SFT, LoRA, and QLoRA in Practical Terms
> **Working claim:** You do not need the math to make the decision.

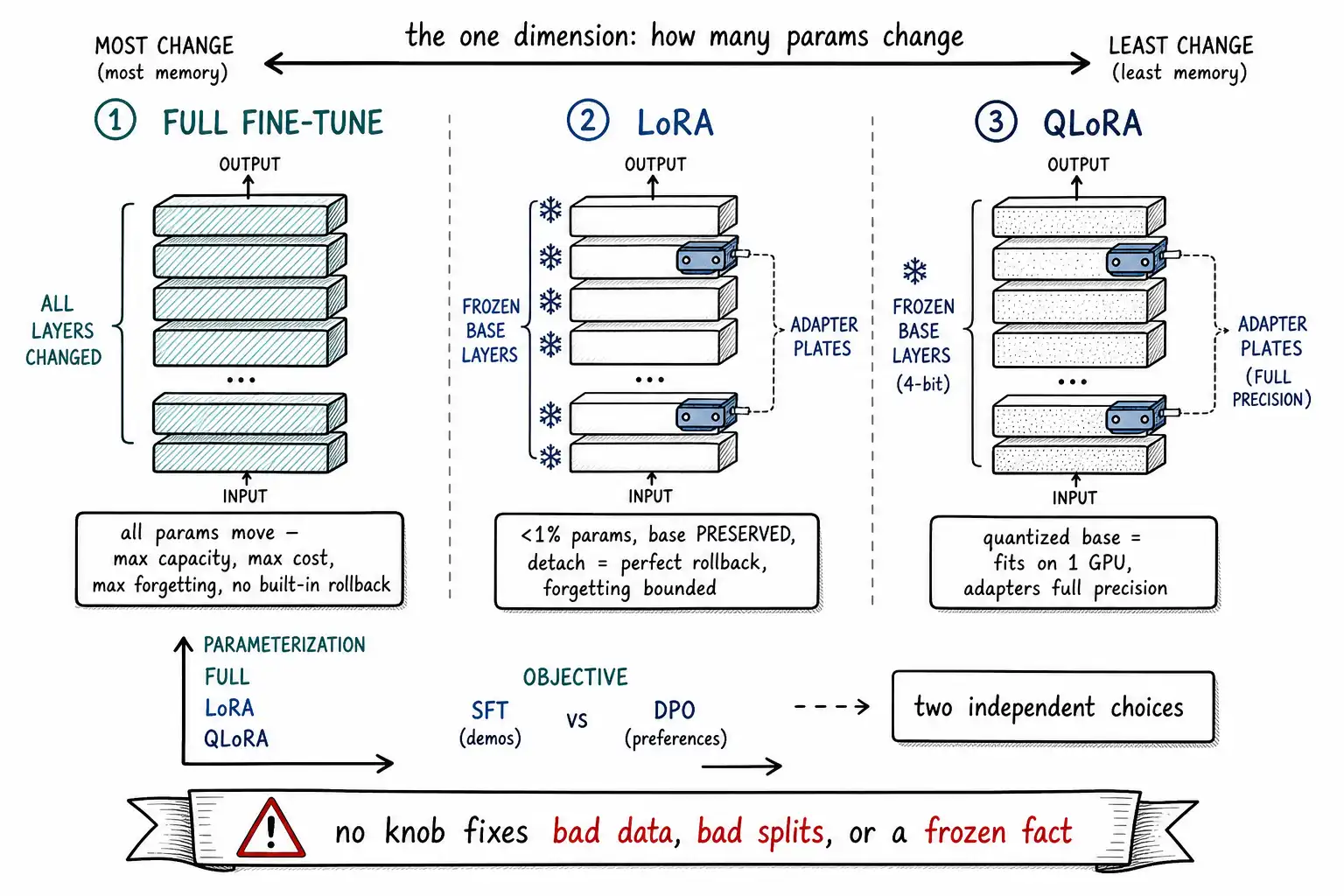
Working claim: You do not need the math to make the decision. Full fine-tuning, LoRA, and QLoRA differ in one practical dimension that matters to builders: how much of the model they change, and therefore how much it costs, how reversible it is, and how much it forgets. For almost every product fine-tune, the right default is LoRA or QLoRA, not because they are cheaper (they are) but because a frozen base is a built-in rollback and a structural defense against forgetting.
Key Takeaways
- SFT says what signal you learn from; LoRA and QLoRA say how many weights can move.
- LoRA preserves the base model and gives you a clean adapter rollback path.
- QLoRA lowers memory cost, which makes judgment and eval discipline more important, not less.
The one dimension that matters
Methods papers are full of math, and you can read them, but the decision a builder actually makes does not require it. The methods in this chapter differ along one axis with practical consequences: how many of the model's parameters does the training change? Everything you care about, cost, memory, training speed, reversibility, forgetting risk, serving complexity, follows from that one number.
