Five False Diagnoses
This chapter turns five false diagnoses into a concrete operating problem for the fine tuning or not book.

Working claim: Five sentences send more teams to the training cluster than any others, and all five are symptoms misread as diagnoses."It doesn't know." "It needs our data." "It's too verbose." "It fails sometimes." "It must be cheaper." Each one can point at a real fine-tuning case, but each one points more often at retrieval, prompting, structured outputs, routing, or evaluation. This chapter is a differential diagnosis: for each sentence, the cheaper thing it usually means, and the narrow conditions under which it really is training.
Key Takeaways
- It doesn't know usually means retrieval, not a generator fine-tune.
- It fails sometimes is unfinished triage until you cluster real failures.
- A true training case needs stable behavior, clean examples, and proof that cheaper fixes failed.
How to use a differential diagnosis
A physician confronted with chest pain does not reach for the most dramatic explanation first. They run a differential: list the things this symptom could be, order them by likelihood and by cost-of-missing, and rule out the cheap-to-treat and dangerous-to-miss before settling on the rare one. The five sentences below deserve the same treatment. The most dramatic explanation, fine-tune it, is rarely the most likely one, and treating it first is how you end up performing surgery on a patient who needed an antacid. For each sentence, we name the common cause, the test that distinguishes it from a real training case, and the narrow conditions under which training genuinely is indicated.
The OpenAI model optimization guide frames the same instinct as a sequence: optimize the prompt and context first, add retrieval if the issue is missing information, and consider fine-tuning for consistency and efficiency once you have a working approach and an eval. The five false diagnoses are five ways teams skip that sequence.
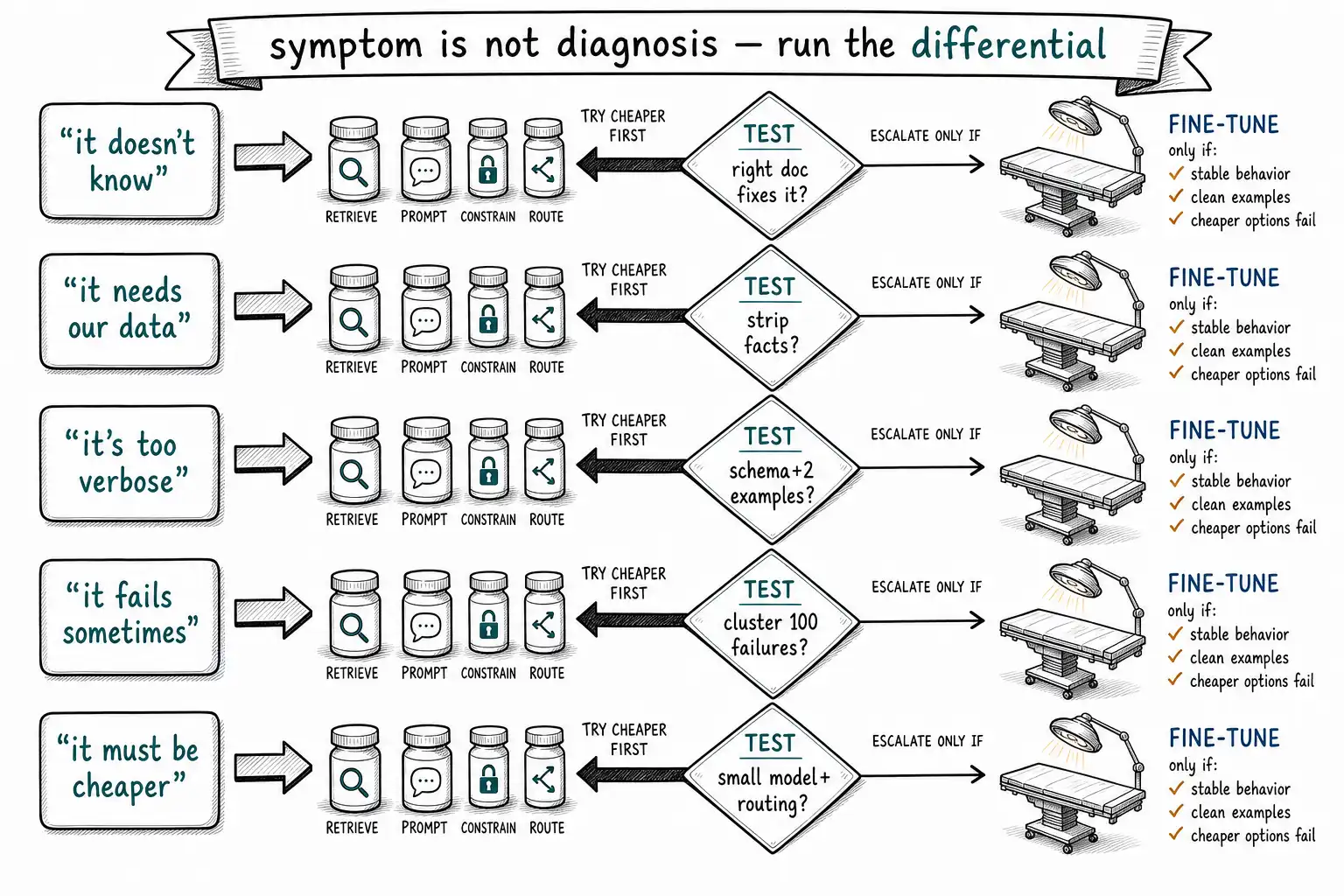
False diagnosis 1: "It doesn't know"
What they say: The model gives wrong or "I don't have information about that" answers about the company, the product, the domain. Therefore it needs to learn our knowledge, therefore fine-tune.
