Contamination, Leakage, and the Splits That Save You
> **Working claim:** The most common way a fine-tune lies to you is through the splits. If training and test data overlap, your eval reports a number that production will not honor, and you will ship a model you believe is good.

Working claim: The most common way a fine-tune lies to you is through the splits. If training and test data overlap, your eval reports a number that production will not honor, and you will ship a model you believe is good. Train/validation/test discipline is not bureaucracy; it is the only thing standing between a measured improvement and a measured illusion. Build the splits before you build the model.
Key Takeaways
- A contaminated split makes the eval succeed falsely, which is worse than failing loudly.
- Duplicate, entity, temporal, and pretraining leakage need different checks.
- A golden test set is the ruler; if it moves silently, the model number stops meaning anything.
The illusion machine
A fine-tune that trains on its own test data is an illusion machine. It will produce a beautiful eval number, high accuracy, low loss, a clear win over the baseline, and that number will be a lie, because the model is being graded on questions it already saw the answers to. The cruelty of the failure is that it is invisible until production: every internal signal says the model is great, the launch is approved on the strength of the eval, and then real traffic, which the model has not memorized, reveals the truth. Contamination does not make a bad model; it makes a model that looks good and isn't, which is worse, because it defeats the very mechanism you built to catch bad models.
The discipline that prevents this is old and well understood in machine learning, and it is precisely the discipline that LLM fine-tuning teams skip most often, because the modern workflow, grab some production logs, format them, train, makes it easy to never think about splits at all. The OpenAI fine-tuning best practices and the evaluation discipline in QLoRA both rest on the same foundation: a held-out set the model never trained on, used to estimate how it will perform on data it has never seen. Without that, every number you report is a training-set number, and training-set numbers are meaningless as predictions.
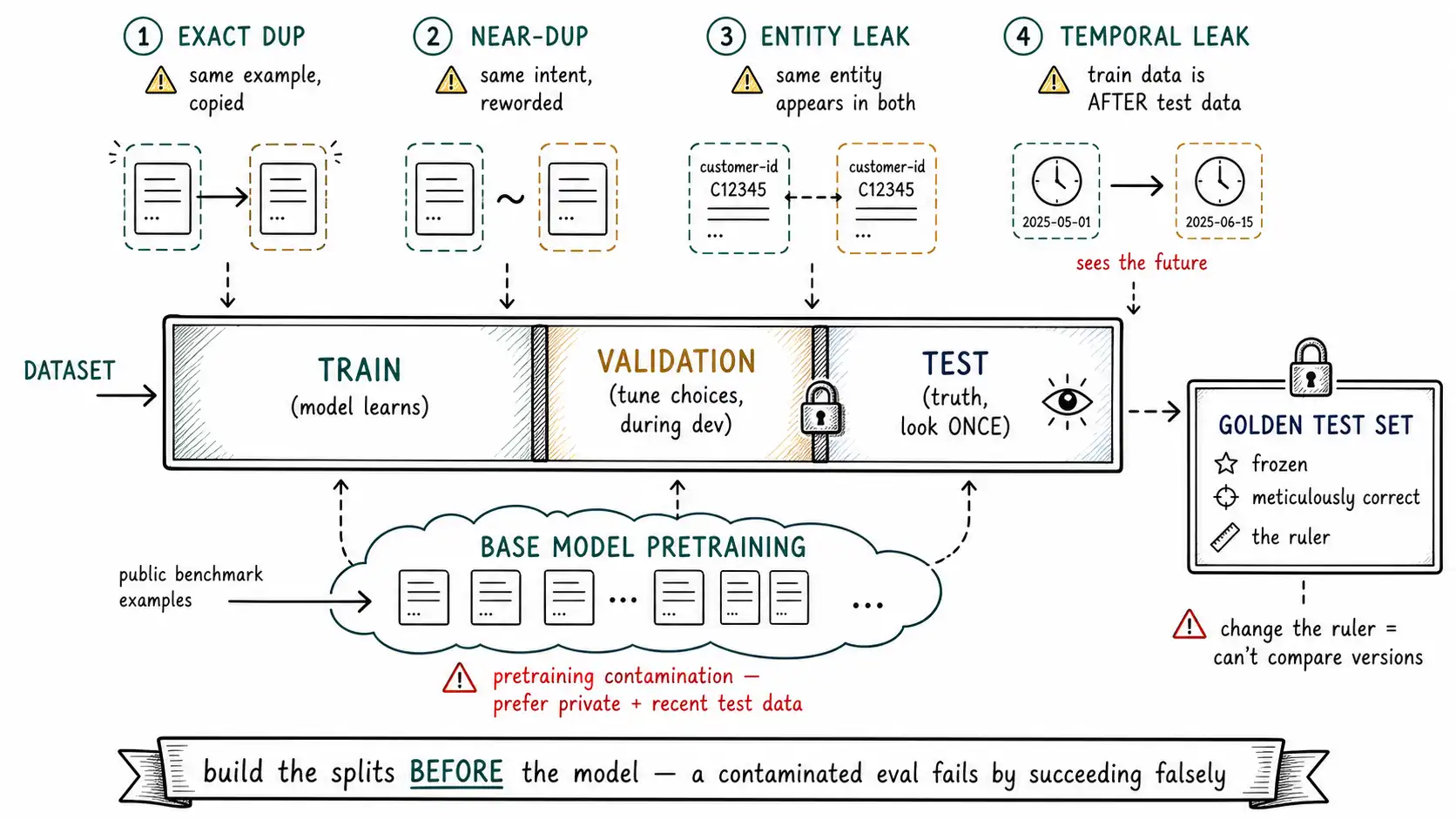
Three splits, three jobs
The three-way split is not arbitrary ceremony; each split has a distinct job, and collapsing any two of them corrupts the result.
- Training set. The data the model learns from. Its job is to shape the model.
- Validation set. Data the model does not train on, used during development to tune choices, how many epochs, which learning rate, which data mix, which checkpoint. Its job is to guide your decisions.
- Test set. Data the model never trains on and you never tune against, used once, at the end, to estimate true performance. Its job is to tell you the truth.
