House Style, Domain Phrasing, and Tool Discipline
> **Working claim:** Three behaviors are worth training that teams often try to prompt forever: a genuine house style, fluent domain phrasing, and disciplined tool use.

Read this alongside the Fine Tuning Or Not book, the AI-Native thesis, and the full book library when you want the surrounding argument.
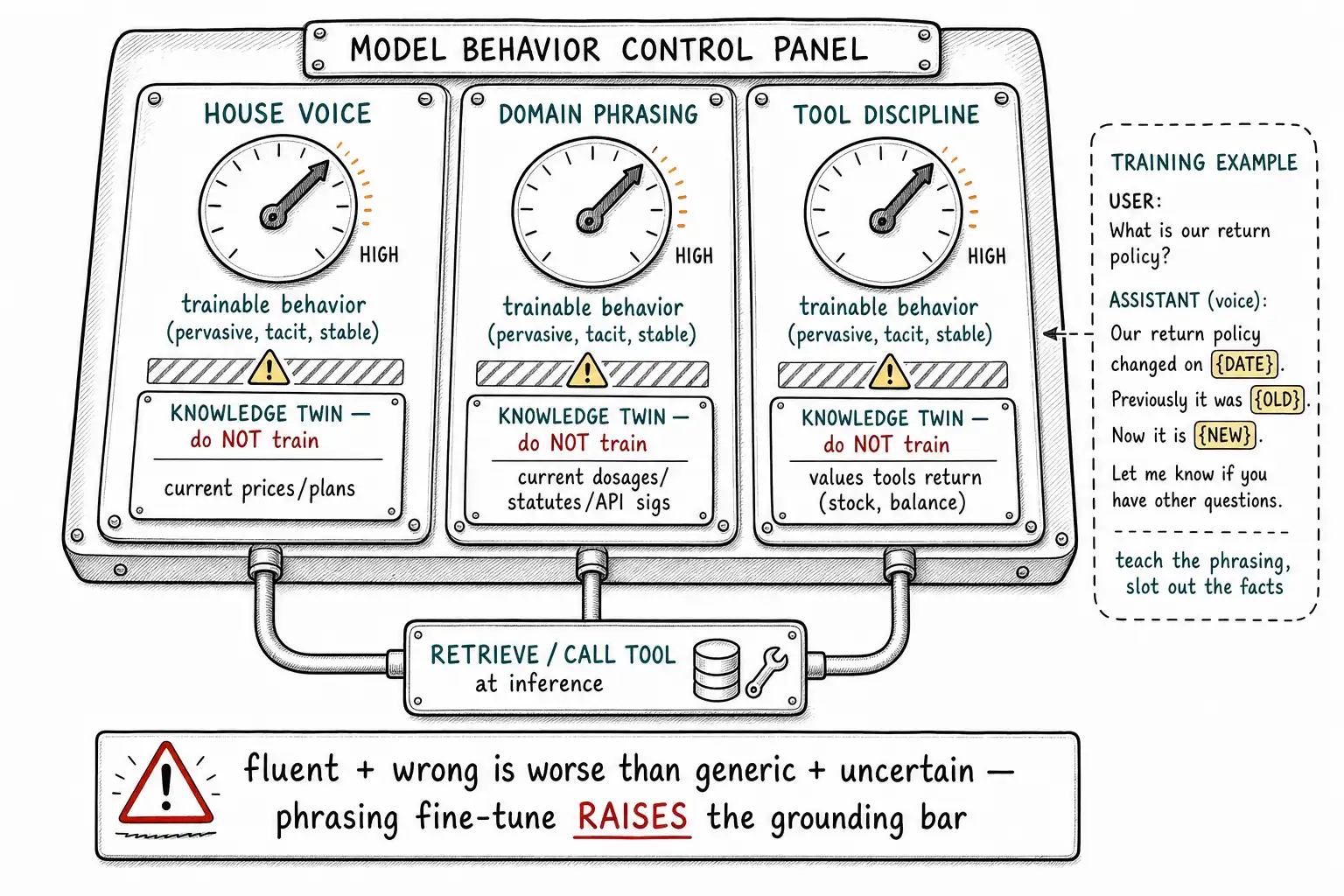
Working claim: Three behaviors are worth training that teams often try to prompt forever: a genuine house style, fluent domain phrasing, and disciplined tool use. Each is pervasive (it should color every response), hard to specify in words (so prompting plateaus), and stable (so it survives in weights). But each also has a knowledge twin that must not be trained, and confusing the behavior with its twin is how style fine-tunes become fact-recitation disasters.
Key Takeaways
- House style is worth training only when it is pervasive, specific, and consequential.