What it usually is: A retrieval gap. The model does not know your current facts because no model knows your current facts, they are not in any pre-training set, and they change. This is the textbook case for retrieval-augmented generation, whose entire premise is to keep knowledge in an external, updatable store and inject the relevant piece at inference time."Doesn't know" is the single most common false fine-tuning trigger, and it is almost always a knowledge problem wearing a behavior problem's clothes.
The distinguishing test: If you put the right document in the prompt, does the model answer correctly? If yes, and it almost always is yes, the model's reasoning is fine; it simply lacked the fact. That is retrieval, not training. The fact that a paragraph of context fixes it is the proof that the weights did not need changing. Per Lost in the Middle, you also have to place that context well, but placement is a context-engineering problem, not a training one.
When it really is training: When the "knowledge" is actually a skill or pattern, not a fact."It doesn't know how to write SQL in our schema's idioms" or "it doesn't know how to classify a contract clause the way our lawyers do" can be genuine fine-tuning cases, because the thing being learned is a repeatable behavior, not a lookup. The test still applies: if showing examples in the prompt fixes it permanently, you may not even need to train; if it needs many examples and the pattern is stable and high-volume, training to internalize the pattern can be worth it (Chapter 5).
False diagnosis 2: "It needs our data"
What they say: We have years of tickets / documents / transcripts. We should train on it so the model is ours.
What it usually is: A conflation of having data with needing to train on it, plus the proprietary-ownership feeling that a fine-tuned model is more "ours" than a prompted one. Most corporate data is knowledge (retrieve it) and per-request state (fetch it), with a thin layer of behavioral pattern worth training on. Having ten thousand tickets does not mean you should train on ten thousand tickets; it means you have a corpus to mine for the behavioral patterns and to index for the knowledge. The OpenAI fine-tuning best practices are explicit that you want a curated, representative dataset, not a large dump, and curating ten thousand raw tickets into clean demonstrations is most of the work (Movement III).
The distinguishing test: Strip every current fact and every per-request value out of the data. What's left? If what remains is a consistent behavior, tone, structure, decision pattern, you have a fine-tuning dataset to build. If what remains is thin or contradictory, you have an indexing project, not a training one. The support team failed this test: stripped of stale facts, their tickets did contain a real house voice (train it) but the "knowledge" everyone was excited about was exactly the stale-fact layer that should have been deleted from the training set and put in an index.
When it really is training: When the data, after stripping facts and state, contains a large, consistent, high-value behavioral pattern that prompting cannot reliably reproduce, and you can prove the trained version beats the prompted version on an eval. That is a legitimate "use our data" case, but the data you train on is a curated extract, not the raw corpus.
False diagnosis 3: "It's too verbose" (or too terse, or wrong format)
What they say: The output is the wrong shape, too long, missing required fields, prose where we need JSON, inconsistent structure. Fine-tune it to behave.
What it usually is: A prompting and structured-output problem you have not exhausted yet. Verbosity and format are behavior, so this is at least pointed at the right column, but it is pointed past three cheaper interventions. First, ask: an explicit instruction ("respond in at most three sentences," "output only the JSON object") fixes a large fraction of format complaints. Second, constrain: structured-output and function-calling features can force valid JSON against a schema at decode time, which is more reliable than hoping a fine-tune always produces valid JSON. Third, example: a few in-prompt demonstrations of the exact shape you want (few-shot) often locks in format without any training. Reaching for a fine-tune before trying these is paying surgery prices for an antacid problem.
The distinguishing test: Does a clear instruction plus a schema constraint plus two examples produce the right shape reliably? Run it on fifty inputs and count. If the format is right ~95%+ of the time, you do not need to train, you need to ship the prompt. If it is right in the demo but drifts under load, long sessions, or unusual inputs, you have a candidate for training.
When it really is training: When the format is high-volume and the prompt overhead is real, or when the structured-output constraints cannot express what you need, or when format adherence must be near-perfect and prompting plateaus below your bar. Stable format is one of fine-tuning's best use cases (Chapter 5), the point is only that you should arrive there by elimination, not reflex, because the cheaper tools fix the majority of format complaints.
False diagnosis 4: "It fails sometimes"
What they say: It mostly works, but every so often it does something wrong, a bad classification, a missed extraction, an occasional bad answer. Fine-tune it to be reliable.