- Full fine-tuning changes all the parameters. Maximum capacity to learn, maximum cost, maximum forgetting risk, no built-in rollback (the original weights are overwritten unless you saved a copy).
- LoRA freezes the base parameters entirely and adds small new ones, low-rank adapter matrices, that it trains instead. A tiny fraction of the parameters change. Lower cost, the base is preserved, forgetting is structurally limited.
- QLoRA is LoRA on a quantized (compressed) base. The base is squeezed to 4-bit so it fits in far less memory, and small adapters train on top. Lowest memory, the rest of LoRA's properties intact.
That is the whole taxonomy a builder needs. The rest of the chapter is the consequences.
Supervised fine-tuning is the what, not the how
A common confusion: people treat "SFT" and "LoRA" as alternatives. They are not on the same axis. Supervised fine-tuning describes the training objective, learning from labeled input-output demonstrations (Chapter 8), the workhorse covered by the OpenAI supervised fine-tuning guide. Full fine-tuning / LoRA / QLoRA describe the parameterization, how many weights you let the objective move. You can run SFT with full fine-tuning, with LoRA, or with QLoRA; SFT is what you are teaching, and the LoRA/QLoRA choice is how you are storing the lesson. Preference tuning (Chapter 13) is a different objective that can also be parameterized full or LoRA. Keep the two axes separate and the method space stops being confusing: pick the objective from your data (demonstrations → SFT; preferences → DPO), then pick the parameterization from your constraints (almost always LoRA/QLoRA).
How LoRA works, without the linear algebra
LoRA starts from an observation: when you fine-tune a large model on a focused task, the change to the weights is low-rank, it can be captured by far fewer numbers than the full weight matrices contain. So instead of updating the giant weight matrices directly, LoRA freezes them and learns a small pair of low-rank matrices whose product is the update. At inference the update is added to the frozen base. The trainable parameters can be well under 1% of the model, yet on many tasks the result matches full fine-tuning.
The practical consequences are what make LoRA the default, and none of them are about the cost savings everyone leads with:
- The base is preserved, exactly. Full fine-tuning overwrites the original weights; LoRA leaves them untouched and learns a separate adapter. This means you can detach the adapter and recover the original model bit-for-bit, a built-in, perfect rollback (Chapter 16). With full fine-tuning, your rollback is only as good as the checkpoint you remembered to save.
- Forgetting is structurally limited. Because the base is frozen, the general capabilities encoded in it cannot be overwritten by training; the adapter can only add a correction on top. This does not eliminate the catastrophic forgetting of Chapter 2, a strong adapter can still steer the model away from general behavior, but it bounds the damage and keeps the substrate intact, which is why LoRA fine-tunes tend to forget less than full fine-tunes at the same task quality, consistent with the mitigation theme in the forgetting study.
- Adapters are small and composable. A LoRA adapter is a small file (often megabytes), so you can store many of them, swap them per request, and serve multiple specializations from one base model in memory, a serving architecture that full fine-tuning cannot match because each full fine-tune is a whole separate model.
A minimal LoRA config makes the knobs concrete. The Hugging Face PEFT library is the standard implementation:
from peft import LoraConfig
lora_config = LoraConfig(
r=16, # rank: capacity of the adapter. Higher = more it can learn,
# more params, more forgetting risk. 8-32 is a common range.
lora_alpha=32, # scaling of the update. Often set ~2x r as a starting point.
target_modules=["q_proj", "v_proj"], # WHICH weight matrices get adapters
# (attention projections are typical; more modules = more capacity)
lora_dropout=0.05, # regularization to reduce overfitting on small datasets
bias="none",
task_type="CAUSAL_LM",)
# The only knob with a "more is better" trap is r: a high rank can overfit a small
# clean dataset and erode the base's generality. Start low; raise it only if the
# eval (Ch. 15) shows the adapter lacks capacity, never to "be safe".# A full LoRA SFT run config - the kind that belongs in version control
# next to the dataset manifest (Ch. 16), so the run is reproducible.
run:
base_model: meta-base-8b # exact base, pinned by version/hash
method: lora
objective: sft
dataset: support-triage-v4.jsonl # the curated, validated set (Ch. 9-10)
dataset_hash: sha256:9f3c... # so we know EXACTLY what trained this
adapter:
r: 16
alpha: 32
target_modules: [q_proj, v_proj, k_proj, o_proj]
dropout: 0.05
training:
epochs: 2 # FEW epochs - over-training overfits + forgets
learning_rate: 1.0e-4
batch_size: 16
eval_every_steps: 50 # watch validation loss to stop at the right point
early_stopping_patience: 3
splits:
train: support-triage-v4.train.jsonl
val: support-triage-v4.val.jsonl # never trained on (Ch. 10)
seed: 1337 # reproducibilityThe training config encodes two of the book's recurring disciplines. Few epochs: over-training drives the loss down on the training set by overfitting and forgetting, so you stop when the validation metric stops improving, not when the training loss bottoms out. Pin everything: the base model, the dataset hash, and the seed, so the run is reproducible, a fine-tune you cannot reproduce is a fine-tune you cannot debug or trust (Chapter 16).