- Domain phrasing can be trained, but domain facts must still be retrieved or fetched.
- Tool discipline is a behavioral habit: right tool, right arguments, right time, and restraint.
When style is a product requirement, not a vanity
"Make it sound like us" is the request most likely to be dismissed as soft and most likely, when it is real, to be a strong fine-tuning case. The dismissal is sometimes right: a lot of "house voice" requests are aesthetic preferences that a one-line prompt instruction satisfies ("be warm and concise"), and training for them is overkill. But there is a category where style is a genuine product requirement with measurable stakes, and recognizing it is the skill.
Style is a real requirement when it is pervasive, specific, and consequential. Pervasive: it must appear in every response, not just when convenient, a brand voice that shows up 80% of the time reads as inconsistent and undermines the brand. Specific: it is more than "professional," it has identifiable features (a particular cadence, a refusal to use certain words, a way of structuring bad news, a level of hedging) that a short instruction cannot capture. Consequential: getting it wrong has a cost, customer trust, brand dilution, regulatory tone requirements, a sales voice that converts. A sales-email rewriter that must hit the company's exact persuasive register across millions of emails is consequential; a hobby project's "friendly tone" is not.
The reason these cases resist prompting is that style is high-dimensional and tacit. You can describe a few features, but the full voice lives in a thousand micro-decisions that you recognize when you see them and cannot enumerate. This is exactly the territory where demonstrations beat instructions: you cannot tell the model the voice, but you can show it a few hundred examples, and the supervised fine-tuning process will extract the pervasive regularities you could never have written down. It is the same reason InstructGPT used demonstrations and preferences rather than a giant instruction document to install "helpful assistant" behavior, the target was tacit and pervasive, the perfect fine-tuning shape.
Style's dangerous twin
Here is the trap. Style examples are written by your team, in your voice, about your product, and they are therefore full of current facts. A brand-voice training set for a SaaS company will mention features, prices, plan names, and policies, because those are what the company writes about. Train on it naively and you have done exactly what the support team did: smuggled current facts into the weights under cover of teaching style. The discipline is to decontextualize style examples, strip or genericize the facts, keep the voice. A training example should teach "this is how we phrase a price increase" with a placeholder or a varied dummy figure, not "our price is now $49," so the model learns the phrasing pattern (behavior) and never the number (knowledge). Teaching tone with real current data is how a tone fine-tune becomes a stale-fact recitation engine.
# WRONG: teaches voice AND freezes a current fact
{"messages": [
{"role": "user", "content": "Tell the customer about the price change."},
{"role": "assistant", "content": "Heads up - starting next month, Pro moves from $29 to $49/mo. Your features stay exactly the same, and you can downgrade anytime."}
]}
# RIGHT: teaches the same voice, fact comes from retrieval at inference time
{"messages": [
{"role": "user", "content": "Tell the customer about the price change.\n[PRICE_INFO]: Pro plan, old {OLD}, new {NEW}, effective {DATE}, features unchanged"},
{"role": "assistant", "content": "Heads up - starting {DATE}, Pro moves from {OLD} to {NEW}/mo. Your features stay exactly the same, and you can downgrade anytime."}
]}
# The voice (warm, reassuring, "heads up", downgrade reassurance) is learned.
# The numbers are slots filled by retrieved current data, never frozen.Domain phrasing: jargon as behavior
The second trainable behavior is domain phrasing, using the field's vocabulary, idioms, and conventions correctly. A model that writes "the patient was administered" instead of "the patient was given," that uses "consideration" in its legal sense, that knows a "regression" in your codebase means a CI failure and not a statistical model, this fluency reads as competence and its absence reads as an outsider faking it. For domains with dense, specific jargon, generic models are noticeably off, and prompting the vocabulary in is awkward (you cannot list every term). Fine-tuning on in-domain text installs the phrasing as a pervasive behavior, the same way it installs style.
The knowledge twin here is subtle and worth naming precisely. Domain phrasing (how the field talks) is behavior and trainable. Domain facts (what is true in the field right now, this drug's current dosage, this statute's current text, this API's current signature) are knowledge and must be retrieved. The danger is that fluent phrasing creates false confidence: a model that sounds exactly like a radiologist is more dangerous when wrong than one that sounds generic, because the fluency invites trust. So a domain-phrasing fine-tune raises, not lowers, the bar for grounding facts, you have made the model more convincing, which means you must be more certain it is correct, which means retrieval, tools, and human review get more important after a phrasing fine-tune, not less. Fluency without grounding is a confidence trick you are playing on your own users.
