What to Fine-Tune: Generators, Retrievers, and Routers
> **Working claim:** "Fine-tune the model" almost always means "fine-tune the generator, " and that is frequently the lowest-impact place to spend a training run.

Working claim: "Fine-tune the model" almost always means "fine-tune the generator," and that is frequently the lowest-impact place to spend a training run. In a real system the generator sits on top of a retriever and a router, and fine-tuning those, a small embedding model so retrieval finds the right document, a small classifier so the router sends the right request to the right model, is often cheaper, safer, and more impactful than touching the generator at all.
Key Takeaways
- Fine-tune the component that is actually broken, not automatically the generator.
- Retriever fine-tunes improve recall without changing the model that writes user-visible answers.
- Router fine-tunes are narrow, cheap, and often cleaner by TRAIN criteria than generator changes.
The system is not just the generator
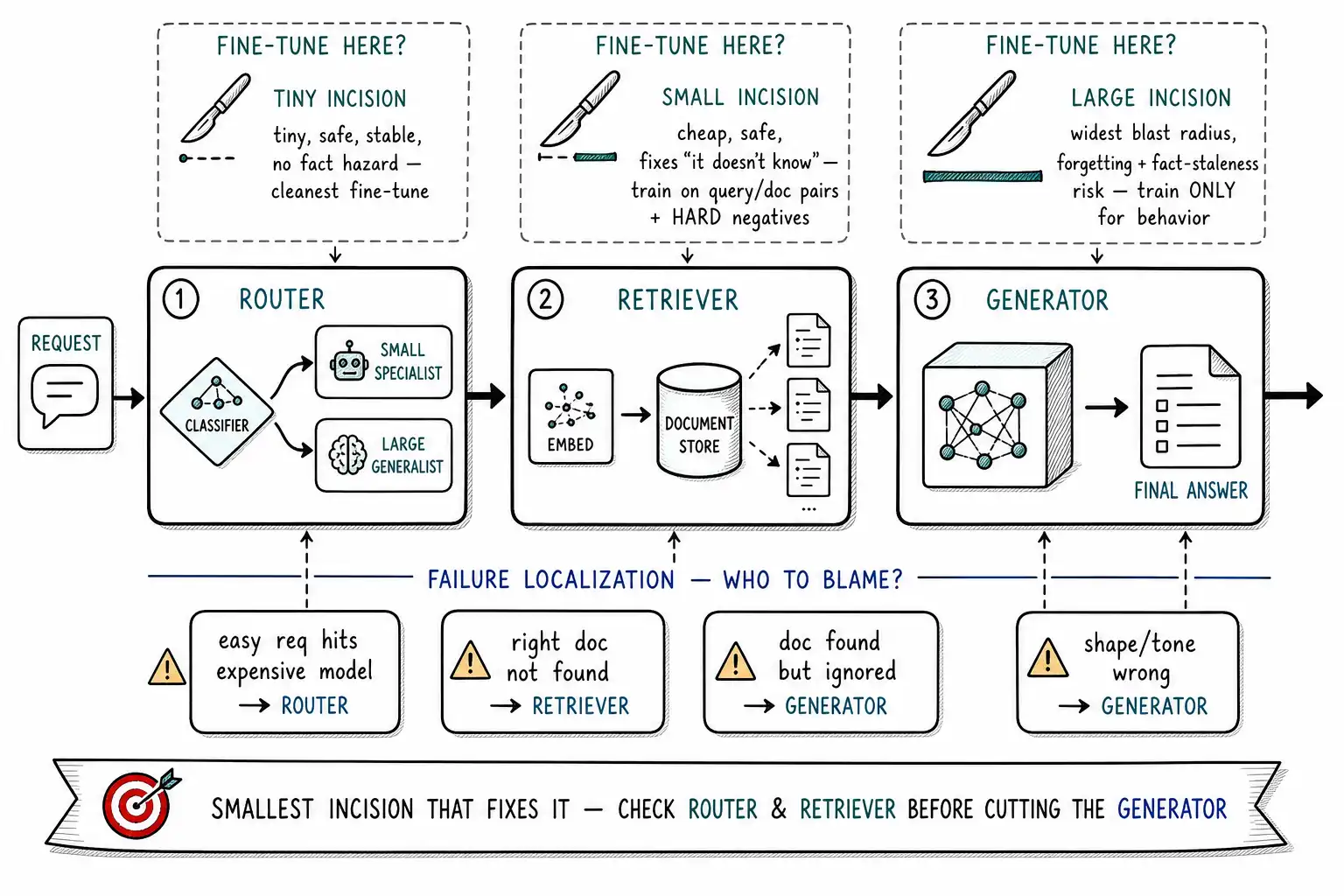
When a team says "let's fine-tune the model," they almost always mean the big generative model that writes the answer. But a production AI system is rarely just a generator. It is usually a pipeline: a router decides which model or path handles the request, a retriever finds the relevant knowledge, and the generator writes the response using that knowledge. Each of these components can be fine-tuned independently, and the reflexive focus on the generator skips two components that are often cheaper to train, safer to change, and more impactful on the failure you actually have.
