilities are structurally protected, and you can detach the adapter to recover the base model exactly, a built-in rollback (Chapter 12).
- Mix in diverse data. Including some general examples alongside your task data dilutes the narrowing pressure. This is one reason instruction-tuned models are trained on broad instruction mixtures, not single tasks.
Behavior is durable; knowledge is leaky
Put the two halves together and a clean principle emerges, which is really the thesis of the whole book restated mechanically:
Fine-tuning durably changes pervasive patterns (behavior, style, format, task structure) and leakily changes point facts (knowledge). So train for the durable kind and externalize the leaky kind.
This is why InstructGPT worked: "follow instructions, be helpful, match human preferences about response style" is a pervasive pattern present in every training example, so distribution-shaping installs it deeply and reliably. It is also why the same technique applied to "know our 600-page policy" fails: the policy is ten thousand point facts, each appearing rarely, many contradicting older versions, all expensive to store and impossible to keep current. Same technique, opposite outcome, and the difference is entirely whether the target is a pattern or a fact.
A short worked example makes the leakiness visible. Suppose you fine-tune on 500 support examples, and in three of them an agent mentions "we offer a 30-day refund." You have not taught the model "the refund window is 30 days" in any reliable sense, three mentions among 500 examples is a faint signal. What you have reliably taught it is the behavior shared by all 500: the tone, the structure, the habit of mentioning a refund window at all. Now suppose the window changes to 14 days. Retrieval fixes this in one edit. Your fine-tune does not, the faint "30" signal is still in there, and the model may emit "30" or "14" or hedge, unpredictably, because it was never a fact in the first place; it was a smudge in a distribution. Unpredictable is worse than wrong. You can defend against consistently wrong; you cannot defend against sometimes-wrong-in-the-house-voice.
What "the model learned our data" actually means
Strip the phrase down and it almost always means one of two precise things, and conflating them is the recurring error:
- "The model now behaves like our examples." True and durable for patterns. This is the legitimate goal of fine-tuning.
- "The model now knows the facts in our data." Mostly false, always leaky, never current. This is the illegitimate hope, and the source of most disappointment.
When a stakeholder says "let's train it on our data so it knows our business," translate immediately: which part is pattern (train it) and which part is fact (externalize it)? In nearly every real corpus the answer is "both, tangled together," and the engineering work is the untangling, which is why Movement III spends four chapters on the data, because the data is the part that decides whether your fine-tune learns a clean behavior or memorizes a smear of stale facts.
Chapter summary
Mechanically, supervised fine-tuning shows the model desired prompt-response pairs and nudges the weights so the desired tokens become more probable in similar contexts, it shapes a probability distribution, it does not write to a key-value store. Two consequences explain almost every surprise. First, you are reshaping a distribution: pervasive patterns (style, format, task structure, tool conventions) are reinforced by every example and stick durably, while point facts appear rarely, are expensive to store in weights (only a couple of bits of knowledge per parameter under good conditions), and end up unreliable, unaddressable, and unpredictably stale, which is why retrieval dominates fine-tuning for serving specific current facts. Second, the optimizer moves any weight that lowers loss, including ones that encode unrelated capabilities, so fine-tuning is a trade: specialization bought with some general competence (catastrophic forgetting), which is why regression evals matter and why training less, using LoRA's frozen base, and mixing in diverse data all help. The clean principle: fine-tuning durably changes pervasive patterns and leakily changes point facts, so train the patterns and externalize the facts."The model learned our data" almost always means either "it now behaves like our examples" (true, durable) or "it now knows the facts in our data" (mostly false, always leaky), and the engineering work of the next movement is untangling which parts of a real corpus are which.