Tool discipline: the undervalued fine-tune
The third behavior is the one teams most often try to prompt and most often should train: tool discipline. An agent or assistant with access to tools must decide which tool to call, when, with what arguments, and, critically, when not to call a tool. Prompting can get you part of the way, but tool discipline is a pervasive behavioral habit ("always call check_inventory before promising stock," "never call issue_refund without confirming the order first," "use search for facts you don't know rather than guessing"), and pervasive habits are what fine-tuning installs best.
This is precisely what Toolformer demonstrated: a model can be trained to decide which API to call, when, and with what arguments, learning from a modest set of demonstrations, and the trained tool-use behavior substantially improved downstream performance. The behavior being learned, disciplined, well-timed tool calls with correct arguments, is pattern-shaped and stable, the ideal fine-tune target. In production terms, you fine-tune on traces of correct tool use: conversations where the right tool was called at the right time with the right arguments, and conversations where a tool was correctly not called. The function-calling guide gives the schema; the fine-tune gives the judgment about when to use it.
{"messages": [
{"role": "user", "content": "Do you have the blue widget in size large in stock?"},
{"role": "assistant", "content": null, "tool_calls": [
{"id": "c1", "type": "function", "function": {"name": "check_inventory", "arguments": "{\"sku\":\"widget-blue\",\"size\":\"L\"}"}}]},
{"role": "tool", "tool_call_id": "c1", "content": "{\"in_stock\": true, \"qty\": 12}"},
{"role": "assistant", "content": "Yes - the large blue widget is in stock."}
]}The training signal is the discipline: the model learns to check inventory before answering a stock question rather than guessing, and to ground its answer in the tool result. Note again what is not being trained: the inventory count (12) is a tool result, not a fact in the weights, the model learns the habit of calling the tool, never the answer the tool returns. Confusing those would be the same original sin in tool-shaped clothes: a model that "remembers" that you had 12 in stock is a model that will lie about inventory the moment the count changes.
Tool discipline also has a refusal dimension that is hard to prompt and valuable to train: a well-disciplined model declines to call dangerous tools without confirmation and declines to fabricate when a tool fails. Including examples where the model correctly says "I tried to look that up but the lookup failed; let me escalate" teaches a safety behavior that pays for itself the first time a tool outage would otherwise have produced a confident fabrication.
The common thread, and the common trap
All three behaviors, style, phrasing, tool discipline, share the features that make a good fine-tune: pervasive (colors every response), tacit or pattern-shaped (hard to fully specify in a prompt, so prompting plateaus), and stable (survives in weights without going stale). And all three share the same trap: a knowledge twin that lives right next to the behavior and must not be trained. Style sits next to current facts in the marketing copy. Domain phrasing sits next to current domain facts. Tool discipline sits next to tool results. In every case the move is identical: train the pervasive behavior, slot out the facts, and ground the facts at inference time through retrieval or tools.
| Behavior (train it) | Its knowledge twin (don't train it; ground it) |
|---|---|
| House voice / tone / register | Current prices, plan names, policy specifics in the copy |
| Domain phrasing and idioms | Current domain facts (dosages, statutes, API signatures) |
| Tool-calling discipline and timing | The values that tools return (inventory, balances, status) |
The reason this chapter pairs the three is that they are the most tempting behaviors to train and the most dangerous to train carelessly, because each is wrapped around live facts. Get the separation right and you get a model that sounds like you, talks like the field, and reaches for the right tool, while every fact it states is fresh, because the facts never lived in the weights at all. Get it wrong and you get a model that sounds authoritative while reciting last quarter, which is worse than a generic model that at least sounds uncertain. The Self-Instruct lesson applies: the form of good behavior can be taught from examples efficiently; the content of current truth cannot and must not be.
Chapter summary
Three behaviors reward training that teams often try to prompt forever, because each is pervasive (should color every response), tacit or pattern-shaped (so prompting plateaus), and stable (so it survives in weights). House style is a real fine-tuning case when it is pervasive, specific, and consequential, high-dimensional and tacit enough that you can show it but not fully tell it, which is why demonstrations beat instructions, the same reason InstructGPT used them. Domain phrasing installs the field's vocabulary and idioms as fluency that reads as competence. Tool discipline, which tool, when, with what arguments, and when not to call one, is the most undervalued fine-tune, exactly the trainable behavior Toolformer demonstrated. But all three share a dangerous knowledge twin sitting right beside the behavior: style examples are full of current prices and plan names; phrasing sits next to current domain facts; tool discipline sits next to the values tools return. The discipline is identical in all three: train the pervasive behavior, slot out the facts with placeholders or varied dummies, and ground the real facts at inference time through retrieval and tools, and recognize that a fluency fine-tune raises the grounding bar, because a model that sounds authoritative while reciting stale facts is more dangerous than a generic one that sounds uncertain.