This is the chapter that widens the lens. The diagnostic question from Chapter 3, "it doesn't know", usually routed to retrieval rather than training. But sometimes retrieval itself is the thing failing: the right document exists in your store, and the retriever does not find it, so the generator never sees it and answers from nothing. No amount of fine-tuning the generator fixes a retriever that returns the wrong passages. The highest-impact move is in the component that is actually broken, and locating that component is the skill.
Fine-tuning the retriever
A retriever works by embedding the query and the documents into a vector space and returning the documents whose embeddings are nearest the query's. Off-the-shelf embedding models, trained on general text, are good at general similarity but can be mediocre at your domain's notion of relevance, especially when your domain uses jargon, has unusual query-document relationships, or cares about distinctions a general model collapses. When retrieval recall is your bottleneck, fine-tuning the embedding model on your domain's query-document pairs is frequently the highest-impact training you can do.
The technique is well established. Dense Passage Retrieval showed that a dual-encoder retriever fine-tuned on a relatively small number of question-passage pairs substantially outperforms strong lexical baselines on retrieval accuracy, meaning a modest, targeted fine-tune of the retriever can find documents the generic embedder misses. Sentence-BERT established the dual-encoder/siamese training structure that makes this efficient: you train the embedder so that relevant query-document pairs land close and irrelevant ones land far apart. The training signal is pairs, often mined from your own data, a query and the document that answered it (a positive), and documents that did not (negatives, ideally hard negatives that are plausible but wrong).
# Retriever fine-tuning signal: (query, positive_doc, hard_negative_docs)
# mined from your production logs and corrections (Ch. 8).
{
"query": "how do I rotate my API key",
"positive": "doc#settings-security: To rotate a key, go to Settings > API Keys > Rotate...",
"hard_negatives": [
"doc#billing-keys: Your API usage is billed per key...", # mentions keys, wrong intent
"doc#sso-setup: Rotating your SSO certificate requires..." # 'rotate', wrong subject
]
}
# Why this matters: the generic embedder may rank the billing doc highly because
# it shares the word "key". Training on hard negatives teaches YOUR notion of
# relevance: intent (rotate the API key) over surface word overlap.Fine-tuning the retriever has three properties that make it attractive relative to fine-tuning the generator. It is cheap: embedding models are small, so the training is fast and the model serves cheaply. It is safe: a retriever fine-tune cannot make the generator say something wrong, at worst it returns suboptimal passages, and the generator (which you did not touch) still reasons over whatever it gets, so the blast radius is contained to retrieval quality. And it is aimed at the real bottleneck: if your "it doesn't know" failures are actually "it retrieved the wrong thing" failures, the retriever is where the fix lives, and the generator fine-tune that teams instinctively reach for would not have helped. The RAG architecture is explicitly designed so that knowledge lives in the retrievable store and the retriever's job is to find it, so when knowledge-grounded answers are failing, suspect the finder before you blame the writer.
Fine-tuning the router
The second under-considered component is the router. In any system that uses more than one model, a cheap one and an expensive one, a specialist and a generalist (Chapter 7), something decides which request goes where. That decision is a classification task: given the input, predict which path will handle it best (or which is hard enough to need the expensive model). A small fine-tuned classifier is often the ideal router: it is tiny, fast, cheap to run on every request, and it captures most of the cost savings of a multi-model system without any quality risk to the generators it routes to.
Router fine-tuning is the cleanest fine-tune in this book by the TRAIN criteria. The task is stable (the routing taxonomy changes rarely), the behavior is pure pattern (classify the input), there is no current-fact hazard (the router does not answer, it routes), the data is mineable (every past request plus which path handled it well is a training example), and the impact of a mistake is bounded (a misroute costs a re-route to the expensive model, not a wrong answer). It is the rare case where the fine-tune is almost all upside.
