Specializing Small Models and Distilling Down
> **Working claim:** The most economically compelling fine-tune is not making a big model smarter, it is making a small model good enough. A large frontier model used as a generalist on a narrow, high-volume task is paying for capability it does not use.

Working claim: The most economically compelling fine-tune is not making a big model smarter, it is making a small model good enough. A large frontier model used as a generalist on a narrow, high-volume task is paying for capability it does not use. Specializing a small model on that task, or distilling the large model's behavior into a small one, can match quality at a fraction of the cost and latency, but only when you can prove the match on your own eval, and only when the math actually clears.
Key Takeaways
- The strongest economic fine-tune often makes a small model good enough, not a big model smarter.
- Distillation copies the teacher's behavior, including mistakes, so ground-truth evals decide.
- Volume, data curation, and ongoing ops dominate the break-even calculation.
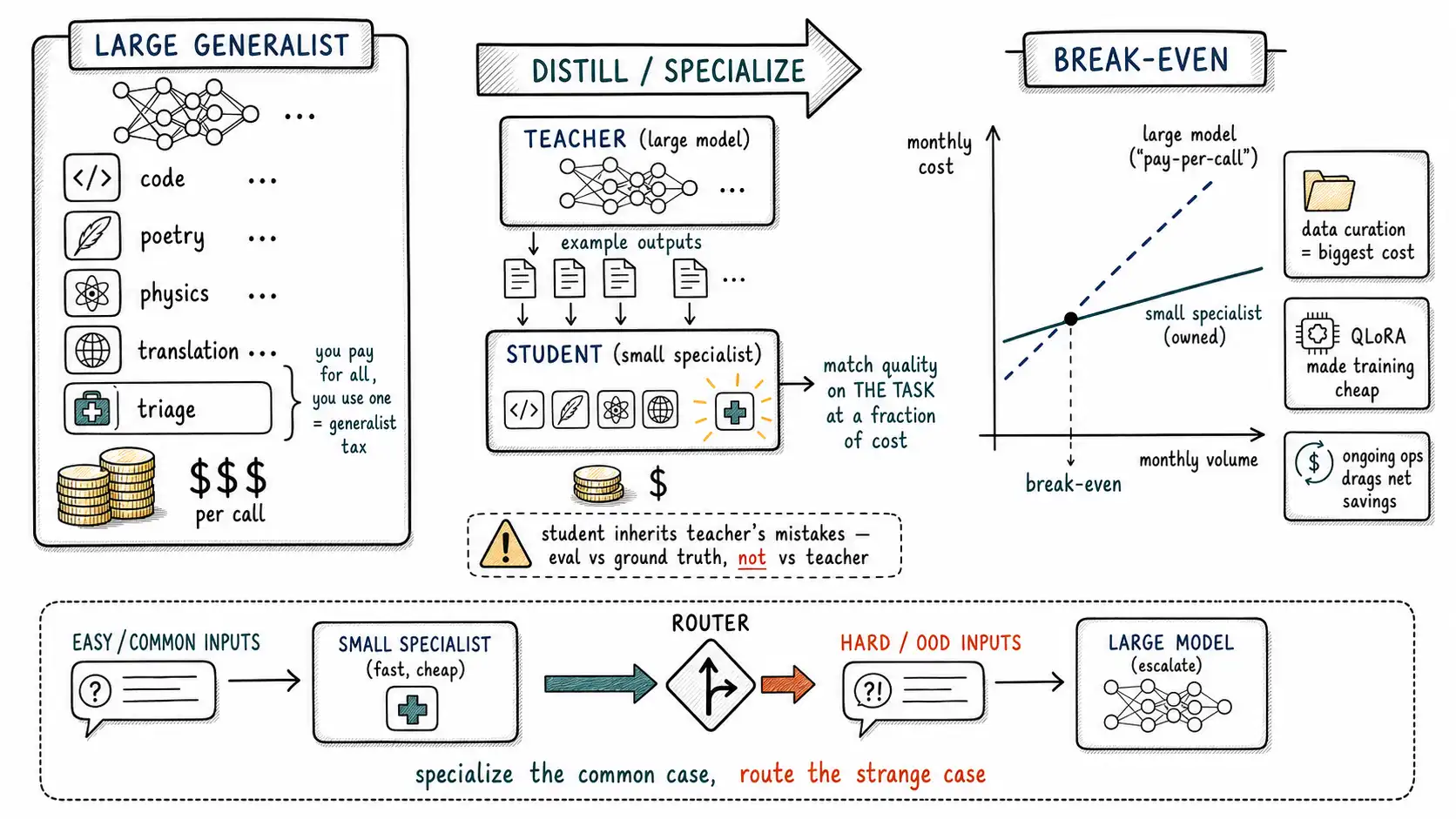
The generalist tax
A frontier model is a generalist. It can write code, translate, reason about physics, draft poetry, and triage a support ticket, and when you call it to triage a support ticket, you are paying, in parameters activated and dollars per token, for all the capabilities you are not using. For a one-off query this waste is invisible and irrelevant. For a task you run ten million times a month, it is the line item that gets you a meeting with finance. This is the generalist tax: the gap between the capability a frontier model offers and the capability your narrow task consumes, billed to you on every call.