The subtle trap is the validation/test distinction. Teams understand "don't train on the test set," but they tune against the validation set repeatedly, try a config, check validation, adjust, check again, a dozen times, and in doing so they leak the validation set's information into their choices, optimizing the model to that specific data. By the time you have made twenty decisions guided by the validation set, your validation number is optimistic too, because you have indirectly fit to it. The test set exists to escape this: it is touched once, after all decisions are frozen, so its number is honest. If you find yourself tweaking the model after seeing the test number, you have just converted your test set into a validation set and you no longer have an honest estimate, you need a fresh held-out set. Discipline here is literally "look only once."
Contamination is sneakier than duplicate rows
Naive contamination is exact duplication: the same example in train and test. That is easy to catch, hash the inputs and check for overlap, the way the validator in Chapter 9 finds duplicates. But contamination in real fine-tuning datasets is usually subtler, and each form needs its own check.
Near-duplicates. The same case with trivial differences, a reworded ticket, the same invoice with a different date, a paraphrased question. Exact-match hashing misses these; the model effectively trained on the test case anyway. You need fuzzy matching (normalized text, n-gram overlap, or embedding similarity) across the split boundary, not just exact hashing.
Entity leakage. The same customer, document, or session appears in both train and test as different rows. If your test set has a ticket from customer 8831 and your training set has five other tickets from customer 8831, the model has learned that customer's style and history, and the "held-out" test ticket is not really held out. The fix is to split by entity, not by row: all of an entity's rows go to one split. Splitting randomly by row, when rows cluster by entity, is one of the most common silent contaminations in production fine-tuning.
Temporal leakage. You split randomly across time, so the training set contains examples from after the test examples. In any task where the world evolves, this lets the model "see the future" relative to its test cases, inflating the eval. The fix is a temporal split: train on the past, test on the future, mirroring how the model will actually be used (it will always predict on data newer than its training set). Temporal splits usually produce lower, truer numbers than random splits, which is exactly why they matter.
Pretraining contamination. The deepest form: your test examples are in the base model's pretraining data, so the base already memorized them before you fine-tuned anything. This is the contamination the Generalization or Memorization work studies, public benchmarks leak into pretraining corpora, and a model can score well by recall rather than capability. Web-scale pretraining sets like C4 are documented to contain enormous, hard-to-audit swaths of the public internet, so any test set built from public data may already be inside the base model. The mitigation is to prefer private, recent test data the base model could not have seen, and to be suspicious of suspiciously high scores on public benchmarks.
def split_contamination_report(train, test, embed_fn, near_dup_thresh=0.95):
"""Catches the contaminations exact-hashing misses."""