# A router as a small fine-tuned classifier. Trained on (input, best_path) pairs
# mined from logs: which path historically produced a good answer for this input.
def route(request: str, router_model, threshold=0.8) -> str:
pred = router_model.classify(request) # e.g. {"simple": 0.9, "complex": 0.1}
if pred["simple"] >= threshold:
return "small_specialist" # cheap path handles the easy majority
return "large_generalist" # escalate the hard/uncertain tail
# Training data: every logged request + a label for which path produced the better
# outcome (from corrections, human review, or a quality signal). The router learns
# YOUR difficulty boundary, which a generic prompt-based router approximates poorly.The router and the specialist (Chapter 7) are two halves of one design: the specialist handles the common case cheaply, the router decides what is common, and the generalist catches the tail. Fine-tuning both the router (to decide well) and a small specialist (to handle the common case well) frequently delivers the cost win of Chapter 7 with the quality safety of escalation, and notably, neither fine-tune touches the expensive generalist that handles the hard cases, so your hardest, highest-stakes requests are still served by the unmodified frontier model. You have specialized the easy path and left the hard path alone, which is exactly the risk posture you want.
The decision: which component to fine-tune
Locating the right component starts with locating the failure. Run the failure-clustering discipline from Chapter 3, but ask a system-level question of each cluster: at which stage did this request go wrong?
| Failure symptom | Likely broken component | Fine-tune target |
|---|---|---|
| Right doc exists but model answered from nothing | Retriever (didn't find it) | Embedding model on query-doc pairs |
| Right doc was retrieved but model ignored/misused it | Generator (grounding/behavior) | Generator on grounded-answer demos |
| Easy requests hit the expensive model; cost too high | Router (over-escalating) | Router classifier on (input, path) |
| Hard requests hit the cheap model and fail | Router (under-escalating) | Router classifier; raise escalation |
| Output shape/tone/format wrong with good inputs | Generator (behavior) | Generator (SFT, Ch. 5-6) |
| Answer is factually wrong despite good retrieval | Often NOT training | Fix grounding/prompt; suspect data |
The table's value is in moving the question from "fine-tune the model?" to "which component, if any, needs training, and is training the right fix for that component?" A surprising fraction of "the model is bad" complaints resolve to a retriever returning the wrong passages or a router sending requests to the wrong model, neither of which a generator fine-tune addresses, and both of which have cheaper, safer fine-tunes available. The components that fail most are not always the ones teams instinctively train.
All of these, retriever, router, generator, fine-tune with the same efficient machinery from Chapter 12: LoRA and QLoRA apply to embedding models and small classifiers as readily as to generators, and the small models that make good retrievers and routers are cheap to fully fine-tune outright. The methods are not the gate; the gate is correctly identifying which component is the bottleneck.
A note on doing the most surgery for the least change
The throughline of this chapter is targeted impact, and it returns to the book's surgical metaphor. The most skilled surgery is the smallest incision that fixes the problem. Fine-tuning the generator is the largest incision available: it changes the component with the widest blast radius (it writes the answers users see), the highest forgetting risk, and the most fact-staleness hazard. Fine-tuning the retriever or router is a smaller incision: a contained component, a bounded failure mode, a cheap and fast model, and no risk of teaching the user-facing model to say something wrong. When the failure is genuinely in the generator's behavior, train the generator, that is what Movements II and III prepared you for. But check the retriever and the router first, because the failure that feels like "the model is dumb" is, more often than teams expect, "the model never saw the right information" or "the wrong model got the request," and those are fixed upstream, with less risk, for less money. The reflex to fine-tune the generator is the same reflex this book opened with, now operating at the component level: reaching for the biggest intervention before checking whether a smaller one, on a different part of the system, is what the diagnosis actually calls for.
Chapter summary
"Fine-tune the model" almost always means the generator, which is frequently the lowest-impact and highest-risk place to train, because a production system is a pipeline, a router decides which model handles a request, a retriever finds the knowledge, and the generator writes the answer, and the failure you have may live upstream of the generator entirely. Fine-tuning the retriever (a small embedding model on query-document pairs with hard negatives, per Dense Passage Retrieval and the Sentence-BERT dual-encoder structure) is cheap, safe (it cannot make the generator say something wrong, only return better passages), and aimed at the real bottleneck when "it doesn't know" is actually "it retrieved the wrong thing." Fine-tuning the router (a tiny classifier on input→best-path pairs mined from logs) is the cleanest fine-tune in the book by TRAIN criteria: stable, pure-pattern, no fact hazard, mineable data, bounded mistakes, and pairs with a small specialist to capture cost savings while leaving the hardest requests on the unmodified generalist. Locating the right component means asking of each failure cluster "at which stage did this go wrong?": right-doc-not-found implicates the retriever, doc-found-but-misused implicates the generator, mis-escalation implicates the router, and factually-wrong-despite-good-retrieval often isn't a training problem at all. All three components use the same LoRA/QLoRA machinery, so the methods are not the gate, identifying the bottleneck is. The surgical throughline: the generator is the largest incision (widest blast radius, forgetting, fact-staleness), so check the router and retriever first, because the failure that feels like "the model is dumb" is more often "it never saw the right information" or "the wrong model got the request", fixed upstream, with less risk, for less money.