The reason this tax is worth attacking with fine-tuning rather than just "use a cheaper model" is that an off-the-shelf small model is usually not good enough on a hard narrow task, that is why you reached for the big one. The fine-tuning move is to close that quality gap: take a small model, specialize it on your task until it matches the big model's quality on that task, and capture the cost-and-latency savings without sacrificing the quality you needed. The OpenAI model optimization guide frames distillation and fine-tuning exactly this way, as the path to delivering reliable results at lower cost once you have a working approach and an eval to hold the line.
The empirical evidence that small models can punch far above their parameter count when the data is right is strong and worth internalizing. Textbooks Are All You Need trained phi-1, a 1.3B-parameter model, on carefully curated "textbook-quality" data and reached coding performance that embarrassed much larger models trained on web scrape. Phi-3 extended the line: a 3.8B model trained on heavily filtered and synthetic data rivaling models an order of magnitude larger, small enough to run on a phone. The lesson is not "small models are secretly as good as big ones", they are not, in general. The lesson is that on a focused capability, with the right data, a small model can match a big one, and a focused capability with the right data is precisely what your narrow high-volume task is.
Two paths: specialize, or distill
There are two ways to get a small model good at your task, and they differ in where the training signal comes from.
Specialization (SFT on real labels). You have a labeled dataset, real inputs with correct outputs, from human labels or from your existing system's verified results, and you fine-tune the small model directly on it. The signal is ground truth. This is the path when you have real labeled data, and it is the most reliable because the model learns from correct answers, not from another model's approximation of correct answers.
Distillation (learn from a teacher model). You do not have enough labels, but you have a large "teacher" model that already does the task well. You run the teacher on a large set of inputs, collect its outputs, and fine-tune the small "student" model to reproduce them. The signal is the teacher's behavior. This is the path when labeling is expensive but the big model already works, which is common, because "the big model works but costs too much" is the exact situation that motivates the project. Distillation goes back to Hinton, Vinyals, and Dean, who showed you can compress the knowledge of a large model (or ensemble) into a small deployable one by training the student on the teacher's outputs, and that the soft information in the teacher's full output distribution carries more signal than hard labels alone. In LLM practice you often distill on the teacher's generated text (and sometimes its token probabilities where the API exposes them), turning an expensive teacher into a cheap student that mimics it on your task.
The two paths combine well: use the teacher to generate candidate labels, have humans verify and correct a sample, and fine-tune on the corrected set, distillation for coverage, human review for ground truth. The critical discipline, which Chapter 11 covers in full, is that distillation inherits the teacher's mistakes: if the teacher is confidently wrong on a class of inputs, the student learns to be confidently wrong on it too, and now you have baked the error into a model that is harder to inspect. Distillation copies behavior, including bad behavior, so you must evaluate the student against ground truth, not just against agreement with the teacher.
The cost model
The decision to specialize a small model is, at bottom, a break-even calculation, and teams routinely get it wrong by ignoring the fixed costs. Here is a worked cost model. The numbers are illustrative, plug in your own, but the structure is what matters.
# Cost model: large generalist vs fine-tuned small specialist.
# All costs illustrative; replace with your provider's actual numbers.
# --- Per-request inference cost (input + output tokens) ---
def per_request_cost(in_tokens, out_tokens, in_price, out_price):
return (in_tokens * in_price + out_tokens * out_price) / 1_000_000 # prices per 1M tokens
# Large generalist: needs a big prompt (instructions + few-shot), pricey tokens
large = per_request_cost(in_tokens=2200, out_tokens=300, in_price=5.00, out_price=15.00)
# Fine-tuned small specialist: tiny prompt (shape is in the weights), cheap tokens
small = per_request_cost(in_tokens=250, out_tokens=300, in_price=0.30, out_price=1.20)
monthly_volume = 10_000_000
monthly_savings = (large - small) * monthly_volume
# --- One-time + ongoing fixed costs of the fine-tune ---
data_curation = 8_000 # human time to build/verify the dataset (the real cost)
training_runs = 1_500 # initial + a few iterations
eval_build = 4_000 # the eval suite you must build anyway (Ch. 15)
fixed_one_time = data_curation + training_runs + eval_build
# --- Ongoing operational cost (Ch. 16): retraining, monitoring, registry ---
monthly_ops = 1_200 # drift monitoring, periodic retrain, on-call surface
net_monthly = monthly_savings - monthly_ops
break_even_months = fixed_one_time / net_monthly if net_monthly > 0 else float("inf")
print(f"large ${large:.5f}/req small ${small:.5f}/req")
print(f"gross savings ${monthly_savings:,.0f}/mo, net of ops ${net_monthly:,.0f}/mo")
print(f"break-even in {break_even_months:.1f} months")Three things in this model are routinely forgotten and routinely decide the outcome. First, data curation is usually the largest cost, not training, the GPU time for a QLoRA run is cheap; the human time to build a clean dataset is not (Movement III). Second, the eval suite is a cost you pay regardless, but it belongs in the model because without it you cannot prove the small model matches the large one, and an unproven specialization is a gamble, not a savings. Third, ongoing ops is a recurring drag, a fine-tuned model is a thing you now operate forever (Chapter 16), and that cost reduces your net savings every month. A specialization that breaks even in three months at ten million requests is a clear win; the same specialization at fifty thousand requests a month never breaks even, which is why volume is the gate.