import numpy as np
report = {"exact": [], "near_dup": [], "entity_overlap": [], "temporal_issue": False}
train_hash = {hash_text(r["input"]): r for r in train}
for r in test: # exact
if hash_text(r["input"]) in train_hash:
report["exact"].append(r["id"])
train_emb = np.array([embed_fn(r["input"]) for r in train]) # near-dup via embeddings
for r in test:
sims = cosine_sim(embed_fn(r["input"]), train_emb)
if sims.max() >= near_dup_thresh:
report["near_dup"].append((r["id"], float(sims.max())))
train_entities = {r.get("entity_id") for r in train} # entity leakage
report["entity_overlap"] = [r["id"] for r in test
if r.get("entity_id") in train_entities]
if all("timestamp" in r for r in train + test): # temporal leakage
latest_train = max(r["timestamp"] for r in train)
earliest_test = min(r["timestamp"] for r in test)
report["temporal_issue"] = latest_train >= earliest_test # train sees the future
return reportRun this across the split boundary before training. Any non-empty exact, near_dup, or entity_overlap, or a temporal_issue of True, means your eval will lie to you, and the fix is to re-split correctly, not to proceed and hope. This report belongs in the release gate (Chapter 15) as a hard precondition: a fine-tune whose splits are contaminated cannot be evaluated, and a fine-tune that cannot be evaluated cannot be approved.
The golden test set
Beyond clean splits, mature teams maintain a golden test set: a hand-curated, stable, high-quality set of test cases that the model is never trained on, that covers the edge cases and failure clusters (Chapter 9), and that does not change between model versions, so that the number it produces is comparable across releases. The golden set is the ruler. If you change the ruler every time you change the model, you cannot tell whether the model improved or the ruler got easier, so the golden set is frozen and versioned, and changes to it are deliberate, documented events, not silent edits.
The golden set also has to be correct, which loops back to Chapter 9: Northcutt et al. showed that even famous benchmark test sets carry meaningful label-error rates, and a test set with wrong labels caps your measurable accuracy and can rank models incorrectly (a model that learned the right behavior gets penalized for disagreeing with a wrong test label). So the golden set deserves your best labeling effort, multiple reviewers, and resolution of every contested item, it is the most important data in the whole project, because it is the data that decides what "good" means. A few hundred meticulously correct golden cases are worth more than a million noisy training rows.
Why this chapter is non-negotiable
It is tempting to treat splits as a formality and rush to training. The reason not to is the asymmetry that runs through this whole book, now applied to evaluation: a contaminated eval does not fail loudly; it fails by succeeding falsely. A bad split produces a confident green light, and a confident green light gets a model shipped. Every other safeguard in this book, the regression evals of Chapter 15, the canary rollout, the monitoring, assumes the offline eval means something. If the splits are contaminated, the offline eval means nothing, and the safeguards built on top of it are guarding a number that was never real. That is why the splits come before the model: they are the foundation the entire evaluation edifice stands on, and a cracked foundation is invisible until the building is occupied.
The practical sequence, then, is: define the entity and temporal split rules first, build a frozen golden test set with your best labeling, run the contamination report across every split boundary, and only then train, knowing that whatever number comes back is a number you can believe. Skipping to training and "doing eval later" inverts the dependency and produces an evaluation you cannot trust, which is to say no evaluation at all.
Chapter summary
The most common way a fine-tune lies is through the splits: a model trained on its own test data produces a beautiful, false eval number, and the failure is invisible until production because contamination makes a model that looks good and isn't, defeating the very mechanism built to catch bad models. The three-way split gives each set a distinct job: train shapes the model, validation guides development decisions, and test tells the truth exactly once; the subtle trap is tuning repeatedly against validation (leaking it into your choices) or peeking at the test set and then adjusting (converting it into a validation set), so the rule is "look only once." Real contamination is sneakier than duplicate rows: near-duplicates (caught only by fuzzy or embedding matching), entity leakage (the same customer in both splits, fix by splitting by entity, not row), temporal leakage (training on data newer than the test cases, fix with a past/future temporal split), and pretraining contamination (test cases already memorized by the base model from web-scale corpora like C4, mitigate by preferring private, recent test data and distrusting high public-benchmark scores). A contamination report run across every split boundary belongs in the release gate as a hard precondition. Mature teams maintain a frozen, versioned, meticulously-correct golden test set as the comparable ruler across releases, its correctness matters most because wrong test labels cap measurable accuracy and misrank models. The whole edifice of later safeguards assumes the offline eval means something, so splits come before the model: define entity and temporal rules, build the golden set, run the contamination report, then train.