What it usually is: The most dangerous false diagnosis, because "sometimes" is doing enormous unexamined work. You cannot fix a failure you have not characterized. Sometimes might mean "5% of inputs, all of them a specific edge case the prompt doesn't cover" (fix the prompt), or "on long documents where the relevant text is in the middle" (context engineering), or "when the input is in Spanish" (a coverage gap), or "randomly, no pattern" (which is often a prompt-clarity or temperature problem, not a training problem). Fine-tuning on a vague "sometimes" without characterizing the failures means you are training on noise and hoping, and if your training set does not contain the specific failing cases, the fine-tune will not fix them. It may even make them worse by overfitting to the common cases.
The distinguishing test: Collect 100 failures and cluster them. This is the single highest-impact hour in any fine-tuning decision. Almost always the failures concentrate: a few clusters account for most of them, and each cluster has a specific cause that points at a specific fix. Reasoning failures often respond to chain-of-thought prompting rather than training. Coverage failures need data (for the prompt or, yes, for a fine-tune). Format failures need constraints. The cluster analysis converts an untreatable "sometimes" into a list of treatable specifics.
When it really is training: When the failure clusters reveal a systematic behavioral gap that prompting and retrieval do not close, the model consistently mis-handles a category, you have clean examples of the right behavior for that category, and the category is stable. Then you train on those specific cases (plus enough of the working cases to avoid forgetting them)."It fails sometimes" becomes "it fails on these three clusters, and cluster two is a training case."
False diagnosis 5: "It must be cheaper"
What they say: We are spending too much per call on the large model. Fine-tune a small model to do the job for less.
What it usually is: Frequently a real and good case, but also frequently a premature one, and sometimes a misdiagnosis where the cost is coming from somewhere a fine-tune won't touch. Before training a small model, check where the cost actually is. If it is enormous prompts (long few-shot blocks, big retrieved contexts), prompt caching and retrieval trimming may cut cost more cheaply than a training project. If it is volume on a simple task, a smaller off-the-shelf model with a good prompt may already be cheap enough, try it before training. If it is a few expensive calls among many cheap ones, routing (send easy inputs to the small model, hard ones to the large model) captures most of the savings with no training at all.
The distinguishing test: Can an off-the-shelf small model with a good prompt hit your quality bar on this task? Measure it. If yes, you are done, no training needed. If the small model is close but not quite, fine-tuning it to close the gap is a strong case (this is specialization, Chapter 7). If the small model is far off and the task is genuinely hard, fine-tuning may not rescue it and you should keep the large model with routing.
When it really is training: When a small model fine-tuned on the task can match the large model's quality on your eval at a large cost-and-latency saving, and the volume justifies the training and operational overhead. This is one of the most economically compelling fine-tuning cases and we devote Chapter 7 to it. The discipline is only to confirm the cost is where you think it is and that off-the-shelf small models and routing don't already solve it.
The differential, in one table
| Sentence | Usual cause | Distinguishing test | Real training case |
|---|---|---|---|
| "It doesn't know" | Retrieval gap | Does the right doc in the prompt fix it? | The "knowledge" is a stable skill/pattern, not a fact |
| "It needs our data" | Have-data ≠ train-on-data | Strip facts/state, what behavior remains? | A large, consistent behavioral pattern remains and beats prompting on eval |
| "It's too verbose" | Unexhausted prompting/constraints | Does instruction + schema + 2 examples fix it ~95%? | High-volume format, prompting plateaus below bar |
| "It fails sometimes" | Uncharacterized failures | Cluster 100 failures, what's the pattern? | A systematic behavioral cluster with clean examples |
| "It must be cheaper" | Cost is elsewhere / off-the-shelf small works | Can a small model + good prompt + routing hit the bar? | Fine-tuned small model matches large on eval at real savings |
Notice the shape of the right-hand column: every genuine training case shares the same features, a stable, pervasive behavior (not a fact), clean examples of it, and evidence that cheaper interventions fall short. That is the TRAIN framework restated. The five false diagnoses are five ways of arriving at the operating room without having run those checks.
Chapter summary
Five sentences send teams to the training cluster, and all five are symptoms misread as diagnoses."It doesn't know" is usually a retrieval gap, the test is whether the right document in the prompt fixes it (it almost always does), and it is only training when the "knowledge" is actually a stable skill."It needs our data" conflates having data with needing to train on it, strip the facts and state, and train only if a large, consistent behavioral pattern remains and beats prompting."It's too verbose / wrong format" points at the right column (behavior) but skips three cheaper tools: instruction, structured-output constraints, and few-shot examples; train only when format is high-volume and prompting plateaus."It fails sometimes" is the most dangerous because "sometimes" hides the diagnosis, cluster 100 failures and most resolve to specific, often non-training fixes; train only on a systematic behavioral cluster with clean examples."It must be cheaper" is often a real case but check that the cost isn't coming from prompt size (cache/trim) or solvable by an off-the-shelf small model plus routing first; train when a fine-tuned small model matches the large one on your eval at real savings. Every genuine training case shares the same three features, a stable pervasive behavior, clean examples, and evidence that cheaper interventions fall short, which is the TRAIN framework, and the five false diagnoses are five ways of reaching the operating room without running those checks.