QLoRA: why the training half got cheap
The reason small-model specialization is so much more attractive now than it was a few years ago is that the training side of the cost model collapsed. QLoRA showed you can fine-tune a quantized model, weights compressed to 4-bit, while training only small low-rank adapters on top, drastically cutting the memory needed, to the point that models which used to require a cluster can be fine-tuned on a single GPU without a measurable quality loss versus full-precision LoRA. We cover the mechanics in Chapter 12; the relevant point here is economic: QLoRA pushed the training_runs line of the cost model down toward negligible, which means the break-even is now dominated by data curation and ongoing ops, not by GPU spend. The decision has shifted from "can we afford to train?" to "can we afford to build the data and operate the result?", which is exactly the shift this book is built around, because those are judgment and discipline costs, not hardware costs.
When specialization wins, and when it doesn't
The cost model plus the quality requirement gives a clean decision rule.
| Condition | Specialize small model? |
|---|---|
| High volume (millions/mo) + narrow stable task | Yes, the canonical win |
| Off-the-shelf small model already hits the bar | No, just use it, no training needed |
| Small model fine-tuned still can't reach the bar | No, keep the large model, use routing for the hard tail |
| Low volume | No, fixed costs never amortize; prompt the large model |
| Task changes frequently | No, retraining treadmill eats the savings (T fails) |
| You can't build an eval to prove the match | No, you'd be shipping an unverified downgrade |
The pattern in the "no" rows is instructive: specialization fails for the same reasons any fine-tune fails, instability (the treadmill), low volume (no amortization), or no eval (no proof), plus one specific to this case: if the small model cannot reach the bar even after fine-tuning, you have hit a genuine capability ceiling, and the right move is to keep the large model and use routing (Chapter 4) to send only the hard inputs to it while a cheaper model or a partial specialist handles the easy majority. Routing captures much of the savings with none of the quality risk, and it composes with a partial specialization: a fine-tuned small model handles the 80% it can, and escalates the 20% it can't to the large model. That hybrid is frequently the real production answer, not a pure swap.
One more guardrail, because it is the failure that turns a cost-saving project into an incident: a specialized small model has less spare capability to fall back on when an input is out of distribution. The large generalist, encountering a weird input, often degrades gracefully because it has seen everything; the specialist, trained narrowly, may fail confidently and strangely on the same input because it has been narrowed to your task and lost the general competence to handle the unexpected, the catastrophic forgetting of Chapter 2, now a feature you deliberately bought. So a specialist needs tighter input validation and a clear escalation path for out-of-distribution inputs, which is again why the routing hybrid is so natural: the escalation path is the large model. Specialize for the common case, route the strange case, and prove the whole thing on an eval before you trust it with the savings.
Chapter summary
The most economically compelling fine-tune makes a small model good enough rather than a big model smarter, attacking the generalist tax, the capability a frontier model offers but your narrow high-volume task never uses, billed on every call. Off-the-shelf small models usually fall short on hard narrow tasks (that is why you reached for the big one), so the move is to close that gap: specialize a small model on the task until it matches the large model's quality on that task, evidenced by phi-1 and Phi-3 showing small models matching far larger ones on focused capabilities with the right data. Two paths: specialization (SFT on real ground-truth labels, most reliable) and distillation (train a small student to reproduce a large teacher's outputs, per Hinton et al., the path when labels are scarce but the big model works), with the warning that distillation inherits the teacher's mistakes, so you evaluate the student against ground truth, not against agreement with the teacher. The decision is a break-even calculation whose forgotten terms decide the outcome: data curation is usually the largest cost (not GPU time, which QLoRA made cheap), the eval suite is mandatory to prove the match, and ongoing ops drags net savings every month, so volume is the gate. Specialization wins on high-volume stable narrow tasks with a provable eval; it loses on low volume, instability, no eval, or a genuine capability ceiling, where routing the hard tail to the large model captures the savings without the risk. Because a specialist has less spare capability for out-of-distribution inputs, the production answer is usually a hybrid: specialize the common case, route the strange case, and prove it on an eval first.