QLoRA: the memory constraint
QLoRA makes one further move: quantize the frozen base model to 4-bit precision so it occupies a quarter of the memory, then train LoRA adapters on top of the quantized base (in higher precision, with a few engineering tricks to keep quality). The headline result is that QLoRA can fine-tune very large models on a single GPU, with quality matching 16-bit full LoRA on their evaluations. The quantization applies only to the frozen base used for the forward pass; the adapters you train stay full-precision, so you are not training a degraded model, you are training accurate adapters on a memory-efficient base.
For a builder the implication is simple and large: the GPU-budget objection to fine-tuning is gone. A specialization that used to require a cluster (Chapter 7's cost model) now runs on commodity hardware, which is exactly why this book insists on discipline, the financial guardrail that used to limit reflexive fine-tuning has been removed by QLoRA, so the limiting factor is now your judgment, your data quality, and your evaluation, not your hardware. QLoRA does not change whether you should fine-tune; it changes whether you can, and the answer is now almost always yes, which makes the should the only question left.
When to climb to full fine-tuning
If LoRA and QLoRA are the default, when is full fine-tuning worth its higher cost, irreversibility, and forgetting risk? Rarely, and the cases are specific:
| Situation | Default (LoRA/QLoRA) | Full fine-tune justified? |
|---|---|---|
| Style/format/task behavior, focused task | Yes | No, LoRA matches it at lower cost and risk |
| Need many specializations on one base | Yes, swap adapters | No, full FT means N separate models |
| Want guaranteed exact rollback | Yes, detach adapter | No, must manage checkpoints manually |
| Deep domain shift, large diverse dataset, capacity-limited by rank | Maybe insufficient | Possibly, if the eval shows LoRA can't reach the bar even at high rank |
| Continued pre-training on a new domain corpus | No | Yes, this is a different, heavier objective entirely |
The honest rule: start with LoRA/QLoRA, and climb to full fine-tuning only when an eval demonstrates that the adapter, even at increased rank and target modules, cannot reach your quality bar. That demonstration is rare for the focused product tasks this book is about. Reaching for full fine-tuning first is the same reflex this book has been arguing against, one level down: choosing the heaviest, least reversible tool before proving the lighter one falls short. The vendor-managed fine-tuning offered by API providers is, under the hood, usually a parameter-efficient method for exactly these reasons: it gives you the LoRA-style benefits (cheaper, faster, isolatable) without exposing the knobs, which is fine for many teams but trades control and portability for convenience (Chapter 16 on vendor lock-in).
A note on what the knobs cannot fix
It is worth ending on the limits of this entire chapter, because the methods are seductive, they have dials, and dials feel like control. No setting of r, alpha, learning_rate, or epochs fixes a dataset problem. If your data is contradictory (Chapter 9), no rank makes the model consistent. If your splits are contaminated (Chapter 10), no learning rate makes your eval honest. If you are training a current fact (Chapter 1), no method un-freezes it. The methods determine how efficiently the model learns whatever the data teaches; they do not determine what it learns, and they cannot rescue a fine-tune aimed at the wrong target with the wrong data. This is why the data movement came before the methods movement, and why a team that has internalized this chapter should still spend most of its fine-tuning effort on data and evaluation, not on hyperparameter tuning. The knobs are real and worth setting well, but they are the last 10% of the outcome, not the first.
Chapter summary
You do not need the math; the methods differ along one practical axis, how many parameters the training changes, and cost, memory, reversibility, and forgetting all follow from it. Full fine-tuning moves all parameters (max capacity, max cost, max forgetting, no built-in rollback); LoRA freezes the base and trains tiny low-rank adapters (< 1% of params, base preserved exactly, forgetting bounded, perfect detach-rollback, small composable adapters); QLoRA is LoRA on a 4-bit-quantized base (fits on one GPU, adapters stay full precision). SFT and LoRA are not alternatives: SFT is the objective (learn from demonstrations), while full/LoRA/QLoRA is the parameterization (how many weights move), pick the objective from your data and the parameterization from your constraints. LoRA is the default not mainly for cost but because the frozen base is a built-in rollback and a structural defense against forgetting, and adapters compose for multi-specialization serving. The config knobs (rank, alpha, target modules, epochs, learning rate) encode two disciplines, few epochs (stop on validation, not training loss) and pin everything (base, dataset hash, seed) for reproducibility, and the only "more is better" trap is rank, which overfits and erodes generality if raised without an eval reason. QLoRA removed the GPU-budget objection, which is exactly why discipline now matters more: hardware no longer limits the reflex, so judgment must. Climb to full fine-tuning only when an eval proves LoRA can't reach the bar even at higher rank, rare for focused product tasks. And no knob fixes a data, split, or wrong-target problem: the methods decide how efficiently the model learns what the data teaches, never what it learns, which is why data and evaluation deserve most of the effort.